- Documentation (2.3.0)
- Release Notes
- Tutorials
- Reference
- Introduction
- Settings Files
- Ivy Files
- Ant Tasks
- Using standalone
- OSGi
- Developer doc
How does it work ?
Now that you have been introduced to the main ivy terminology and concepts, it is time to give some explanation of how ivy works.
Usual cycle of modules between different locations
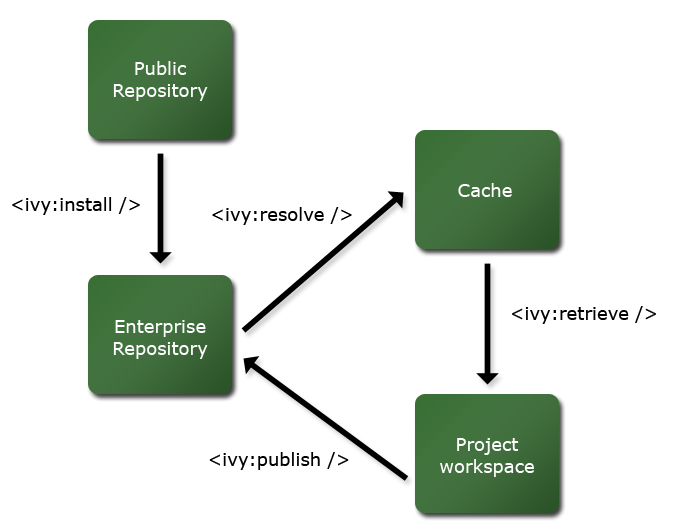
Configure
Ivy needs to be configured to be able to resolve your dependencies. This configuration is usually done with a settings file, which defines a set of dependency resolvers. Each resolver is able to find ivy files and/or artifacts, given simple information such as organisation, module, revision, artifact name, artifact type and artifact extension.The configuration is also responsible for indicating which resolver should be used to resolve which module. This configuration is dependent only on your environment, i.e. where the modules and artifacts can be found.
A default configuration is used by ivy when none is given. This configuration uses an ibiblio resolver pointing to http://repo1.maven.org/maven2/ to resolve all modules.
Resolve
The resolve time is the moment when ivy actually resolves the dependencies of one module. It first needs to access the ivy file of the module for which it resolves the dependencies.Then, for each dependency declared in this file, it asks the appropriate resolver (according to settings) to find the module (i.e. either an ivy file for it, or its artifacts if no ivy file can be found). It also uses a filesystem based cache to avoid asking for a dependency if it is already in cache (at least if possible, which is not the case with latest revisions).
If the resolver is a composite one (i.e. a chain or a dual resolver), several resolvers may actually be called to find the module.
When the dependency module has been found, its ivy file is downloaded to the ivy cache. Then ivy checks if the dependency module has dependencies, in which case it recursilvely traverses the graph of dependencies.
All over this traversal, conflict management is done to prevent access to a module as soon as possible.
When ivy has traversed the whole graph, it asks the resolvers to download the artifacts corresponding to each of the dependencies which are not already in the cache and which have not been evicted by conflict managers. All downloads are made to the ivy cache.
Finally, an xml report is generated in the cache, which allows ivy to easily know what are all the dependencies of a module, without traversing the graph again.
After this resolve step, two main steps are possible: either build a path with artifacts in the cache, or copy them to another directory structure.
Retrieve
What is called retrieve in ivy is the act of copying artifacts from the cache to another directory structure. This is done using a pattern, which indicates to ivy where the files should be copied.For this, ivy uses the xml report in the cache corresponding to the module it should retrieve to know which artifacts should be copied.
It also checks if the files are not already copied to maximize performances.
Building a path from the cache
In some cases, it is preferable to use artifacts directly from the cache. Ivy is able to use the xml report generated at resolve time to build a path of all artifacts required.This can be particularly useful when building plug-ins for IDEs.
Reports
Ivy is also able to generate readable reports describing the dependencies resolution.This is done with a simple xsl transformation of the xml report generated at resolve time.