- Documentation (2.6.0-local-20230820130639)
- Release Notes
- Tutorials
- Reference
- Introduction
- System Properties
- Settings Files
- Ivy Files
- Ant Tasks
- artifactproperty
- artifactreport
- buildlist
- buildnumber
- buildobr
- cachefileset
- cachepath
- checkdepsupdate
- cleancache
- configure
- convertmanifest
- convertpom
- deliver
- dependencytree
- findrevision
- fixdeps
- info
- install
- listmodules
- makepom
- post resolve tasks
- publish
- report
- repreport
- resolve
- resources
- retrieve
- settings
- var
- Using standalone
- OSGi
- Developer doc
Terminology
Here are some terms used in Ivy, with their definitions in Ivy:
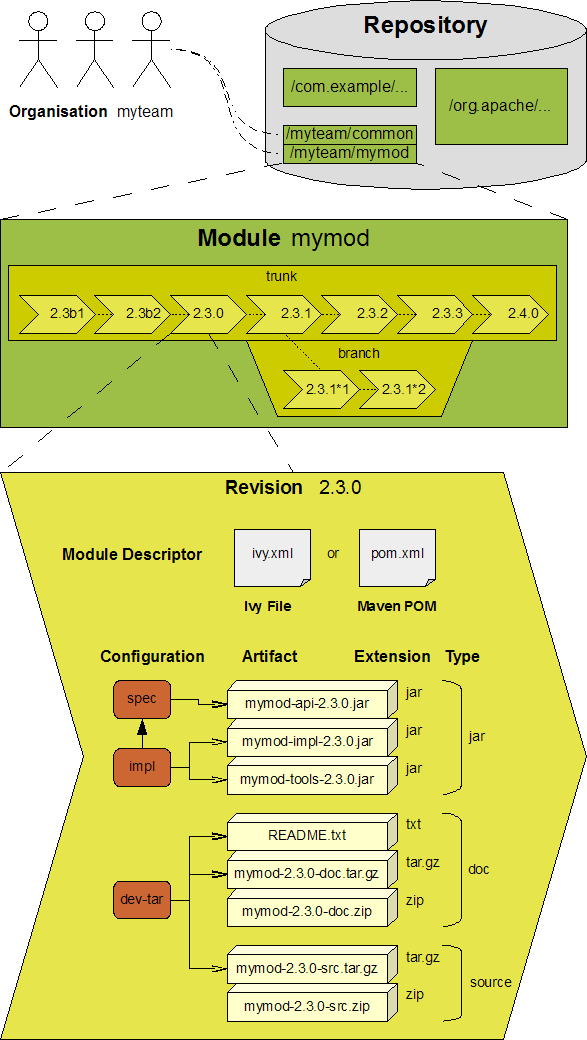
Organisation
An organisation is either a company, an individual, or simply any group of people that produces software. In principle, Ivy handles only a single level of organisation, meaning that they have a flat namespace in Ivy module descriptors. So, with Ivy descriptors, you can only describe a tree-like organisation structure, if you use a hierarchical naming convention. The organisation name is used for keeping together software produced by the same team, just to help locate their published works.
Often organisations will use their inverted domain name as their organisation name in Ivy, since domain names by definition are unique. A company whose domain name is www.example.com might want to use com.example, or if they had multiple teams, all their organisation names could begin with com.example (e.g. com.example.rd, com.example.infra, com.example.services). The organisation name does neither really have to be an inverted domain name, nor even globally unique, but unique naming is highly recommended. Widely recognized trademark or trade name owners may choose to use their brand name instead.
Examples: org.apache, ibm, jayasoft
Note that the Ivy organisation is very similar to Maven POM groupId.
Module
A module is a self-contained, reusable unit of software that, as a whole unit, follows a revision control scheme.
Ivy is only concerned about the module deliverables known as artifacts, and the module descriptor that declares them. These deliverables, for each revision of the module, are managed in repositories. In other words, to Ivy, a module is a chain of revisions each comprising a descriptor and one or more artifacts.
Examples: hibernate-entitymanager, ant
Module Descriptor
A module descriptor is a generic way of identifying what describes a module: the identifier (organisation, module name, branch and revision), the published artifacts, possible configurations and their dependencies.
The most common module descriptors in Ivy are Ivy Files, XML files with an Ivy specific syntax, and usually called ivy.xml.
But since Ivy is also compatible with Maven 2 metadata format (called POM, for Project Object Model), POM files fall into the category of module descriptors.
And because Ivy accepts pluggable module descriptor parsers, you can use almost whatever you want as module descriptors.
Artifact
An artifact is a single file ready for delivery with the publication of a module revision, as a product of development.
Compressed package formats are often preferred because they are easier to manage, transfer and store. For the same reasons, only one or a few artifacts per module are commonly used. However, artifacts can be of any file type and any number of them can be declared in a single module.
In the Java world, common artifacts are Java archives or JAR files. In many cases, each revision of a module publishes only one artifact (like jakarta-log4j-1.2.6.tar.gz, for instance), but some of them publish many artifacts depending on the use of the module (like apache-ant binary and source distributions in zip, gz and bz2 package formats, for instance).
Examples: ant-1.7.0-bin.zip, apache-ant-1.7.0-src.tar.gz
Type of an artifact
The artifact type is a category of a particular kind of artifact specimen. It is a classification based on the intended purpose of an artifact or why it is provided, not a category of packaging format or how the artifact is delivered.
Although the type of an artifact may (rather accidentally) imply its file format, they are two different concepts. The artifact file name extension is more closely associated with its format. For example, in the case of Java archives the artifact type "jar" indicates that it is indeed a Java archive as per the JAR File specification. The file name extension happens to be "jar" as well. On the other hand, with source code distributions, the artifact type may be "source" while the file name extensions vary from "tar.gz", "zip", "java", "c", or "xml" to pretty much anything. So, the type of an artifact is basically an abstract functional category to explain its purpose, while the artifact file name extension is a more concrete technical indication of its format and, of course, naming.
Defining appropriate artifact types for a module is up to its development organisation. Common choices may include: "jar", "binary", "bin", "rc", "exe", "dll", "source", "src", "config", "conf", "cfg", "doc", "api", "spec", "manual", "man", "data", "var", "resource", "res", "sql", "schema", "deploy", "install", "setup", "distrib", "distro", "distr", "dist", "bundle", etc.
Module descriptors are not really artifacts, but they are comparable to an artifact type, i.e. "descriptor" (an Ivy file or a Maven POM).
Electronic signatures or digests are not really artifacts themselves, but can be found with them in repositories. They also are comparable to an artifact type, i.e. "digest" (md5 or sha1).
Artifact file name extension
In some cases the artifact type already implies its file name extension, but not always. More generic types may include several different file formats, e.g. documentation can contain tarballs, zip packages or any common document formats.
Examples: zip, tar, tar.gz, rar, jar, war, ear, txt, doc, xml, html
Module Revision and Status
Module revision
A unique revision number or version name is assigned to each delivered unique state of a module. Ivy can help in generating revision numbers for module delivery and publishing revisions to repositories, but other aspects of revision control, especially source revisioning, must be managed with a separate version control system.
Therefore, to Ivy, a revision always corresponds to a delivered version of a module. It can be a public, shared or local delivery, a release, a milestone, or an integration build, an alpha or a beta version, a nightly build, or even a continuous build. All of them are considered revisions by Ivy.
Source revision
Source files kept under a version control system (like Subversion, CVS, SourceSafe, Perforce, etc.) have a separate revisioning scheme that is independent of the module revisions visible to Ivy. Ivy is unaware of any revisions of a module’s source files.
In some cases, the SCM’s source revision number could be used also as the module revision number, but that usage is very rare. They are still two different concepts, even if the module revision number was wholly or partially copied from the respective source revision number.
Branch
A branch corresponds to the standard meaning of a branch (or sometimes stream) in source control management tools. The head, or trunk, or main stream, is also considered as a branch in Ivy.
Status of a revision
A module’s status indicates how stable a module revision can be considered. It can be used to consolidate the status of all the dependencies of a module, to prevent the use of an integration revision of a dependency in the release of your module.
Three statuses are defined by default in Ivy:
integration-
revisions built by a continuous build, a nightly build, and so on, fall in this category
milestone-
revisions delivered to the public but not actually finished fall in this category
release-
a revision fully tested and labelled fall in this category
(since 1.4) This list is configurable in your settings file.
Configurations of a module
A module configuration is a way to use or construct a module. If the same module has different dependencies based on how it’s used, those distinct dependency-sets are called its configurations in Ivy.
Some modules may be used in different ways (think about hibernate which can be used inside or outside an application server), and this way may alter the artifacts you need (in the case of hibernate, jta.jar is needed only if it is used outside an application server). Moreover, a module may need some other modules and artifacts only at build time, and some others at runtime. All those different ways to use or build a module are called module configurations in Ivy.
For more details on configurations and how they are used in Ivy, please refer to the main concepts page.
Ivy Settings
Ivy settings files are XML files used to configure Ivy to indicate where the modules can be found and how.
History of settings
Prior to Ivy 2.0, the settings files were called configuration files and usually named ivyconf.xml. This resulted in confusion between module configurations and Ivy configuration files, so they were renamed to settings files. If you happen to fall on an ivyconf file or something called a configuration file, most of the time it’s only unupdated information (documentation, tutorial or article). Feel free to report any problem like this if you find such an inconsistency.
Repository
What is called a repository in Ivy is a distribution site location where Ivy is able to find your required modules' artifacts and descriptors (i.e. Ivy files in most cases).
Ivy can be used with complex repositories configured very finely. You can use Dependency Resolvers to do so.