Table of Contents
Ivy Release Announcement
What is Ivy?
Apache Ivy is a tool for managing (recording, tracking, resolving and reporting) project dependencies, characterized by flexibility, configurability, and tight integration with Apache Ant.
Download
You can download this release at https://ant.apache.org/ivy/download.cgi
Issues should either be discussed in the Ivy user mailing list or reported at https://issues.apache.org/jira/browse/IVY
More information about the project can be found on the website https://ant.apache.org/ivy/
Key features in this release
Key features of this 2.5.2 release are:
-
FIX: reading POMs may loose dependencies when multiple Maven dependencies only differ in
classifier(IVY-1642)
List of Changes in this Release
For details about the following changes, check our JIRA install at https://issues.apache.org/jira/browse/IVY
List of changes since Ivy 2.5.1:
Committers and Contributors
Here is the list of people who have contributed source code and documentation up to this release. Many thanks to all of them, and also to the whole IvyDE community contributing ideas and feedback, and promoting the use of Apache Ivy !
Committers:
-
Matt Benson
-
Jean-Louis Boudart
-
Maarten Coene
-
Charles Duffy
-
Gintautas Grigelionis
-
Xavier Hanin
-
Nicolas Lalevée
-
Jan Matèrne
-
Jaikiran Pai
-
Jon Schneider
-
Gilles Scokart
-
Stefan Bodewig
Contributors:
-
Ingo Adler
-
Mathieu Anquetin
-
Arseny Aprelev
-
Andreas Axelsson
-
Stéphane Bailliez
-
Karl Baum
-
Andrew Bernhagen
-
Mikkel Bjerg
-
Per Arnold Blaasmo
-
Jeffrey Blattman
-
Jasper Blues
-
Jim Bonanno
-
Joseph Boyd
-
Dave Brosius
-
Matthieu Brouillard
-
Carlton Brown
-
Mirko Bulovic
-
Ed Burcher
-
Jamie Burns
-
Wei Chen
-
Chris Chilvers
-
Kristian Cibulskis
-
Andrea Bernardo Ciddio
-
Archie Cobbs
-
Flavio Coutinho da Costa
-
Stefan De Boey
-
Mykhailo Delegan
-
Charles Duffy
-
Martin Eigenbrodt
-
Alexandr Esaulov
-
Stephen Evanchik
-
Stephan Feder
-
Robin Fernandes
-
Gregory Fernandez
-
Danno Ferrin
-
Riccardo Foschia
-
Benjamin Francisoud
-
Wolfgang Frank
-
Jacob Grydholt Jensen
-
John Gibson
-
Mitch Gitman
-
Evgeny Goldin
-
Scott Goldstein
-
Stephen Haberman
-
Aaron Hachez
-
Ben Hale
-
Peter Hayes
-
Scott Hebert
-
Payam Hekmat
-
Tobias Himstedt
-
Achim Huegen
-
Pierre Hägnestrand
-
Matt Inger
-
Anders Jacobsson
-
Anders Janmyr
-
Steve Jones
-
Christer Jonsson
-
Michael Kebe
-
Matthias Kilian
-
Alexey Kiselev
-
Gregory Kisling
-
Stepan Koltsov
-
Heschi Kreinick
-
Sebastian Krueger
-
Thomas Kurpick
-
Costin Leau
-
Ilya Leoshkevich
-
Tat Leung
-
Antoine Levy-Lambert
-
Tony Likhite
-
Andrey Lomakin
-
William Lyvers
-
Sakari Maaranen
-
Jan Materne
-
Markus M. May
-
Abel Muino
-
J. Lewis Muir
-
Stephen Nesbitt
-
Joshua Nichols
-
Bernard Niset
-
Ales Nosek
-
David Maplesden
-
Glen Marchesani
-
Phil Messenger
-
Steve Miller
-
Mathias Muller
-
Randy Nott
-
Peter Oxenham
-
Douglas Palmer
-
Thomas Pasch
-
Jesper Pedersen
-
Emmanuel Pellereau
-
Greg Perry
-
Carsten Pfeiffer
-
Yanus Poluektovich
-
Roshan Punnoose
-
Aurélien Pupier
-
Jean-Baptiste Quenot
-
Carl Quinn
-
Damon Rand
-
Geoff Reedy
-
Torkild U. Resheim
-
Christian Riege
-
Frederic Riviere
-
Jens Rohloff
-
Andreas Sahlbach
-
Brian Sanders
-
Adrian Sandor
-
Michael Scheetz
-
Ben Schmidt
-
Ruslan Shevchenko
-
John Shields
-
Nihal Sinha
-
Gene Smith
-
Michal Srb
-
Colin Stanfill
-
Simon Steiner
-
Johan Stuyts
-
John Tinetti
-
Erwin Tratar
-
Jason Trump
-
David Turner
-
Ernestas Vaiciukevičius
-
Tjeerd Verhagen
-
Willem Verstraeten
-
Richard Vowles
-
Sven Walter
-
Zhong Wang
-
James P. White
-
Tom Widmer
-
John Williams
-
Chris Wood
-
Patrick Woodworth
-
Jaroslaw Wypychowski
-
Sven Zethelius
-
Aleksey Zhukov
-
Jason A. Guild
-
Berno Langer
Ivy Tutorials
The best way to learn is to practice! That’s what the Ivy tutorials will help you to do, to discover some of the great Ivy features.
For the first tutorial you won’t even have to install Ivy (assuming you have Ant and a JDK properly installed), and it shouldn’t take more than 30 seconds.
First Tutorial
-
Make sure you have Ant 1.9.9 or greater and a Java JDK properly installed
-
Copy this build file to an empty directory on your local filesystem (and make sure you name it
build.xml) -
Open a console in that directory and run the command:
ant. That’s it!
If you have any trouble, check our FAQ.
OK, you’ve just seen how easy it is to take your first step with Ivy. Go ahead with the other tutorials, but before you do, make sure you have properly installed Ivy and downloaded the tutorials sources (included in all Ivy distributions, in the src/example directory).
List of available tutorials
The following tutorials are available:
-
Quick Start
Guides you through your very first steps with Ivy. -
Adjusting default settings
Gives you a better understanding of the default settings and shows you how to customize them to your needs. -
Multiple Resolvers
Teaches you how to configure Ivy to find its dependencies in multiple places. -
Dual Resolver
Helps you configure Ivy to find Ivy files in one place and artifacts in another. -
Project dependencies
A starting point for using Ivy in a multi-project environment. -
Using Ivy in multiple projects environment
A more complex example demonstrating the use of Ant+Ivy in a multi-project environment. -
Using Ivy Module Configurations
Shows you how to use configurations in an Ivy file to define sets of artifacts. -
Building a repository
Shows you how to build your own enterprise repository.
Ivy Quickstart
In this tutorial, you will see one of the simplest ways to use Ivy. With no specific settings, Ivy uses the Maven 2 repository to resolve the dependencies you declare in an Ivy file. Let’s have a look at the content of the files involved.
You’ll find this tutorial’s sources in the Ivy distribution in the src/example/hello-ivy directory.
The ivy.xml file
This file describes the dependencies of the project on other libraries. Here is the sample:
<ivy-module version="2.0">
<info organisation="org.apache" module="hello-ivy"/>
<dependencies>
<dependency org="commons-lang" name="commons-lang" rev="2.0"/>
<dependency org="commons-cli" name="commons-cli" rev="1.0"/>
</dependencies>
</ivy-module>The format of this file should be pretty easy to understand, but let’s discuss some details about what is declared here. First, the root element is ivy-module, with the version attribute telling Ivy which lowest version of Ivy this file is compatible with.
Then there is an info tag, which provides information about the module for which we are defining dependencies. Here we define only the organization and module names. You are free to choose whatever you want for them, but we recommend avoiding spaces for both.
Finally, the dependencies section lets you define dependencies. In this example, this module depends on two libraries: commons-lang and commons-cli. As you can see, we use the org and name attributes to define the organization and module name of the dependencies we need. The rev attribute is used to specify the version of the module you depend on.
To know what to put in these attributes, you need to know the exact information for the libraries you depend on. Ivy uses the Maven 2 central repository by default, so we recommend you use mvnrepository.com to look for the module you want. Once you find it, you will have the details of that module in the pom.xml file of that module. For instance:
<project ....>
<groupId>commons-lang</groupId>
<artifactId>commons-lang</artifactId>
<version>2.0</version>
...To convert this into an Ivy dependency declaration, all you have to do is use the groupId as organization, the artifactId as module name, and the version as revision. That’s what we did for the dependencies in this tutorial, that is commons-lang and commons-cli. Note that having commons-lang and commons-cli as organization is not the best example of what the organization should be. It would be better to use org.apache, org.apache.commons or org.apache.commons.lang. However, this is how these specific modules were identified in the Maven 2 repository, so the simplest way to get them is to use the details as is (you will see in Building a repository that you can use namespaces to redefine these names if you want something cleaner).
If you want more details on what you can do in Ivy files, you can have a look at the Ivy files reference documentation.
The build.xml file
The corresponding build file contains a set of targets, allowing you to resolve dependencies declared in the Ivy file, to compile and run the sample code, produce a report of dependency resolution, and clean the cache or the project.
You can use the standard ant -p command to get the list of available targets. Feel free to have a look at the whole file, but here is the part relevant to dependency resolution:
<project xmlns:ivy="antlib:org.apache.ivy.ant" name="hello-ivy" default="run">
...
<!-- =================================
target: resolve
================================= -->
<target name="resolve" description="--> retrieve dependencies with Ivy">
<ivy:retrieve/>
</target>
</project>As you can see, it’s very easy to call Ivy to resolve and retrieve dependencies: all you need if Ivy is properly installed is to define an XML namespace in your Ant file (xmlns:ivy="antlib:org.apache.ivy.ant"). Then all the Ivy Ant tasks will be available in this namespace.
Here we use only one task: the retrieve task. With no attributes, it will use default settings and look for a file named ivy.xml for the dependency definitions. That’s exactly what we want, so we need nothing more than that.
Note that in this case we define a resolve target and call the retrieve task. This may sound confusing, actually the retrieve task performs a resolve (which resolves dependencies and downloads them to a cache) followed by a retrieve (a copy of those file to a local project directory). Check the How does it work ? page for details about that.
Running the project
OK, now that we have seen the files involved, let’s run the sample to see what happens. Open a shell (or command line) window, and go into the hello-ivy example directory.
Then, at the command prompt, run ant:
Unresolved directive in asciidoc/tutorial/start.adoc - include::asciidoc/tutorial/log/hello-ivy-1.txt[]What happened ?
Without any settings, Ivy retrieves files from the Maven 2 repository. That’s what happened here.
The resolve task has found the commons-lang and commons-cli modules in the Maven 2 central repository, identified that commons-cli depends on commons-logging and so resolved it as a transitive dependency. Then Ivy has downloaded all corresponding artifacts in its cache (by default in your user home, in a .ivy2/cache directory). Finally, the retrieve task copies the resolved jars from the Ivy cache to the default library directory of the project: the lib dir (you can change this easily by setting the pattern attribute on the retrieve task).
You might say that the task took a long time just to write out a "Hello Ivy!" message. But remember that a lot of time was spent downloading the required files from the web. Let’s try to run it again:
Unresolved directive in asciidoc/tutorial/start.adoc - include::asciidoc/tutorial/log/hello-ivy-2.txt[]Great! The cache was used, so no download was needed and the build was instantaneous.
And now, if you want to generate a report detailing all the dependencies of your module, you can call the report target, and check the generated file in the build directory. You should obtain something looking like this.
As you can see, using Ivy to resolve dependencies stored in the Maven 2 repository is extremely easy. Now you can go on with the other tutorials to learn more about how to use module configurations which is a very powerful Ivy specific feature. More tutorials are also available where you will learn how to use Ivy settings to leverage a possibly complex enterprise repository. It may also be a good time to start reading the reference documentation, and especially the introduction material which gives a good overview of Ivy. The best practices page is also a must read to start thinking about how to use Ant+Ivy to build a clean and robust build system.
Adjusting default Ivy configurations
Ivy comes bundled with some default settings which makes it pretty simple to use in a typical environment. This tutorial, which is close to a reference document, explains what those default settings are and how they can be adjusted to your needs.
To fully understand the concept of settings and what you can do with them, we suggest reading other tutorials related to settings (like Multiple Resolvers and Dual Resolver) or the Settings Files reference documentation.
Concept
The default settings include 3 types of repositories:
-
local
A repository which is private to the user. -
shared
A repository which is shared between all the members of a team -
public
A public repository in which most modules, and especially third party modules, can be found
Note that if you work alone, the distinction between a local and shared repository is not very important, but there are some things you should know to distinguish them.
Now let’s describe each of these repository concepts in more detail. We will describe how they are set up physically later.
Local
The local repository is particularly useful when you want to do something without being disturbed by anything else happening in the environment. This means that whenever Ivy is able to locate a module in this repository it will be used, no matter what is available in others.
For instance, if you have a module declaring a dependency on the module foo with a revision of latest.integration, then if a revision of foo is found in the local repository, it will be used, even if a more recent revision is available in other repositories.
This may be disturbing for some of you, but imagine you have to implement a new feature on a project, and in order to achieve that you need to modify two modules: you add a new method in module foo and exploit this new method in module bar. Then if you publish the module foo to your local repository, you will be sure to get it in your bar module, even if someone else publishes a new revision of foo in the shared repository (this revision not having the new method you are currently adding).
But be careful, when you have finished your development and publish it on the shared repository, you will have to clean your local repository to benefit from new versions published in the shared repository.
Note also that modules found in the local repository must be complete, i.e. they must provide both a module descriptor and the published artifacts.
Shared
As its name suggest, the shared repository is aimed to be shared among the whole development team. It is a place where you can publish your team’s private modules, and it’s also a place where you can put modules not available in the public repository. You can also put modules here that are simply inaccurate in a public repository (bad or incomplete module descriptors, for instance).
Note that modules can be split across the shared repository and the public one: for example, you can have the module descriptor in the shared repository and the artifacts in the public one.
Public
The public repository is the place where most modules can be found, but which sometimes lack the information you need. It’s usually a repository available through an Internet connection only, even if this is not mandatory.
Setting up the repositories
Now that we have seen the objective of each of the three repositories, let’s see how they are set up and how to configure them to fit your needs.
First, several repositories use the same root in your filesystem. Referenced as ${ivy.default.ivy.user.dir}, this is by default the directory .ivy2 in your user home.
Note that several things can be done by setting Ivy variables. To set them without defining your own ivysettings.xml file, you can:
-
set an Ant property before any call to Ivy in your build file if you use Ivy from Ant
-
set an environment variable if you use Ivy from the command line
For example:
<target name="resolve">
<property name="ivy.default.ivy.user.dir" value="/path/to/ivy/user/dir"/>
<ivy:resolve/>
</target>Next we will show you how to override default values for the different kinds of repositories. Note that you can find what the default values are below in the details of the default settings.
Local
By default, the local repository lies in ${ivy.default.ivy.user.dir}/local. This is usually a good place, but you may want to modify it. No problem, you just have to set the ivy.local.default.root Ivy variable to the directory you want to use:
For example:
ivy.local.default.root=/opt/ivy/repository/localIf you already have something you would like to use as your local repository, you may also want to modify the layout of this repository. Once again, two variables are available for that:
-
ivy.local.default.ivy.patternwhich gives the pattern to find Ivy module descriptor files -
ivy.local.default.artifact.patternwhich gives the pattern to find the artifacts
For example:
ivy.local.default.root=/opt/ivy/repository/local
ivy.local.default.ivy.pattern=[module]/[revision]/ivy.xml
ivy.local.default.artifact.pattern=[module]/[revision]/[artifact].[ext]Shared
By default, the shared repository lies in ${ivy.default.ivy.user.dir}/shared. This is fine if you work alone, but the shared repository is supposed to be, mmm, shared! So changing this directory is often required, and it is usually modified to point to a network shared directory. You can use the ivy.shared.default.root variable to specify a different directory. Moreover, you can also configure the layout with variables similar to the ones used for the local repository:
-
ivy.shared.default.ivy.patternwhich gives the pattern to find Ivy module descriptor files -
ivy.shared.default.artifact.patternwhich gives the pattern to find the artifacts
For example:
ivy.shared.default.root=/opt/ivy/repository/shared
ivy.shared.default.ivy.pattern=[organisation]/[module]/[revision]/ivy.xml
ivy.shared.default.artifact.pattern=[organisation]/[module]/[revision]/[artifact].[ext]Public
By default, the public repository is ibiblio in m2 compatible mode (in other words, the Maven 2 public repository).
This repository has the advantage of providing a lot of modules, with metadata for most of them. The quality of metadata is not always perfect, but it’s a very good start to use a tool like Ivy and benefit from the power of transitive dependency management.
Despite its ease of use, we suggest reading the Best practices to have a good understanding of the pros and cons of using a public unmanaged repository before depending on such a repository for your enterprise build system.
|
Note
|
In 1.4 version, Ivy was using ivyrep as the default resolver, if you want to restore this, set ivy.14.compatible=true as an Ant property
|
Going further
OK, so we have seen how to easily change the settings of the three main repositories. But what if my shared repository is on a web server? What if you don’t want to use Maven 2 repository as the public repository? What if …
No problem, Ivy is very flexible and can be configured with specific settings to match your needs and environment. But before considering writing your own settings from scratch, we suggest reading the following where you will learn how to leverage a part of the default settings and adjust the rest.
But before explaining how, you will need to have a quick overview of how Ivy is configured by default.
By default, Ivy is configured using an ivysettings.xml which is packaged in the Ivy jar. Here is this settings file:
<ivysettings>
<settings defaultResolver="default"/>
<include url="${ivy.default.settings.dir}/ivysettings-public.xml"/>
<include url="${ivy.default.settings.dir}/ivysettings-shared.xml"/>
<include url="${ivy.default.settings.dir}/ivysettings-local.xml"/>
<include url="${ivy.default.settings.dir}/ivysettings-main-chain.xml"/>
<include url="${ivy.default.settings.dir}/ivysettings-default-chain.xml"/>
</ivysettings>OK, so not much info here, except a lot of inclusions. These inclusions have been done on purpose so that you can easily change only one part of the Ivy settings and easily benefit from the rest. For example, if you want to define your own public resolver, you will just have to configure Ivy with the settings like the following:
<ivysettings>
<settings defaultResolver="default"/>
<include url="http://myserver/ivy/myivysettings-public.xml"/>
<include url="${ivy.default.settings.dir}/ivysettings-shared.xml"/>
<include url="${ivy.default.settings.dir}/ivysettings-local.xml"/>
<include url="${ivy.default.settings.dir}/ivysettings-main-chain.xml"/>
<include url="${ivy.default.settings.dir}/ivysettings-default-chain.xml"/>
</ivysettings>Note that only the ivysettings-public.xml inclusion has changed to include a homemade public resolver. Note also that this can be used like that thanks to the fact that ${ivy.default.settings.dir} is a variable which is always set to the place where Ivy’s default settings files are (i.e. packaged in the jar).
To finish this example, you have to write your own Ivy settings file (that you will make available at http://myserver/ivy/myivysettings-public.xml in this example) for defining your own public resolver. For instance, the contents of such a file could be:
<ivysettings>
<resolvers>
<filesystem name="public">
<ivy pattern="/path/to/my/public/rep/[organisation]/[module]/ivy-[revision].xml"/>
<artifact pattern="/path/to/my/public/rep/[organisation]/[module]/[artifact]-[revision].[ext]"/>
</filesystem>
</resolvers>
</ivysettings>Now the last thing you will need in order to properly take advantage of the default settings is the content of each included Ivy settings file:
<ivysettings>
<resolvers>
<ibiblio name="public" m2compatible="true"/>
</resolvers>
</ivysettings><ivysettings>
<property name="ivy.shared.default.root" value="${ivy.default.ivy.user.dir}/shared" override="false"/>
<property name="ivy.shared.default.ivy.pattern" value="[organisation]/[module]/[revision]/[type]s/[artifact].[ext]" override="false"/>
<property name="ivy.shared.default.artifact.pattern" value="[organisation]/[module]/[revision]/[type]s/[artifact].[ext]" override="false"/>
<resolvers>
<filesystem name="shared">
<ivy pattern="${ivy.shared.default.root}/${ivy.shared.default.ivy.pattern}"/>
<artifact pattern="${ivy.shared.default.root}/${ivy.shared.default.artifact.pattern}"/>
</filesystem>
</resolvers>
</ivysettings><ivysettings>
<property name="ivy.local.default.root" value="${ivy.default.ivy.user.dir}/local" override="false"/>
<property name="ivy.local.default.ivy.pattern" value="[organisation]/[module]/[revision]/[type]s/[artifact].[ext]" override="false"/>
<property name="ivy.local.default.artifact.pattern" value="[organisation]/[module]/[revision]/[type]s/[artifact].[ext]" override="false"/>
<resolvers>
<filesystem name="local">
<ivy pattern="${ivy.local.default.root}/${ivy.local.default.ivy.pattern}"/>
<artifact pattern="${ivy.local.default.root}/${ivy.local.default.artifact.pattern}"/>
</filesystem>
</resolvers>
</ivysettings><ivysettings>
<resolvers>
<chain name="main" dual="true">
<resolver ref="shared"/>
<resolver ref="public"/>
</chain>
</resolvers>
</ivysettings><ivysettings>
<resolvers>
<chain name="default" returnFirst="true">
<resolver ref="local"/>
<resolver ref="main"/>
</chain>
</resolvers>
</ivysettings>There you go, you should have enough clues to configure Ivy the way you want. Check the settings documentation to see if what you want to do is possible, and go ahead!
Multiple Resolvers
This tutorial is an example of how modules can be retrieved by multiple resolvers. Using multiple resolvers can be useful in many contexts. For example:
-
separating integration builds from releases
-
using a public repository for third party modules and a private one for internal modules
-
use a repository for storing modules which are not accurate in an unmanaged public repository
-
use a local repository to expose builds made on one developer’s station
In Ivy, the use of multiple resolvers is supported by a compound resolver called the chain resolver.
In our example, we will simply show you how to use two resolvers, one for a local repository and one using the Maven 2 repository.
Project Description
The project: chained-resolvers
The project is very simple and contains only one simple class: example.Hello.
It depends on two libraries: Apache’s commons-lang and a custom library named test (sources are included in test-1.0.jar file). The test library is used by the project to uppercase a string, and commons-lang is used to capitalize the same string.
Here is the content of the project:
-
build.xml: the Ant build file for the project
-
ivy.xml: the Ivy project file
-
src/example/Hello.java: the only class of the project
Let’s have a look at the ivy.xml file:
Unresolved directive in asciidoc/tutorial/multiple.adoc - include::src/example/chained-resolvers/chainedresolvers-project/ivy.xml[]As we’d expect, the Ivy file declares this module to be dependent on the two libraries it uses: commons-lang and test. Note that we didn’t specify the org for the dependency test. When we exclude org, Ivy assumes it is in the same org as the declaring module. (in this example, it’s org.apache).
The Ivy Settings
The settings are defined in the ivysettings.xml file located in the settings directory of the project. Below are its contents, followed by an explanation of what it’s doing.
Unresolved directive in asciidoc/tutorial/multiple.adoc - include::src/example/chained-resolvers/settings/ivysettings.xml[]The settings tag
This tag initializes Ivy with some parameters. Here only one parameter is set, the name of the resolver to use by default.
The resolvers tag
The resolvers section defines the list of resolvers that Ivy will use to locate artifacts. In our example, we have only one resolver named chain-example, which is unique in that it defines a list (hence a chain) of resolvers.
The resolvers in this chain are:
-
libraries: It is a filesystem resolver, so looks at a directory structure to retrieve the artifacts. This one is configured to look in therepositorysub directory of the directory that contains theivysettings.xmlfile. -
ibiblio: It looks in the ibiblio Maven repository to retrieve the artifacts.
That’s it, we have just configured a chain of resolvers!
Walkthrough
Step 1: Preparation
Open a shell (or command line) window, and go to the src/example/chained-resolvers directory.
Step 2: clean directory tree
On the prompt type: ant
This will clean up the entire project directory tree and Ivy cache. You can do this each time you want to clean up this example.
|
Note
|
In almost all examples, we provide a Cleaning the Ivy cache is something you can do without fear (except for performance): it’s only a cache, so everything can be (and should be) obtained again from repositories. This may sound strange to those coming from Maven 2 land. But remember that in Ivy, the cache is not a local repository and the two are completely isolated. |
Step 3: run the project
Go to chained-resolvers project directory. And simply run ant.
Unresolved directive in asciidoc/tutorial/multiple.adoc - include::asciidoc/tutorial/log/chained-resolvers.txt[]We can see in the log of the resolve task, that the two dependencies have been retrieved (2 artifacts) and copied to the Ivy cache directory (2 downloaded).
Also notice that the run Ant target succeeded in using both commons-lang.jar coming from the ibiblio repository and test.jar coming from the local repository.
Going further
This very simple example helps us see how to set up two resolvers in a chain. The chain resolver’s reference documentation is available for those who would like to know all the features offered by this resolver.
Below are a few more interesting things worth knowing about chain resolvers. After reading them, go ahead and try tweaking this example using your new wealth of knowledge!
-
a chain is not limited to two nested resolvers, you can use as many as you want
-
by setting
returnFirst="true", you can have a chain which stops as soon as it has found a result for a given module -
by setting
dual="true", the full chain will be used both for module descriptors and artifacts, while settingdual="false", the resolver in the chain which found the module descriptor (if any) is also used for artifacts
Dual Resolver
In some cases, your module descriptions (i.e. Ivy files, Maven POMs) are located separately from the module artifacts (i.e. jars). So what can you do about it?
Use a Dual resolver! And this tutorial will show you how.
Project description
Let’s have a look at the src/example/dual directory in your Ivy distribution.
It contains a build file and 3 directories:
-
settings: contains the Ivy settings file
-
repository: a sample repository of Ivy files
-
project: the project making use of Ivy with dual resolver
The dual project
The project is very simple and contains only one simple class: example.HelloIvy
It depends on two libraries: Apache commons-lang and Apache commons-httpclient.
Here is the content of the project:
-
build.xml: the Ant build file for the project
-
ivy.xml: the Ivy project file
-
src/example/HelloIvy.java: the only class of the project
Let’s have a look at the ivy.xml file:
<ivy-module version="1.0">
<info organisation="org.apache" module="hello-ivy"/>
<dependencies>
<dependency org="commons-httpclient" name="commons-httpclient" rev="2.0.2"/>
<dependency org="commons-lang" name="commons-lang" rev="2.6"/>
</dependencies>
</ivy-module>As you can see, nothing special here… Indeed, Ivy’s philosophy is to keep Ivy files independent of the way dependencies are resolved.
The Ivy settings
The Ivy settings are defined in the ivysettings.xml file located in the settings directory. Here is what it contains, followed by an explanation.
<ivysettings>
<settings defaultResolver="dual-example"/>
<resolvers>
<dual name="dual-example">
<filesystem name="ivys">
<ivy pattern="${ivy.settings.dir}/../repository/[module]-ivy-[revision].xml"/>
</filesystem>
<ibiblio name="ibiblio" m2compatible="true" usepoms="false"/>
</dual>
</resolvers>
</ivysettings>Here we configured one resolver, the default one, which is a dual resolver. This dual resolver has two sub resolvers: the first is what is called the "ivy" or "metadata" resolver of the dual resolver, and the second one is what is called the "artifact" resolver. It is important that the dual resolver has exactly two sub resolvers in this given order.
The metadata resolver, here a filesystem one, is used only to find module descriptors, in this case Ivy files. The setting shown here tells Ivy that all Ivy files are in the repository directory, named according to the pattern: [module]-ivy-[revision].xml. If we check the repository directory, we can confirm that it contains a file named commons-httpclient-ivy-2.0.2.xml. This file matches the pattern, so it will be found by the resolver.
The artifact resolver is simply an ibiblio one, configured in m2compatible mode to use the Maven 2 repository, with usepoms="false" to make sure it won’t use Maven 2 metadata. Note that this isn’t necessary, since the second resolver in a dual resolver (the artifact resolver) is never asked to find module metadata.
Walkthrough
Step 1 : Preparation
Open a shell (or command line) window, and go to the dual directory.
Step 2 : Clean up
On the prompt type : ant
This will clean up the entire project directory tree (compiled classes and retrieved libs) and the Ivy cache. You can run this each time you want to clean up this example.
Step 3 : Run the project
Go to the project directory. And simply run ant.
Unresolved directive in asciidoc/tutorial/dual.adoc - include::asciidoc/tutorial/log/dual.txt[]As you can see, Ivy not only downloaded commons-lang and commons-httpclient, but also commons-logging. Indeed, commons-logging is a dependency of httpclient, as we can see in the httpclient Ivy file found in the repository directory:
<ivy-module version="1.0">
<info
organisation="commons-httpclient"
module="commons-httpclient"
revision="2.0.2"
status="release"
publication="20041010174300"/>
<dependencies>
<dependency org="commons-logging" name="commons-logging" rev="1.0.4" conf="default"/>
</dependencies>
</ivy-module>So everything seemed to work. The Ivy file was found in the repository directory and the artifacts have been downloaded from ibiblio.
This kind of setup can be useful if you don’t want to rely on the Maven 2 repository for metadata, or if you want to take full advantage of Ivy files for some or all modules. Combining chain and dual resolvers should give you enough flexibility to meet almost any requirement.
For full details about the dual resolver, have a look at the corresponding reference documentation.
Project dependencies
This tutorial will show you how to use Ivy when one of your projects depends on another.
For our example, we will have two projects, depender and dependee, where the depender project uses/requires the dependee project. This example will help illustrate two things about Ivy:
-
that dependencies defined by parent projects (dependee) will automatically be retrieved for use by child projects (depender)
-
that child projects can retrieve the "latest" version of the dependee project
Projects used
dependee
The dependee project is very simple. It depends on the Apache library commons-lang and contains only one class: standalone.Main which provides two services:
-
return the version of the project
-
capitalize a string using
org.apache.commons.lang.WordUtils.capitalizeFully
Here is the content of the project:
-
build.xml: the Ant build file for the project
-
ivy.xml: the project Ivy file
-
src/standalone/Main.java: the only class of the project
Take a look at the ivy.xml file:
<ivy-module version="1.0">
<info organisation="org.apache" module="dependee"/>
<dependencies>
<dependency org="commons-lang" name="commons-lang" rev="2.0"/>
</dependencies>
</ivy-module>The Ivy file declares only one dependency, that being the Apache commons-lang library.
depender
The depender project is very simple as well. It declares only one dependency on the latest version of the dependee project, and it contains only one class, depending.Main, which does 2 things:
-
gets the version of the standalone project by calling
standalone.Main.getVersion() -
transforms a string by calling
standalone.Main.capitalizeWords(str)
Take a look at the ivy.xml file:
<ivy-module version="1.0">
<info organisation="org.apache" module="depender"/>
<dependencies>
<dependency name="dependee" rev="latest.integration"/>
</dependencies>
</ivy-module>Settings
The Ivy settings are defined in two files located in the settings directory:
-
ivysettings.properties: a property file -
ivysettings.xml: the file containing the settings
Let’s have a look at the ivysettings.xml file:
<ivysettings>
<properties file="${ivy.settings.dir}/ivysettings.properties"/>
<settings defaultResolver="libraries"/>
<caches defaultCacheDir="${ivy.settings.dir}/ivy-cache"/>
<resolvers>
<filesystem name="projects">
<artifact pattern="${repository.dir}/[artifact]-[revision].[ext]"/>
<ivy pattern="${repository.dir}/[module]-[revision].xml"/>
</filesystem>
<ibiblio name="libraries" m2compatible="true" usepoms="false"/>
</resolvers>
<modules>
<module organisation="org.apache" name="dependee" resolver="projects"/>
</modules>
</ivysettings>The file contains four main tags: properties, settings, resolvers and modules.
properties
This tag loads some properties for the Ivy process, just like Ant does.
settings
This tag initializes some parameters for the Ivy process. In this case, the directory that Ivy will use to cache artifacts will be in a sub directory called ivy-cache of the directory containing the ivysettings.xml file itself.
The second parameter, tells Ivy to use a resolver named "libraries" as its default resolver. More information can be found in the settings reference documentation.
resolvers
This tag defines the resolvers to use. Here we have two resolvers defined: "projects" and "libraries". The filesystem resolver called "projects" is able to resolve the internal dependencies by locating them on the local filesystem. The ibiblio resolver called "libraries" is able to find dependencies on the Maven 2 repository, but doesn’t use Maven POMs.
modules
The modules tag allows you to configure which resolver should be used for which module. Here the setting tells Ivy to use the "projects" resolver for all modules having an organisation of org.apache and module name of dependee. This actually corresponds to only one module, but a regular expression could be used, or many other types of expressions (like glob expressions).
All other modules (i.e. all modules but org.apache#dependee), will use the default resolver ("libraries").
Walkthrough
Step 1: Preparation
Open a shell (or command line) window, and go to the src/example/dependence directory.
Step 2: Clean directory tree
At the prompt, type: ant
This will clean up the entire project directory tree. You can do this each time you want to clean up this example.
Step 3: Publication of dependee project
Go to dependee directory and publish the project
Unresolved directive in asciidoc/tutorial/dependence.adoc - include::asciidoc/tutorial/log/dependence-standalone.txt[]What we see here:
-
the project depends on 1 library (1 artifact)
-
the library was not in the Ivy cache and so was downloaded (1 downloaded)
-
the project has been released under version number 1
As you can see, the call to the publish task has resulted in two main things:
-
the delivery of a resolved Ivy file to
build/ivy.xml.
This has been done because by default, the publish task not only publishes artifacts, but also its Ivy file. So it has looked to the path where the Ivy file to publish should be, using the artifactspattern:${build.dir}/[artifact].[ext]. For an Ivy file, this resolves tobuild/ivy.xml. Because this file does not exist, it automatically makes a call to the deliver task which delivers a resolved Ivy file to this destination. -
the publication of artifact 'dependee' and its resolved Ivy file to the repository.
Both are just copies of the files found in the current project, or more precisely, those in thebuilddirectory. This is because the artifactspattern has been set to${build.dir}/[artifact].[ext], so the dependee artifact is found atbuild/dependee.jarand the Ivy file inbuild/ivy.xml. And because we have asked the publish task to publish them using the "projects" resolver, these files are copied torepository/dependee-1.jarand torepository/dependee-1.xml, respecting the artifact and Ivy file patterns of our settings (see above).
Step 4: Running the depender project
Go to directory depender and run ant
Unresolved directive in asciidoc/tutorial/dependence.adoc - include::asciidoc/tutorial/log/dependence-depending.txt[]What we see here:
-
the project depends on 2 libraries (2 artifacts)
-
one of the libraries was in the cache because there was only 1 download (1 downloaded)
-
Ivy retrieved version 1 of the project "dependee". The call to
standalone.Main.getVersion()has returned 1. If you look in thedepender/libdirectory, you should seedependee-1.jarwhich is the version 1 artifact of the project "dependee" -
the call to
standalone.Main.capitalizeWords(str)succeed, which means that the required library was in the classpath. If you look at thelibdirectory, you will see that the librarycommons-lang-2.0.jarwas also retrieved. This library was declared as a dependency of the "dependee" project, so Ivy retrieves it (transitively) along with the dependee artifact.
Step 5: New version of dependee project
Like we did before in step 3, publish the dependee project again. This will result in a new version of the project being published.
Unresolved directive in asciidoc/tutorial/dependence.adoc - include::asciidoc/tutorial/log/dependence-standalone-2.txt[]Now if you look in your repository folder, you will find 2 versions of the dependee project. Let’s look at it:
I:\dependee>dir ..\settings\repository /w
[.] [..] dependee-1.jar dependee-1.xml dependee-2.jar dependee-2.xml
I:\dependee>OK, now our repository contains two versions of the project dependee, so other projects can refer to either version.
Step 6: Get the new version in depender project
What should we expect if we run the depender project again? It should:
-
retrieve version 2 as the latest.integration version of the dependee project
-
display version 2 of dependee project
Let’s try it!!
Unresolved directive in asciidoc/tutorial/dependence.adoc - include::asciidoc/tutorial/log/dependence-depending-2.txt[]OK, we got what we expected as the run target shows that we are using version 2 of the main class of the dependee project. If we take a look at the resolve target results, we see that one artifact has been downloaded to the Ivy cache. In fact, this file is the same version 2 of the dependee project that is in the repository, but now all future retrievals will pull it from your ivy-cache directory.
Using Ivy in multiple projects environment
In the previous tutorial, you saw how to deal with dependencies between two simple projects.
This tutorial will guide you through the use of Ivy in a more complex environment. All of the code for this tutorial is available in the src/example/multi-project directory of the Ivy distribution.
Context
Here is a 10000 ft overview of the projects involved in this tutorial:
-
version
helps to identify module by a version -
list
gives a list of files in a directory (recursively) -
size
gives the total size of all files in a directory, or of a collection of files -
find
find files in a given dir or among a list of files which match a given name -
sizewhere
gives the total size of files matching a name in a directory -
console
give access to all other modules features through a simple console app
For sure this is not aimed to demonstrate how to develop a complex app or give indication of advanced algorithm :-)
But this gives a simple understanding of how Ant+Ivy can be used to develop an application divided in multiple modules.
Now, here is how these modules relate to each other:
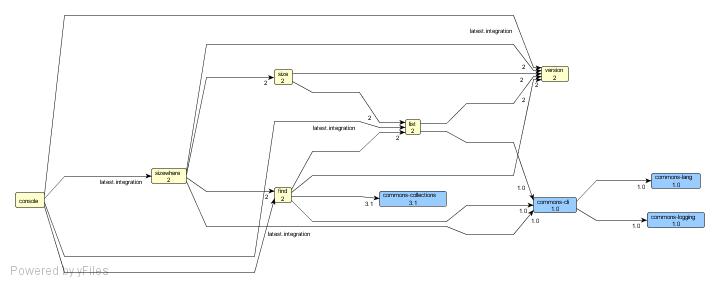
Modules in yellow are the modules described in this tutorial, and modules in blue are external dependencies (we will see how to generate this graph later in this tutorial).
As you can see, we have here a pretty interesting set of modules with dependencies between each other, each depending on the latest version of the others.
The example files
The sources for this tutorial can be found in src/example/multi-project in the Ivy distribution. In this directory, you will find the following files:
-
build.xml
This is a root build file which can be used to call targets on all modules, in the order of their dependencies (ensuring that a module is always built before any module depending on it, for instance) -
common
-
common.xml the common build file imported by all build.xml files for each project. This build defines the targets which can be used in all projects.
-
build.properties some properties common to all projects
-
-
projects
contains a directory per module, with each containing:-
ivy.xml
Ivy file of the module, describing its dependencies upon other modules and/or external modules. Example:
-
<ivy-module version="1.0">
<info
organisation="org.apache.ivy.example"
module="find"
status="integration"/>
<configurations>
<conf name="core"/>
<conf name="standalone" extends="core"/>
</configurations>
<publications>
<artifact name="find" type="jar" conf="core"/>
</publications>
<dependencies>
<dependency name="version" rev="latest.integration" conf="core->default"/>
<dependency name="list" rev="latest.integration" conf="core"/>
<dependency org="commons-collections" name="commons-collections" rev="3.1" conf="core->default"/>
<dependency org="commons-cli" name="commons-cli" rev="1.0" conf="standalone->default"/>
</dependencies>
</ivy-module>-
build.xml
The build file of the project, which consists mainly of an import of the common build file and of a module specific properties file:
<project name="find" default="compile">
<property file="build.properties"/>
<import file="${common.dir}/common.xml"/>
</project>-
build.properties
Module specific properties + properties to find the common build file
projects.dir = ${basedir}/..
wkspace.dir = ${projects.dir}/..
common.dir = ${wkspace.dir}/common-
src
the source directory with all Java sources
Note that this example doesn’t demonstrate many good practices for software development in general, in particular you won’t find any unit test in these samples, even if we think unit testing is very important. But this isn’t the aim of this tutorial.
Now that you are a bit more familiar with the structure, let’s have a look at the most important part of this example: the common build file. Indeed, as you have seen, all the module’s build files only import the common build file, and define their dependencies in their Ivy files (which you should begin to be familiar with).
So, here are some aspects of this common build file:
Ivy settings
<!-- setup Ivy default configuration with some custom info -->
<property name="ivy.local.default.root" value="${repository.dir}/local"/>
<property name="ivy.shared.default.root" value="${repository.dir}/shared"/>
<!-- here is how we would have configured Ivy if we had our own Ivy settings file
<ivy:settings file="${common.dir}/ivysettings.xml" id="ivy.instance"/>
-->This declaration configures Ivy by only setting two properties: the location for the local repository and the location for the shared repository. It’s the only settings done here, since Ivy is configured by default to work in a team environment (see default settings tutorial for details about this). For sure in a real environment, the shared repository location would rather be in a team shared directory (or in a more complex repository, again see the default settings tutorial to see how to use something really different). Commented out you can see how the settings would have been done if the default setting wasn’t OK for our purpose.
resolve dependencies
<target name="resolve" depends="clean-lib, load-ivy" description="--> resolve and retrieve dependencies with Ivy">
<mkdir dir="${lib.dir}"/> <!-- not usually necessary, Ivy creates the directory IF there are dependencies -->
<!-- the call to resolve is not mandatory, retrieve makes an implicit call if we don't -->
<ivy:resolve file="${ivy.file}"/>
<ivy:retrieve pattern="${lib.dir}/[artifact].[ext]"/>
</target>You should begin to be familiar with using Ivy this way. We call resolve explicitly to use the Ivy file configured (the default would have been fine), and then call retrieve to copy resolved dependencies artifacts from the cache to a local lib directory. The pattern is also used to name the artifacts in the lib dir with their name and extension only (without revision), this is easier to use with an IDE, as the IDE configuration won’t change when the artifact versions change.
ivy-new-version
<target name="ivy-new-version" depends="load-ivy" unless="ivy.new.revision">
<!-- default module version prefix value -->
<property name="module.version.prefix" value="${module.version.target}-dev-b"/>
<!-- asks Ivy for an available version number -->
<ivy:info file="${ivy.file}"/>
<ivy:buildnumber
organisation="${ivy.organisation}" module="${ivy.module}"
revision="${module.version.prefix}" defaultBuildNumber="1" revSep=""/>
</target>This target is used to ask Ivy to find a new version for a module. To get details about the module we are dealing with, we pull information out of the Ivy file by using the ivy:info task. Then the buildnumber task is used to get a new revision, based on a prefix we set with a property. By default, it will be 1.0-dev-b (have a look at the default value for module.version.target in the common/build.properties file). Each module built by this common build file could easily override this by either setting a different module.version.target in its module specific build.properties, or even overriding module.version.prefix. To get the new revision, Ivy scans the repository to find the latest available version with the given prefix, and then increments this version by 1.
publish
<target name="publish" depends="clean-build, jar" description="--> publish this project in the ivy repository">
<ivy:publish artifactspattern="${build.dir}/[artifact].[ext]"
resolver="shared"
pubrevision="${version}"
status="release"/>
<echo message="project ${ant.project.name} released with version ${version}"/>
</target>This target publishes the module to the shared repository, with the revision found in the version property, which is set by other targets (based on ivy-new-version we have seen above). It can be used when a module reaches a specific milestone, or whenever you want the team to benefit from a new version of the module.
publish-local
<target name="publish-local" depends="local-version, jar" description="--> publish this project in the local ivy repository">
<ivy:publish artifactspattern="${build.dir}/[artifact].[ext]"
resolver="local"
pubrevision="${version}"
pubdate="${now}"
status="integration"
forcedeliver="true"/>
<echo message="project ${ant.project.name} published locally with version ${version}"/>
</target>This is very similar to the publish task, except that this publishes the revision to the local repository, which is used only in your environment and doesn’t disturb the team. When you change something in a module and want to benefit from the change in another one, you can simply call publish-local in this module, and then your next build of the other module will automatically get this local version.
clean-local
<target name="clean-local" description="--> cleans the local repository for the current module">
<delete dir="${ivy.local.default.root}/${ant.project.name}"/>
</target>This target is used when you don’t want to use your local version of a module anymore. For example, when you release a new version to the whole team, or discard your local changes and want to take advantage of a new version from the team.
report
<target name="report" depends="resolve" description="--> generates a report of dependencies">
<ivy:report todir="${build.dir}"/>
</target>Generates both an HTML report and a GraphML report.
For example, to generate a graph like the one shown at the beginning of this tutorial, you just have to follow the instructions given here with the GraphML file you will find in projects/console/build after having called report in the console project, and that’s it, you have a clear overview of all your app dependencies!
Playing with the projects
You can play with this tutorial by using regular Ant commands. Begin in the base directory of the tutorial (src/example/multi-project), and run ant -p:
Unresolved directive in asciidoc/tutorial/multiproject.adoc - include::asciidoc/tutorial/log/multi-project-general-antp.txt[]This gives you an idea of what you can do here. To make sure you have at least one version of all your modules published in your repository (required to build modules having dependencies on the others), you can run ant publish-all (example log here).
You will see that Ivy calls the publish target on all the modules, following the order of the dependencies, so that a dependee is always built and published before its depender. Feel free to make changes in the source code of a module (changing a method name, for instance) and in the module using the method, then call publish-all to see how the change in the dependee is compiled first, published, and then available to the depender which can compile successfully.
Then you can go in one of the example project directories (like projects/find, for instance), and run ant -p:
Unresolved directive in asciidoc/tutorial/multiproject.adoc - include::asciidoc/tutorial/log/multi-project-find-antp.txt[]You can see the targets available, thanks to the import of the common.xml build file. Play with the project by calling resolve, and publish, and see what happens when you do the same in other projects. An interesting thing to do, for instance, is to change the dependencies of a project. If the module version now depends on a new commons library, you will see that all other projects depending on that version will get this library as part of their transitive dependencies once the new revision of the version project is published. Very easy! And if a project introduces a change with which the depender isn’t compatible yet, you can easily change the dependency in the depender to move from latest.integration to a fixed version with which the depender is compatible (probably the latest before the change). Keeping your modules under control is now very easy!
By now, you should be pretty familiar with multi-project development with Ivy. We hope you will appreciate its power and flexibility! And these tutorials are only the beginning of your journey with Ivy, browse the reference documentation to learn more about the features, subscribe to the mailing lists to share your experience and ask questions with the community, browse the source code, open Jira issues, submit patches, join in and help make Ivy the best of dependency management tools!
Using Ivy Module Configurations
This tutorial introduces the use of module configurations in Ivy files. Ivy module configurations are indeed a very important concept. Someone even told me one day that using Ivy without using configurations is like eating a good cheese without touching the glass of Chateau Margaux 1976 you have just poured :-)
More seriously, configurations in Ivy can be better understood as views on your module, and you will see how they can be used effectively here.
Introduction
Source code is available in src/example/configurations/multi-projects.
We have two projects:
-
filter-framework is a library that defines an API to filter String arrays and two implementations of this API.
-
myapp is a very small app that uses filter-framework.
The filter-framework library project produces 3 artifacts:
-
the API jar,
-
an implementation jar with no external dependencies,
-
a second implementation jar that needs commons-collections to perform.
The application only needs the API jar to compile and can use either of the two implementations at runtime.
The library project
The first project we’ll look at in this tutorial is filter-framework. In order to have a fine-grained artifact publication definition, we defined several configurations, each of which maps to a set of artifacts that other projects can make use of.
The ivy.xml file
<ivy-module version="1.0">
<info organisation="org.apache" module="filter-framework"/>
<configurations>
<conf name="api" description="only provide filter framework API"/>
<conf name="homemade-impl" extends="api" description="provide a home made implementation of our API"/>
<conf name="cc-impl" extends="api" description="provide an implementation that use apache common collection framework"/>
<conf name="test" extends="cc-impl" visibility="private" description="for testing our framework"/>
</configurations>
<publications>
<artifact name="filter-api" type="jar" conf="api" ext="jar"/>
<artifact name="filter-hmimpl" type="jar" conf="homemade-impl" ext="jar"/>
<artifact name="filter-ccimpl" type="jar" conf="cc-impl" ext="jar"/>
</publications>
<dependencies>
<dependency org="commons-collections" name="commons-collections" rev="3.1" conf="cc-impl->default"/>
<dependency org="junit" name="junit" rev="3.8" conf="test->default"/>
</dependencies>
</ivy-module>Explanation
As you can see, we defined 4 configurations, with 3 being public and 1 private (the JUnit dependency for testing). The 2 implementation configurations, homemade-impl and cc-impl extend the api configuration so that all artifacts defined in api will also be part of the extending configuration.
In the publications tag, we defined the artifacts we produce (jars in this case) and we assign them to a configuration. When others use our library they will have a flexible way to ask for what they need.
See it in action
The filter-framework project is built using Ant. Open a shell in the root directory of the project and type ant.
Unresolved directive in asciidoc/tutorial/conf.adoc - include::asciidoc/tutorial/log/configurations-lib.txt[]The Ant default target is publish. This target uses Ivy to publish our library binaries to a local repository. Since we do not specify any repository path, the default one is used. (${home.dir}/.ivy2/local/org.apache/filter-framework/) At this point, we are ready to use our library.
The application project
Now that we have shipped (published) our fantastic filter library, we want to use it! The tutorial comes with a sample application called myapp.
The ivy.xml file
<ivy-module version="1.0">
<info organisation="org.apache" module="myapp"/>
<configurations>
<conf name="build" visibility="private" description="compilation only need API jar"/>
<conf name="noexternaljar" description="use only company jar"/>
<conf name="withexternaljar" description="use company jar and third party jars"/>
</configurations>
<dependencies>
<dependency org="org.apache" name="filter-framework" rev="latest.integration" conf="build->api; noexternaljar->homemade-impl; withexternaljar->cc-impl"/>
</dependencies>
</ivy-module>Explanation
We create 3 configurations that define the different ways we want to use the application. The build configuration defines the compile-time dependencies, and thus only needs the api conf from the filter-framework project. The other two configurations define runtime dependencies. One will only use our "home-made" jar, and the other will use an external jar.
We also defined a dependency on our previously built library. In this dependency, we use configuration mappings to match ours with the dependency’s configurations. You can find more information about configuration mapping here
-
build→api : here we tell Ivy that our build configuration depends on the api configuration of the dependency
-
noexternaljar→homemade-impl : here we tell Ivy that our noexternaljar configuration depends on the homemade-impl configuration of the dependency.
-
withexternaljar→cc-impl : here we tell Ivy that our withexternaljar configuration depends on the cc-impl configuration of the dependency
Note that we never declare any of the dependency’s artifacts we need in each configuration: it’s the dependency module’s Ivy file that declares the published artifacts which should be used in each configuration.
In the Ant build.xml file, we defined a 'resolve' target as follow:
<target name="resolve" description="--> retrieve dependencies with ivy">
<ivy:retrieve pattern="${ivy.lib.dir}/[conf]/[artifact].[ext]"/>
</target>When we call this target, Ivy will do a resolve using our ivy.xml file in the root folder and then retrieve all the artifacts. The artifacts retrieved are kept in separate folders according to the configurations they belong to. Here is how your lib directory should look after a call to this target:
Repertoire de D:\ivy\src\example\configurations\multi-projects\myapp\lib
01/24/2006 11:19 AM <REP> build
01/24/2006 11:19 AM <REP> noexternaljar
01/24/2006 11:19 AM <REP> withexternaljar
0 fichier(s) 0 octets
Repertoire de D:\ivy\src\example\configurations\multi-projects\myapp\lib\build
01/24/2006 10:53 AM 1,174 filter-api.jar
1 fichier(s) 1,174 octets
Repertoire de D:\ivy\src\example\configurations\multi-projects\myapp\lib\noexternaljar
01/24/2006 10:53 AM 1,174 filter-api.jar
01/24/2006 10:53 AM 1,030 filter-hmimpl.jar
2 fichier(s) 2,204 octets
Repertoire de D:\ivy\src\example\configurations\multi-projects\myapp\lib\withexternaljar
01/24/2006 10:53 AM 559,366 commons-collections.jar
01/24/2006 10:53 AM 1,174 filter-api.jar
01/24/2006 10:53 AM 1,626 filter-ccimpl.jar
3 fichier(s) 562,166 octetsAs you can see, we have a set of jars for each configuration now.
Let’s try to launch our app.
See it in action
Use Ant to run the application. The default Ant target is run-cc and will launch the application using the Apache commons-collections implementation.
Unresolved directive in asciidoc/tutorial/conf.adoc - include::asciidoc/tutorial/log/configurations-runcc.txt[]Launching the application using the homemade implementation is also straightforward.
type ant run-hm
Unresolved directive in asciidoc/tutorial/conf.adoc - include::asciidoc/tutorial/log/configurations-runhm.txt[]Nice! We got the same result, but we can see that the implementation classes are different.
Conclusion
You should use configurations as often as possible. Configurations are a very important concept in Ivy. They allow you to group artifacts and give the group a meaning. When you write Ivy files for projects that are intended for use by others, use configurations to allow people to get only what they need, without having to specify them one by one in their own dependency list.
Building a repository
The install Ant task lets you copy a module or a set of modules from one repository to another. This is very useful to build and maintain an enterprise or team repository. If you don’t want to give access to the public Maven 2 repository to the developers on your team (to keep control over which modules are in use in your company or your team, for instance), it can sometimes become tiresome to answer the developers request to add new modules or new versions by hand.
Fortunately the install task is here to help: you can use specific settings for your repository maintenance build which will be used to maintain your target enterprise repository. These settings will point to another repository (for instance, the Maven 2 public repository) so that you will just have to ask Ivy to install the modules you want with a simple command line.
To demonstrate this, we will first use a basic Ivy settings file to show how it works, and then we will use the advanced namespaces features to demonstrate how to deal with naming mismatches between the source and target repository.
The project used
The project that we will use is pretty simple. It is composed of an Ant build file, and two Ivy settings files.
Here are the public targets that we will use:
Z:\ivy-repository>ant -p
Buildfile: build.xml
Main targets:
clean-cache --> clean the cache
clean-repo --> clean the destination repository
maven2 --> install module from Maven 2 repository
maven2-deps --> install module from Maven 2 repository with dependencies
maven2-namespace --> install module from Maven 2 using namespaces
maven2-namespace-deps --> install module with dependencies from Maven 2 repository using namespaces
Default target: basicThis project is accessible in the src/example/build-a-ivy-repository
Next steps:
Basic repository copy
Using namespaces
Basic repository copy
In this first step, we use the install Ant task to install modules from the Maven 2 repository to a file system based repository. We first install a module by itself, excluding dependencies, then again with its dependencies.
Basic: ivysettings.xml file used
The Ivy settings file that we will use is very simple here. It defines two resolvers, libraries and my-repository. The first one is used as the source, the second one as the destination. In a typical setup, the second one would be configured using an include that included an existing settings file used by the development team.
<ivysettings>
<settings defaultResolver="libraries"
defaultConflictManager="all"/> <!-- in order to get all revisions without any eviction -->
<caches defaultCacheDir="${ivy.cache.dir}/no-namespace"/>
<resolvers>
<ibiblio name="libraries" m2compatible="true"/>
<filesystem name="my-repository">
<ivy pattern="${dest.repo.dir}/no-namespace/[organisation]/[module]/ivys/ivy-[revision].xml"/>
<artifact pattern="${dest.repo.dir}/no-namespace/[organisation]/[module]/[type]s/[artifact]-[revision].[ext]"/>
</filesystem>
</resolvers>
</ivysettings>Install a simple module without dependencies
Let’s have a look at the maven2 target.
<target name="maven2" depends="init-ivy"
description="--> install module from maven 2 repository">
<ivy:install settingsRef="basic.settings"
organisation="commons-lang" module="commons-lang" revision="1.0"
from="${from.resolver}" to="${to.resolver}"/>
</target>Pretty simple, we call the ivy:install task with the settings we have loaded using ivy:settings as usual. We then set the source and destination repositories using the from and to attributes. We used Ant properties for these values here, which helps ease the maintenance of the script, but it’s basically the name of our resolvers: 'libraries' for the source and 'my-repository' for the destination.
Here is the Ant call output :
Unresolved directive in asciidoc/tutorial/build-repository/basic.adoc - include::asciidoc/tutorial/log/install.txt[]The trace tells us that the module definition was found using the "libraries" resolver and that the corresponding artifact was downloaded from the Maven 2 repository. Then both were published to the filesystem repository (my-repository).
Let’s have a look at our repository :
Unresolved directive in asciidoc/tutorial/build-repository/basic.adoc - include::asciidoc/tutorial/log/myrepository-content.txt[]We can see that we now have the commons-lang module version 1.0 in our repository, with a generated ivy.xml file, its jar, and all the md5 and sha1 checksums for future consistency checks when developers use this repository to resolve modules.
Install a module with dependencies
Now let’s say that we want to be sure all the dependencies of the module we install are available in our repository after the installation. We could either install without dependencies in a staging repository and check the missing dependencies (more control), or use transitive dependency management and ask Ivy to install everything for us (much simpler).
The maven2-deps target is very similar to the one described above, except that we explicitly ask for transitive installation.
<target name="maven2-deps" depends="init-ivy"
description="--> install module from maven 2 repository with dependencies">
<ivy:install settingsRef="basic.settings"
organisation="org.hibernate" module="hibernate" revision="3.2.5.ga"
from="${from.resolver}" to="${to.resolver}" transitive="true"/>
</target>If you call this target, you will see that Ivy installs not only the hibernate module but also its dependencies:
Unresolved directive in asciidoc/tutorial/build-repository/basic.adoc - include::asciidoc/tutorial/log/install-deps.txt[]As you can see the installation has failed, and if you look at the log you will see that there are missing artifacts in the source repository. This means that you will need to download those artifacts manually, and copy them to your destination repository to complete the installation. Fortunately Ivy uses a best effort algorithm during install, so that everything gets installed except the missing artifacts. (Note: these missing artifacts are not in the public Maven repository due to licensing issues.)
You may also have noticed that Ivy installed 2 different revisions of commons-logging (1.0.2, 1.0.4). This is due to the fact that we used the "no conflict" conflict manager in the Ivy settings file.
We do not want to evict any modules because we are building our own repository. Indeed, if we get both commons-logging 1.0.2 and 1.0.4, it’s because some modules among the transitive dependencies of hibernate depend on 1.0.2 and others on 1.0.4. If we got only 1.0.4, the module depending on 1.0.2 would be inconsistent in your own repository (depending on a version you did not install). Thus developers using this module directly would run into a problem.
If you now have a closer look at your repository, you will probably notice that it isn’t an exact replica of the original one. Let’s have a look at the directory of one module:
Unresolved directive in asciidoc/tutorial/build-repository/basic.adoc - include::asciidoc/tutorial/log/myrepository-content-deps.txt[]As you can see there is no POM here (POM is the module metadata format used by Maven 2, available in the Maven 2 repository). Instead you can see there’s an Ivy file, which is actually the original Hibernate POM converted into an Ivy file. So now you have a true Ivy repository with Ivy files, where you can use the full power of Ivy if you want to adjust the module metadata (module configurations, fine grained exclusions and transitivity control, per module conflict manager, …).
OK, enough for this simple repository installation, the next tutorial will show how you can deal with more complex cases where your source and destination repositories do not follow the same naming conventions.
Using namespaces
Now that you have seen how simple it is to create your own repository from an existing one, you may wonder how you can handle more complex cases, like when the source and destination repositories don’t follow the same naming conventions.
On the road to a professional repository
In this section, you will learn how to build a professional repository. What is a professional repository? Our vision is to say that a good quality repository must follow clear rules about project naming and must offer correct, usable configurations and verified project descriptors. In order to achieve those goals, we believe that you have to build your own repository. We have seen in the previous example, that we could use some public repositories to begin building our own repository. Nevertheless, the result is not always the expected one, especially concerning the naming rules used.
This problem is pretty normal when you have an existing repository, and want to benefit from large public repositories which do not follow the same naming conventions. It also shows up because many public repositories do not use a consistent naming scheme. For example, why don’t all the Apache Commons modules use the org.apache.commons organization? Well… for historical reasons. But if you set up your own repository, you may not want to suffer from the mistakes of history.
Fortunately, Ivy has a very powerful answer to this problem: namespaces.
Using namespaces
If you look at the repository built with the previous tutorial, you will see exactly what we were talking about: all Apache Commons modules use their own name as their organization.
So let’s see what Ivy can do using namespaces (we will dig into details later):
Unresolved directive in asciidoc/tutorial/build-repository/advanced.adoc - include::asciidoc/tutorial/log/install-namespace.txt[]Now if we look at our repository, it seems to look fine.
Unresolved directive in asciidoc/tutorial/build-repository/advanced.adoc - include::asciidoc/tutorial/log/myrepository-content-namespace.txt[]We can even have a look at the commons-lang Ivy file in our repository:
<?xml version="1.0" encoding="UTF-8"?>
<ivy-module version="1.0">
<info organisation="apache"
module="commons-lang"
revision="1.0"
status="integration"
publication="20051124062021"
namespace="ibiblio-maven2"/>
...Alright, we see that the organisation is now 'apache'. But where did Ivy pick this up?
How does this work ?
Actually, Ivy uses the same repository as before for the source repository, with only one difference: the namespace parameter:
<ibiblio name="libraries"
root="${ibiblio-maven2-root}"
m2compatible="true"
namespace="maven2"/>A namespace is defined by a set of rules. These rules are based on regular expressions and tell Ivy how to convert data from the repository namespace to what is called the system namespace, i.e. the namespace in which Ivy runs most of the time (Note: the Ivy cache always uses the system namespace).
For the namespace we call maven2, we have declared several rules. Below is one of the rules:
rule handling the imported Apache Maven 1 projects
<rule> <!-- imported apache maven 1 projects -->
<fromsystem>
<src org="apache" module=".+"/>
<dest org="$m0" module="$m0"/>
</fromsystem>
<tosystem>
<src org="commons-.+" module="commons-.+"/>
<src org="ant.*" module="ant.*"/>
...
<src org="xmlrpc" module="xmlrpc"/>
<dest org="apache" module="$m0"/>
</tosystem>
</rule>|
Note
|
Note about regular expressions usage : In order to distinguish matching regular expressions found in organization, module, and revision, the notation Ivy uses prefixes the matching regular expression with the letters 'o', 'm' and 'r'. $o0 : the whole matching value in the organization attribute $o1 : the first matching expression group that was marked in the organization attribute … The same applies for modules : $m0, $m1, … and for revisions : $r0, $r1, … |
To understand namespaces,
-
fromsystem : we define here that the projects defined in the system namespace under the organization called "apache" are transformed into the destination namespace into projects whose organization is named with the module name, whatever the revision is. For example, the project apache#commons-lang;1.0 in the system namespace will be translated into commons-lang#commons-lang;1.0 in the maven2 resolver namespace.
-
tosystem : we define here the reverse mapping, i.e. how to translate Apache projects from Maven 2 repo into Apache projects in the system namespace. The rule used here tells Ivy that all projects matching
commons-.+(see it as Java regular expression) for their organization name and module name are transformed into projects whose organisation isapachewith the module name as it was found. The same kind of rule is defined for other Apache projects like Ant, etc.
OK, you should now get the idea behind namespaces, so go ahead and look at the ivysettings-advanced.xml file in this example. You can test the installation of a module and its dependencies using namespaces.
Run
ant maven2-namespace-depsand you will see the resulting repository is cleaner than the first one we built.
From our experience, investing in creating a namespace is worth the time it costs if you often need to add new modules or revisions of third party libraries in your own repository, where naming rules already exist or are rather strict.
More examples
If you have successfully followed and understood all the tutorials, you still might need to get a better picture of how to use Ivy in the real world.
Here are some links which might be interesting:
SAnt
SAnt is an experimental build system based on Ant and Ivy. It can be interesting to use "as is", or to get insight on an interesting approach to manage your builds.
Spring Modules
The Spring Modules project build system is based on Ant and Ivy, and it’s really interesting to have a look at how a modularized project can take advantage of advanced Ant and Ivy features to make the build simpler.
Webwork
The Webwork project (which became Struts Action framework) uses Ant+Ivy for their build, and thus makes their framework very easy to use in an Ant+Ivy build system. They have a page documenting how to use Ivy with their framework, which can be an interesting reading, even if you don’t plan to use Webwork.
Easing multi-module development
Johan Stuyts, the author of SAnt, also contributed a nice article on his view of how to use Ivy on a multi-module environment.
Beginners Guide
Apache Ivy - Beginners Guide is a step by step guide to assist beginners in understanding basic concepts/tasks and use them straight away in their projects either through Ant build or in Eclipse IDE.
Reference
Welcome to the Ivy reference documentation!
If you don’t know Ivy at all, take a look at its features, the faq and the tutorials before digging into this reference documentation.
Reference Overview
This documentation is broken into several parts:
-
Introduction
-
This part gives you the meaning of some words used all over the Ivy documentation, such as organization, module, configurations, settings, …
-
This part introduces the main concepts used in Ivy: dependency resolvers, variables, patterns, and explains a central Ivy concept: module configurations.
-
As the title suggests, here you will find an explanation of how Ivy does work internally, which can help to better understand and customize its use.
-
This part describes how to install Ivy.
-
This part describes possibility to control the behavior of Ivy at run time
-
-
This part is dedicated to the specification of the settings file of Ivy (usually called ivysettings.xml). It also gives the list of built-in dependency resolvers available in Ivy.
-
This part is the reference for the module descriptors, the Ivy files in which you describe your dependencies. If you have any questions about what can be done or not in an Ivy file, you will find the answer here.
-
This part describes how to use Ivy from Ant. It’s in this section that all Ant tasks provided by Ivy are specified.
-
Even though Ivy is most often used from Ant, it can also be used from the command line. This page describes how you can do this.

{kind=link}
Organisation
An organisation is either a company, an individual, or simply any group of people that produces software. In principle, Ivy handles only a single level of organisation, meaning that they have a flat namespace in Ivy module descriptors. So, with Ivy descriptors, you can only describe a tree-like organisation structure, if you use a hierarchical naming convention. The organisation name is used for keeping together software produced by the same team, just to help locate their published works.
Often organisations will use their inverted domain name as their organisation name in Ivy, since domain names by definition are unique. A company whose domain name is www.example.com might want to use com.example, or if they had multiple teams, all their organisation names could begin with com.example (e.g. com.example.rd, com.example.infra, com.example.services). The organisation name does neither really have to be an inverted domain name, nor even globally unique, but unique naming is highly recommended. Widely recognized trademark or trade name owners may choose to use their brand name instead.
Examples: org.apache, ibm, jayasoft
Note that the Ivy organisation is very similar to Maven POM groupId.
Module
A module is a self-contained, reusable unit of software that, as a whole unit, follows a revision control scheme.
Ivy is only concerned about the module deliverables known as artifacts, and the module descriptor that declares them. These deliverables, for each revision of the module, are managed in repositories. In other words, to Ivy, a module is a chain of revisions each comprising a descriptor and one or more artifacts.
Examples: hibernate-entitymanager, ant
Module Descriptor
A module descriptor is a generic way of identifying what describes a module: the identifier (organisation, module name, branch and revision), the published artifacts, possible configurations and their dependencies.
The most common module descriptors in Ivy are Ivy Files, XML files with an Ivy specific syntax, and usually called ivy.xml.
But since Ivy is also compatible with Maven 2 metadata format (called POM, for Project Object Model), POM files fall into the category of module descriptors.
And because Ivy accepts pluggable module descriptor parsers, you can use almost whatever you want as module descriptors.
Artifact
An artifact is a single file ready for delivery with the publication of a module revision, as a product of development.
Compressed package formats are often preferred because they are easier to manage, transfer and store. For the same reasons, only one or a few artifacts per module are commonly used. However, artifacts can be of any file type and any number of them can be declared in a single module.
In the Java world, common artifacts are Java archives or JAR files. In many cases, each revision of a module publishes only one artifact (like jakarta-log4j-1.2.6.tar.gz, for instance), but some of them publish many artifacts depending on the use of the module (like apache-ant binary and source distributions in zip, gz and bz2 package formats, for instance).
Examples: ant-1.7.0-bin.zip, apache-ant-1.7.0-src.tar.gz
Type of an artifact
The artifact type is a category of a particular kind of artifact specimen. It is a classification based on the intended purpose of an artifact or why it is provided, not a category of packaging format or how the artifact is delivered.
Although the type of an artifact may (rather accidentally) imply its file format, they are two different concepts. The artifact file name extension is more closely associated with its format. For example, in the case of Java archives the artifact type "jar" indicates that it is indeed a Java archive as per the JAR File specification. The file name extension happens to be "jar" as well. On the other hand, with source code distributions, the artifact type may be "source" while the file name extensions vary from "tar.gz", "zip", "java", "c", or "xml" to pretty much anything. So, the type of an artifact is basically an abstract functional category to explain its purpose, while the artifact file name extension is a more concrete technical indication of its format and, of course, naming.
Defining appropriate artifact types for a module is up to its development organisation. Common choices may include: "jar", "binary", "bin", "rc", "exe", "dll", "source", "src", "config", "conf", "cfg", "doc", "api", "spec", "manual", "man", "data", "var", "resource", "res", "sql", "schema", "deploy", "install", "setup", "distrib", "distro", "distr", "dist", "bundle", etc.
Module descriptors are not really artifacts, but they are comparable to an artifact type, i.e. "descriptor" (an Ivy file or a Maven POM).
Electronic signatures or digests are not really artifacts themselves, but can be found with them in repositories. They also are comparable to an artifact type, i.e. "digest" (md5 or sha1).
Artifact file name extension
In some cases the artifact type already implies its file name extension, but not always. More generic types may include several different file formats, e.g. documentation can contain tarballs, zip packages or any common document formats.
Examples: zip, tar, tar.gz, rar, jar, war, ear, txt, doc, xml, html
Module Revision and Status
Module revision
A unique revision number or version name is assigned to each delivered unique state of a module. Ivy can help in generating revision numbers for module delivery and publishing revisions to repositories, but other aspects of revision control, especially source revisioning, must be managed with a separate version control system.
Therefore, to Ivy, a revision always corresponds to a delivered version of a module. It can be a public, shared or local delivery, a release, a milestone, or an integration build, an alpha or a beta version, a nightly build, or even a continuous build. All of them are considered revisions by Ivy.
Source revision
Source files kept under a version control system (like Subversion, CVS, SourceSafe, Perforce, etc.) have a separate revisioning scheme that is independent of the module revisions visible to Ivy. Ivy is unaware of any revisions of a module’s source files.
In some cases, the SCM’s source revision number could be used also as the module revision number, but that usage is very rare. They are still two different concepts, even if the module revision number was wholly or partially copied from the respective source revision number.
Branch
A branch corresponds to the standard meaning of a branch (or sometimes stream) in source control management tools. The head, or trunk, or main stream, is also considered as a branch in Ivy.
Status of a revision
A module’s status indicates how stable a module revision can be considered. It can be used to consolidate the status of all the dependencies of a module, to prevent the use of an integration revision of a dependency in the release of your module.
Three statuses are defined by default in Ivy:
integration-
revisions built by a continuous build, a nightly build, and so on, fall in this category
milestone-
revisions delivered to the public but not actually finished fall in this category
release-
a revision fully tested and labelled fall in this category
(since 1.4) This list is configurable in your settings file.
Configurations of a module
A module configuration is a way to use or construct a module. If the same module has different dependencies based on how it’s used, those distinct dependency-sets are called its configurations in Ivy.
Some modules may be used in different ways (think about hibernate which can be used inside or outside an application server), and this way may alter the artifacts you need (in the case of hibernate, jta.jar is needed only if it is used outside an application server). Moreover, a module may need some other modules and artifacts only at build time, and some others at runtime. All those different ways to use or build a module are called module configurations in Ivy.
For more details on configurations and how they are used in Ivy, please refer to the main concepts page.
Ivy Settings
Ivy settings files are XML files used to configure Ivy to indicate where the modules can be found and how.
History of settings
Prior to Ivy 2.0, the settings files were called configuration files and usually named ivyconf.xml. This resulted in confusion between module configurations and Ivy configuration files, so they were renamed to settings files. If you happen to fall on an ivyconf file or something called a configuration file, most of the time it’s only unupdated information (documentation, tutorial or article). Feel free to report any problem like this if you find such an inconsistency.
Repository
What is called a repository in Ivy is a distribution site location where Ivy is able to find your required modules' artifacts and descriptors (i.e. Ivy files in most cases).
Ivy can be used with complex repositories configured very finely. You can use Dependency Resolvers to do so.
Dependency Resolver
A dependency resolver is a pluggable class in Ivy which is used to:
-
find dependencies' Ivy files
-
download dependencies' artifacts
The notion of artifact "downloading" is large: an artifact can be on a web site, or on the local file system of your machine. The download is thus the act of bring a file from a repository to the Ivy cache.
Moreover, the fact that it is the responsibility of the resolver to find Ivy files and download artifacts helps to implement various resolving strategies.
As you see, a dependency resolver can be thought of as a class responsible for describing a repository.
If you want to see which resolvers are available in Ivy, you can go to the resolvers configuration page.
Module configurations explained
Module configurations are described in the terminology page as a way to use or construct a module. Configurations being a central part of Ivy, they need more explanations as a concept.
When you define a way to use or construct a module, you are able to define which artifacts are published by this module in this configuration, and you are also able to define which dependencies are needed in this configuration.
Moreover, because dependencies in Ivy are expressed on modules and not on artifacts, it is important to be able to define which configurations of the dependency are required in the configuration you define of your module. That’s what is called configuration mapping.
If you use only simple modules and do not want to worry about configurations, you don’t have to worry about them. They’re still there under the hood because Ivy can’t work without configurations. But most of the time if you declare nothing, Ivy assumes that the artifacts of your module are published in all configurations, and that all the dependencies' configurations are required in all configurations. And it works in simple cases. But whenever you want to separate things within a module, or get more control over things published and get better dependencies resolution, configurations will meet most of your needs.
For details on how to declare your module configurations, how to declare in which configuration your artifacts are published, and how to declare configuration mapping, please refer to Ivy file documentation. The configurations tutorial is also a good place to go to learn more about this concept.
Variables
During configuration, Ivy allows you to define what are called Ivy variables. Ivy variables can be seen as Ant properties, and are used in a very similar way. In particular, you use a properties tag in the settings file to load a properties file containing Ivy variables and their values.
But the main differences between Ant properties and Ivy variables are that Ivy variables can be overridden, whereas Ant properties can’t, and that they are defined in separate environments.
Actually all Ant properties are imported into Ivy variables when the configuration is done (if you call Ivy from Ant). This means that if you define an Ant property after the call to configure, it will not be available as an Ivy variable. On the other hand, Ivy variables are NOT exported to Ant, thus if you define Ivy variables in Ivy, do not try to use them as Ant properties.
To use Ivy variables, you just have to follow the same syntax as for Ant properties: ${variablename} where variablename is the name of the variable.
Finally, it’s also important to be aware of the time of substitution of variables. This substitution is done as soon as possible. This means that when Ivy encounters a reference to a variable, it tries to substitute it if such a variable is defined. Consequently, any later modification of the variable will not alter the value already substituted.
Moreover, in an Ant environment, a bunch of variables are going to be set by default via the Ant property file loading mechanism (actually they are first loaded as Ant properties and then imported as Ivy variables, see Ant Tasks), and even in the Ant properties themselves there is going to be eager substitution on loading, effectively making it impossible to override some variable purely via the ivysettings.properties file. Some variables will really only be able to be overridden via Ant properties because of this.
Moreover, it’s also important to understand the difference between Ivy variables and Ivy pattern tokens. See the Patterns chapter below for what pattern tokens are.
Patterns
Ivy patterns are used in many dependency resolvers and Ivy tasks, and are a simple way to structure the way Ivy works.
First let’s give an example. You can, for instance, configure the file system dependency resolver by giving it a pattern to find artifacts. This pattern can be like this:
myrepository/[organisation]/[module]/[type]s/[artifact]-[revision].[ext]
This pattern indicates that the repository we use is in a directory called myrepository.
In this directory we have directories having for name the name of the organisation of the module we look for. Then we have a directory per module, each having for name the name of the module. Then in module directories we find a directory per artifact type (jars, wars, ivys, …), in which we find artifacts named by the artifact id, followed by a hyphen, then the revision, a dot, and the artifact extension. Not too difficult to understand is it? That’s it, you have understood the pattern concept!
To give a bit more explanation, a pattern is composed of tokens, which are replaced by actual values when evaluated for a particular artifact or module. Those tokens are different from variables because they are replaced differently for each artifact, whereas variables are usually given the same value.
You can mix variables and tokens in a pattern:
${repository.dir}/[organisation]/[module]/[type]s/[artifact]-[revision].[ext]
The tokens available depends on where the pattern is used (will it be evaluated with artifacts or modules, for instance). But here are all the tokens currently available:
[organisation]-
the organisation name
[orgPath]-
(since 2.3)
the organisation name where '.' has been replaced by '/'. This can be used to configure Maven 2-like repositories. [module]-
the module name
[branch]-
the branch name
[revision]-
the revision name
[artifact]-
the artifact name (or id)
[type]-
the artifact type
[ext]-
the artifact file extension
[conf]-
the configuration name
[originalname]-
(since 1.4)
the original artifact name (not including the extension)
The difference between type and extension is explained in the Ivy file documentation.
(since 1.2) [organization] can be used instead of [organisation].
(since 1.3) Optional parts can be used in patterns.
This provides the possibility to avoid some input when a token is not defined, instead of having only the token as blank. Parenthesis are used to delimit the optional part, and only one token can be found inside the parenthesis.
So if you surround a token with ( and ), any other text which is between the parenthesis will be ignored if the token has no value.
For instance, suppose the pattern: abc(def[type]ghi)
-
type="jar"→ the substituted pattern:abcdefjarghi -
type=nullor""→ the substituted pattern:abc
A more real life example:
The pattern [artifact](-[revision]).[ext] lets you accept both myartifact-1.0.jar when a revision is set, and myartifact.jar (instead of myartifact-.jar) when no revision is set. This is particularly useful when you need to keep control of artifact names.
(since 1.4) Extra attributes can be used as any other token in a pattern.
Latest Strategy
Ivy often needs to know which revision between two is considered the "latest". To know that, it uses the concept of latest strategy. Indeed, there are several ways to consider a revision to be the latest. You can choose an existing one or plug in your own.
But before knowing which revision is the latest, Ivy needs to be able to consider several revisions of a module. Thus Ivy has to get a list of files in a directory, and it uses the dependency resolver for that. So check if the dependency resolver you use is compatible with latest revisions before wondering why Ivy does not manage to get your latest revision.
Finally, in order to get several revisions of a module, most of the time you need to use the [revision] token in your pattern so that Ivy gets all the files which match the pattern, whatever the revision is. It’s only then that the latest strategy is used to determine which of the revisions is the latest one.
Ivy has three built-in latest strategies:
latest-time-
This compares the revision dates to know which is the latest. While this is often a good strategy in terms of pertinence, it has the drawback of being costly to compute for distant repositories. If you use ivyrep, for example, Ivy has to ask the HTTP server what is the date of each Ivy file before knowing which is the latest.
latest-revision-
This compares the revisions as strings, using an algorithm close to the one used in the PHP
version_comparefunction.This algorithm takes into account special meanings of some text. For instance, with this strategy, 1.0-dev1 is considered before 1.0-alpha1, which in turn is before 1.0-rc1, which is before 1.0, which is before 1.0.1.
latest-lexico-
This compares the revisions as strings, using lexicographic order (the one used by the Java string comparison).
See also how to configure new latest strategies here.
Conflict Manager
A conflict manager is able to select, among a list of module revisions in conflict, a list of revisions to keep. Yes, it can select a list of revisions, even if most conflict managers select only one revision. But in some cases you will need to keep several revisions, and load in separate class loaders, for example.
A list of revisions is said to be in conflict if they correspond to the same module, i.e. the same organisation/module name couple.
The list of available conflict managers is available on the conflict manager configuration page.
For more details on how to setup your conflict managers by module, see the conflicts section in the Ivy file reference.
Pattern matcher
(since 1.3) In several places Ivy uses a pattern to match a set of objects. For instance, you can exclude several modules at once when declaring a dependency by using a pattern matching all the modules to exclude.
Ivy uses a pluggable pattern matcher to match those object names. 3 are defined by default:
exact-
This matcher matches only using strings
regexp-
This matcher lets you use a regular expression as supported by the Pattern class of Java 1.4 or greater
glob-
This matcher lets you use a Unix-like glob matcher, i.e. where the only meta characters are
*which matches any sequence of characters and?which matches exactly one character. Note that this matcher is available only with Jakarta ORO 2.0.8 in your classpath.
Note also that with any matcher, the character '*' has the special meaning of matching anything. This is particularly useful with default values which do not depend on the matcher.
Extra attributes
(since 1.4) Several tags in Ivy XML files are extensible with what is called extra attributes. The idea is very simple: if you need some more information to define your modules, you can add the attribute you want and you will then be able to access it as any other attribute in your patterns.
(since 2.0) It’s possible and recommended to use XML namespaces for your extra attributes. Using an Ivy extra namespace is the easiest way to add your own extra attributes.
Example: here is an Ivy file with the attribute color set to blue:
<ivy-module version="2.0" xmlns:e="http://ant.apache.org/ivy/extra">
<info organisation="apache"
module="foo"
e:color="blue"
status="integration"
revision="1.59"/>
</ivy-module>Then you must use the extra attribute when you declare a dependency on foo. Those extra attributes will indeed be used as identifiers for the module like the org, the name and the revision:
<dependency org="apache" name="foo" e:color="blue" rev="1.5+"/>And you can define your repository pattern as:
${repository.dir}/[organisation]/[module]/[color]/[revision]/[artifact].[ext]Note that in patterns you must use the unqualified attribute name (no namespace prefix).
If you don’t want to use XML namespaces, it’s possible but you will need to disable Ivy file validation, since your files won’t fulfill anymore the official Ivy XSD. See the settings documentation to see how to disable validation.
Checksums
(since 1.4) Ivy allows the use of checksums, also known as digests, to verify the correctness of a downloaded file.
The configuration of using the algorithm can be done globally or by dependency resolver. Globally, use the ivy.checksums variable to list the check to be done. On each resolver you can use the checksums attribute to override the global setting.
The setting is a comma separated list of checksum algorithms to use.
During checking (at download time), the first checksum found is checked, and that’s all. This means that if you have a "SHA-256, sha1, md5" setting, then if Ivy finds a SHA-256 file, it will compare the downloaded file SHA-256 against this SHA-256, and if the comparison is ok, it will assume the file is ok. If no SHA-256 file is found, it will look for an sha1 file. If that isn’t found, then it checks for md5 and so on. If none is found no checking is done.
During publish, all listed checksum algorithms are computed and uploaded.
By default checksum algorithms are "sha1, md5".
If you want to change this default, you can set the variable ivy.checksums. Hence, to disable checksum validation you just have to set ivy.checksums to "".
Supported algorithms
(since 1.4)
-
md5
-
sha1
(since 2.5) In addition to md5 and sha1, Ivy supports SHA-256, SHA-512 and SHA-384 algorithms, if the Java runtime in which Ivy is running, supports those. For example, Java 6 runtime supports SHA-256 and SHA-512 as standard algorithms. If Ivy 2.5 and later versions run in Java 6 or higher runtimes, these algorithms are supported by Ivy too.
Events and Triggers
(since 1.4) When Ivy performs the dependency resolution and some other tasks, it fires events before and after the most important steps. You can listen to these events using Ivy API, or you can even register a trigger to perform a particular action when a particular event occur.
This is a particularly powerful and flexible feature which allows, for example, you to perform a build of a dependency just before it is resolved, or follow what’s happening during the dependency resolution process accurately, and so on.
For more details about events and triggers, see the triggers documentation page in the configuration section of this documentation.
Circular Dependencies
(since 1.4) Circular dependencies can be either direct or indirect. For instance, if A depends on A, it’s a circular dependency, and if A depends on B which itself depends on A, this is also a circular dependency.
Prior to Ivy 1.4 circular dependencies caused a failure in Ivy. As of Ivy 1.4, the behaviour of Ivy when it finds a circular dependency is configurable through a circular dependency strategy.
3 built-in strategies are available:
ignore-
circular dependencies are only signaled in verbose messages
warn-
same as ignore, except that they are signaled as a warning (default)
error-
halt the dependency resolution when a circular dependency is found
See the configuration page to see how to configure the circular dependency strategy you want to use.
Cache and Change Management
Ivy heavily relies on local caching to avoid accessing remote repositories too often, thus saving a lot of network bandwidth and time.
Cache types
An Ivy cache is composed of two different parts:
- the repository cache
-
The repository cache is where Ivy stores data downloaded from module repositories, along with some meta information concerning these artifacts, like their original location. This part of the cache can be shared if you use a well suited lock strategy.
- the resolution cache
-
This part of the cache is used to store resolution data, which is used by Ivy to reuse the results of a resolve process.
This part of the cache is overwritten each time a new resolve is performed, and should never be used by multiple processes at the same time.
While there is always only one resolution cache, you can define multiple repository caches, each resolver being able to use a separate cache.
Change management
To optimize the dependency resolution and the way the cache is used, Ivy assumes by default that a revision never changes. So once Ivy has a module in its cache (metadata and artifacts), it trusts the cache and does not even query the repository. This optimization is very useful in most cases, and causes no problem as long as you respect this paradigm: a revision never changes. Besides performance, there are several good reasons to follow this principle.
However, depending on your current build system and your dependency management strategy, you may prefer to update your modules sometimes. There are two kinds of changes to consider:
Changes in module metadata
Since pretty often module metadata are not considered by module providers with as much attention as their API or behavior (if they even provide module metadata), it happens more than we would like that we have to update module metadata: a dependency has been forgotten, or another one is missing, …
In this case, setting checkModified="true" on your dependency resolver will be the solution. This flag tells Ivy to check if module metadata has been modified compared to the cache. Ivy first checks the metadata last modified timestamp on the repository to download it only if necessary, and then updates it when needed.
Changes in artifacts
Some people, especially those coming from Maven 2 land, like to use one special revision to handle often updated modules. In Maven 2, this is called a SNAPSHOT version, and some argue that it helps save disk space to keep only one version for the high number of intermediary builds you can make whilst developing.
Ivy supports this kind of approach with the notion of "changing revision". A changing revision is just that: a revision for which Ivy should consider that the artifacts may change over time. To handle this, you can either specify a dependency as changing on the dependency tag, or use the changingPattern and changingMatcher attributes on your resolvers to indicate which revision or group of revisions should be considered as changing.
Once Ivy knows that a revision is changing, it will follow this principle to avoid checking your repository too often: if the module metadata has not changed, it will considered the whole module (including artifacts) as not changed. Even if the module descriptor file has changed, it will check the publication data of the module to see if this is a new publication of the same revision or not. Then if the publication date has changed, it will check the artifacts' last modified timestamps, and download them accordingly.
So if you want to use changing revisions, use the publish task to publish your modules, it will take care of updating the publication date, and everything will work fine. And remember to set checkModified=true" on your resolver too!
Paths handling
As a dependency manager, Ivy has a lot of file related operations, which most of the time use paths or path patterns to locate the file on the filesystem.
These paths can obviously be relative or absolute. We recommend to always use absolute paths, so that you don’t have to worry about what is the base of your relative paths. Ivy provides some variables which can be used as the base of your absolute paths. For instance, Ivy has a concept of base directory, which is basically the same as for Ant. You have access to this base directory with the ivy.basedir variable. So if you have a path like ${ivy.basedir}/ivy.xml, you have an absolute path. In settings files, you also have a variable called ivy.settings.dir which points to the directory in which your settings file is located, which makes defining paths relative to this directory very easy.
If you really want to use relative paths, the base directory used to actually locate the file depends on where the relative path is defined:
-
In an Ivy file, paths are relative to the Ivy file itself (the only possible path in an Ivy file is for configurations declaration inclusion)
-
In settings files, paths for file inclusion (namely properties file loading and settings inclusion) are relative to the directory in which the settings file is located. All other paths must be absolute unless explicitly noted.
-
In Ivy Ant tasks and Ivy parameters or options, paths are relative to Ivy base directory, which when called from Ant is the same as your Ant basedir.
Packaging
Most of the artifacts found in a repository are jars. They can be downloaded and used as is. But some other kind of artifacts required some unpacking after being downloaded and before being used. Such artifacts can be zipped folders and packed jars. Ivy supports that kind of artifact with packaging.
A packaged artifact needs to be declared as such in the module descriptor via the attribute packaging. The value of that attribute defined which kind of unpacking algorithm must be used. Here are the list of currently supported algorithms:
So, if in an ivy.xml, there would be declared a such artifact:
<artifact name="mymodule" type="jar" ext="jar.pack.gz" packaging="pack200"/>A file mymodule-1.2.3.jar.pack.gz would be download into the cache, and also uncompressed in the cache to mymodule-1.2.3.jar. Then any post resolve task which supports it, like the cachepath, will use the uncompressed file instead of the original compressed file.
It is possible to chain packing algorithm. The attribute packaging of a artifact expects a comma separated list of packing types, in packing order. For instance, an artifact mymodule-1.2.3.jar.pack.gz can have the packaging jar,pack200, so it would be uncompressed as a folder mymodule-1.2.3.
Text Conventions
Very often some concepts discussed in Ivy here, and especially those involving modules and dependencies, require to be discussed by text (e-mail, textual doc, console, …), and so benefit from convention in this area.
The conventions have been adopted with Ivy 2.0 are the following:
| what | pattern | example |
|---|---|---|
a module without revision |
|
|
a module with revision |
|
|
a module with (some) configurations |
|
|
a module with revision and (some) configurations |
|
|
a module’s artifact |
|
|
a module’s artifact with revision |
|
|
Another usual text representation used is to represent dependencies using a dash followed by greater than sign: ->
To group a set of set of modules, we recommend using curly braces { }.
With these conventions, it’s easy to give a concise and detailed overview of a set of modules and their dependencies.
For instance:
#A;2-> { #B;[1.0,1.5] #C;[2.0,2.5] }
#B;1.4->#D;1.5
#B;1.5->#D;2.0
#C;2.5->#D;[1.0,1.6]In full words here is how it could be written:
module A revision 2 depends on module B with the version constraint [1.0,1.5], and on module C with the version constraint [2.0,2.5].
module B revision 1.4 depends on module D revision 1.5.
module B revision 1.5 depends on module D revision 2.0.
module C revision 2.5 depends on module D with the version constraint [1.0,1.6].As you can see, using text conventions is much more concise.
Another benefit is that these conventions are usually used in Ivy console output, and can also be used in some cases to be parsed into Ivy objects (we use it for test cases, for instance). To make sure text parsing works fine, we recommend using only a limited range of characters for each attributes of your module identifiers.
Here is the recommended characters set for each attribute:
organisation-
a-zA-Z0-9-/._+= module-
a-zA-Z0-9-/._+= branch-
a-zA-Z0-9-/._+= revision-
a-zA-Z0-9-/._+=,[]{}():@ artifact-
a-zA-Z0-9-/._+= extension-
a-zA-Z0-9-/._+= type-
a-zA-Z0-9-/._+=
How does it work ?
Now that you have been introduced to the main Ivy terminology and concepts, it is time to give some explanation of how Ivy works.
Usual cycle of modules between different locations

More details on ant tasks here.
Configure
Ivy needs to be configured to be able to resolve your dependencies. This configuration is usually done with a settings file, which defines a set of dependency resolvers. Each resolver is able to find Ivy files and/or artifacts, given simple information such as organisation, module, revision, artifact name, artifact type and artifact extension.
The configuration is also responsible for indicating which resolver should be used to resolve which module. This configuration is dependent only on your environment, i.e. where the modules and artifacts can be found.
A default configuration is used by Ivy when none is given. This configuration uses an ibiblio resolver pointing to https://repo1.maven.org/maven2/ to resolve all modules.
Resolve
The resolve time is the moment when Ivy actually resolves the dependencies of one module. It first needs to access the Ivy file of the module for which it resolves the dependencies.
Then, for each dependency declared in this file, it asks the appropriate resolver (according to settings) to find the module (i.e. either an Ivy file for it, or its artifacts if no Ivy file can be found). It also uses a filesystem based cache to avoid asking for a dependency if it is already in cache (at least if possible, which is not the case with latest revisions).
If the resolver is a composite one (i.e. a chain or a dual resolver), several resolvers may actually be called to find the module.
When the dependency module has been found, its Ivy file is downloaded to the Ivy cache. Then Ivy checks if the dependency module has dependencies, in which case it recursively traverses the graph of dependencies.
All over this traversal, conflict management is done to prevent access to a module as soon as possible.
When Ivy has traversed the whole graph, it asks the resolvers to download the artifacts corresponding to each of the dependencies which are not already in the cache and which have not been evicted by conflict managers. All downloads are made to the Ivy cache.
Finally, an XML report is generated in the cache, which allows Ivy to easily know what are all the dependencies of a module, without traversing the graph again.
After this resolve step, two main steps are possible: either build a path with artifacts in the cache, or copy them to another directory structure.
Retrieve
What is called retrieve in Ivy is the act of copying artifacts from the cache to another directory structure. This is done using a pattern, which indicates to Ivy where the files should be copied.
For this, Ivy uses the XML report in the cache corresponding to the module it should retrieve to know which artifacts should be copied.
It also checks if the files are not already copied to maximize performances.
Building a path from the cache
In some cases, it is preferable to use artifacts directly from the cache. Ivy is able to use the XML report generated at resolve time to build a path of all artifacts required.
This can be particularly useful when building plug-ins for IDEs.
Reports
Ivy is also able to generate readable reports describing the dependencies resolution.
This is done with a simple XSL transformation of the XML report generated at resolve time.
Publish
Finally, Ivy can be used to publish a particular version of a module in your repository, so that it becomes available for future resolving. This task is usually called either manually or from a continuous integration server.
Best practices
Here are some recommendations and best practices we have gathered throughout our experience and consultancies with our customers.
Add module descriptors for all your modules
In Ivy world, module descriptors are Ivy files, which are basically simple XML files describing both what the module produces as artifacts and its dependencies.
It is a good practice to write or download module descriptors for all the modules involved in your development, even for your third party dependencies, and even if they don’t provide such module descriptors themselves.
First, it will seem like extra work and require time. But when you have several modules using the same third party library, then you will only need to add one line to your Ivy file to get this library and all its own dependencies that you really need (if you have good module descriptors in your repository, especially with the use of module configurations). It will also be very helpful when you want to upgrade a dependency. One single change in your module Ivy file and you will get the updated version with its updated (or not) dependencies.
Therefore we recommend adding Ivy files for all the modules in your repository. You can even enforce this rule by setting the descriptor attribute to required on your resolvers. Hence you shouldn’t need to use the dependency artifact inclusion/exclusion/specification feature of Ivy, which should only be used in very specific cases.
Use your own enterprise repository
This is usually not a valid recommendation for open source projects, but for the enterprise world we strongly suggest to avoid relying on a public repository like Maven ibiblio or ivyrep. Why? Well, there are a couple of reasons:
Control
The main problem with these kinds of public repositories is that you don’t have control over the repository. This means that if a module descriptor is broken you cannot easily fix it. Sure you can use a chain between a shared repository and the public one and put your fixed module descriptor in the shared repository so that it hides the one on the public repository, but this makes repository browsing and maintenance cumbersome.
Even more problematic is the possible updates of the repository. We know that versions published in such repositories should be stable and not be updated, but we also frequently see that a module descriptor is buggy, or an artifact corrupted. We even see sometimes a new version published with the same name as the preceding one because the previous one was simply badly packaged. This can occur even to the best; it occurred to us with Ivy 1.2 :-) But then we decided to publish the new version with a different name, 1.2a. But if the repository manager allows such updates, this means that what worked before can break. It can thus break your build reproducibility.
Reliability
The Maven repository is not particularly well known for its reliability (we often experience major slow downs or even complete failures of the site), and ivyrep is only supported by a small company (yes we are only a small company!). So slow down and site hangs occur also. And if the repository you rely on is down, this can cause major slow downs in your development or release process.
Accuracy
A public repository usually contains much more than what you actually need. Is this a problem? We think so. We think that in an enterprise environment the libraries you use should step through some kind of validation process before being used in every projects of your company. And what better way to do so? Setup an enterprise repository with only the libraries you actually want to use. This will not only ensure better quality for your application dependencies, but help to have the same versions everywhere, and even help when declaring your module dependencies, if you use a tool like IvyDE, the code completion will only show relevant information about your repository, with only the libraries you actually want to see.
Security
The artifacts you download from a module repository are often executable, and are thus a security concern. Imagine a hacker replacing commons-lang by another version containing a virus? If you rely on a public repository to build your software, you expose it to a security risk. You can read more about that in this Forrester article.
Note that using an enterprise repository doesn’t mean you have to build it entirely by hand. Ivy features an install task which can be used to install modules from one repository to another one, so it can be used to selectively install modules from a public repository to your enterprise repository, where you will then be able to ensure control, reliability and accuracy.
Always use patterns with at least organisation and module
Ivy is very flexible and can accommodate a lot of existing repositories, using the concept of patterns. But if your repository doesn’t exist yet, we strongly recommend always using the organisation and the module name in your pattern, even for a private repository where you put only your own modules (which all have the same organisation). Why? Because the Ivy listing feature relies on the token it can find in the pattern. If you have no organisation token in your pattern, Ivy won’t be able to list the (only?) organisation in your repository. And this can be a problem for code completion in IvyDE, for example, but also for repository wide tasks like install or repreport.
Public ivysettings.xml with public repositories
If you create a public repository, provide a URL to the ivysettings.xml file. It’s pretty easy to do, and if someone wants to leverage your repository, (s)he will just have to load it with settings with the URL of your ivysettings.xml file, or include it in its own settings file, which makes it really easy to combine several public repositories.
Dealing with integration versions
Very often, especially when working in a team or with several modules, you will need to rely on intermediate, non-finalized versions of your modules. These versions are what we call integration versions, because their main objective is to be integrated with other modules to make and test an application or a framework.
If you follow the continuous integration paradigm across modules, these integration versions can be produced by a continuous integration server, very frequently.
So, how can you deal with these, possibly numerous, integration versions?
There are basically two ways to deal with them, both ways being supported by Ivy:
- use a naming convention like a special suffix
-
the idea is pretty simple, each time you publish a new integration of your module you give the same name to the version (in Maven world this is for example 1.0-SNAPSHOT). The dependency manager should then be aware that this version is special because it changes over time, so that it does not trust its local cache if it already has the version, but checks the date of the version on the repository and sees if it has changed. In Ivy this is supported using the changing attribute on a dependency or by configuring the changing pattern to use for all your modules.
- automatically create a new version for each
-
in this case you use either a build number or a timestamp to publish each new integration version with a new version name. Then you can use one of the numerous ways in Ivy to express a version constraint. Usually selecting the very latest one (using 'latest.integration' as version constraint) is enough.
So, which way is the best? As often, it depends on your context, and if one of the two was really bad it wouldn’t be supported in Ivy :-)
But usually we recommend using the second one, because using a new version each time you publish a new version better fits the version identity paradigm, and can make all your builds reproducible, even integration ones. And this is interesting because it enables, with some work in your build system, the ability to introduce a mechanism to promote an integration build to a more stable status, like a milestone or a release.
Imagine you have a customer who comes on a Monday morning and asks for the latest version of your software, for testing or demonstration purposes. Obviously he needs it for the afternoon :-) Now if you have a continuous integration process and good tracking of your changes and your artifacts, it may occur to you that you are actually able to fulfill his request without needing the use of a DeLorean to give you some more time :-) But it may also occur to you that your latest version is stable enough to be used for the purpose of the customer, but was actually built a few days ago, because the very latest just broke a feature or introduced a new one you don’t want to deliver. You can deliver this 'stable' integration build if you want, but rest assured that a few days, or weeks, or even months later, the customer will ask for a bug fix on this demo only version. Why? Because it’s a customer, and we all know how they are :-)
So, with a build promotion feature of any build in your repository, the solution would be pretty easy: when the customer asks for the version, you not only deliver the integration build, but you also promote it to a milestone status, for example. This promotion indicates that you should keep track of this version for a long period, to be able to come back to it and create a branch if needed.
Unfortunately Ivy does not by its own allow you to have such reproducible builds out of the box, simply because Ivy is a dependency manager, not a build tool. But if you publish only versions with a distinct name and use Ivy features like versions constraint replacement during the publication or recursive delivery of modules, it can really help.
On the other hand, the main drawback of this solution is that it can produce a lot of intermediate versions, and you will have to run some cleaning scripts in your repository unless your company name starts with a G and ends with oogle :-)
Inlining dependencies or not?
With Ivy 1.4 you can resolve a dependency without even writing an Ivy file. This practice is called inlining. But what is it good for, and when should it be avoided?
Putting Ivy dependencies in a separate file has the following advantages:
- separate revision cycle
-
if your dependencies may change more often than your build, it’s a good idea to separate the two, to isolate the two concepts: describing how to build / describing your project dependencies
- possibility to publish
-
if you describe dependencies of a module which can itself be reused, you may want to use ant to publish it to a repository. In this case the publication is only possible if you have a separate Ivy file
- more flexible
-
inline dependencies can only be used to express one dependency and only one. An Ivy file can be used to express much more complex dependencies
On the other hand, using inline dependencies is very useful when:
- you want to use a custom task in your ant build
-
Without Ivy you usually either copy the custom task jar in ant lib, which requires maintenance of your workstation installation, or use a manual copy or download and a taskdef with the appropriate classpath, which is better. But if you have several custom tasks, or if they have themselves dependencies, it can become cumbersome. Using Ivy with an inline dependency is an elegant way to solve this problem.
- you want to easily deploy an application
-
If you already build your application and its modules using Ivy, it is really easy to leverage your Ivy repository to download your application and all its dependencies on the local filesystem, ready to be executed. If you also put your settings files as artifacts in your repository (maybe packaged as a zip), the whole installation process can rely on Ivy, easing the automatic installation of any version of your application available in your repository!
Hire an expert
Build and dependency management is often given too low a priority in the software development world. We often see build management implemented by developers when they have time. Even if this may seem like a time and money savings in the short term, it often turns out to be a very bad choice in the long term. Building software is not a simple task, when you want to ensure automatic, tested, fully reproducible builds, releases and installations. On the other hand, once a good build system fitting your very specific needs is setup, it can then only rely on a few people with a good understanding of what is going on, with a constant quality ensured.
Therefore hiring a build and dependency expert to analyse and improve your build and release system is most of the time a very good choice.
Feedback
These best practices reflect our own experience, but we do not pretend to own the unique truth about dependency management or even Ivy use.
So feel free to comment on this page to add your own experience feedback, suggestions or opinion.
JVM compatibility
Up to Ivy 2.3.x, a minimum of Java 1.4 is required.
For Ivy 2.4.0, a minimum of Java 5 is required.
Since Ivy 2.5.0, a minimum of Java 7 is required.
Apache Ant
Ivy doesn’t require a specific version of Ant as long as the Ant being used complies with the JVM compatibility requirements noted above.
Other optional dependencies
The required versions of the Apache HttpClient, Jsch or any optional dependency are to be checked against Ivy’s dependency descriptor. In Ivy’s source, check for the ivy.xml file at the root. Or the pom.xml of org.apache.ivy#ivy in the Maven Central repository.
Environment / Configuration Requirements
Ivy does not at this time support multithreaded use. It thus should not be used with the Ant <parallel> task.
Manually
Download the version you want here, unpack the downloaded zip file wherever you want, and copy the Ivy jar file into your Ant lib directory (ANT_HOME/lib).
If you use Ant 1.6.0 or superior, you can then simply go to the src/example/hello-ivy dir and run Ant: if the build is successful, you have successfully installed Ivy!
If you use Ant 1.5.1 or superior, you have to modify the build files in the examples:
-
remove the namespace section at their head:
xmlns:ivy="antlib:org.apache.ivy.ant" -
add taskdefs for Ivy tasks:
<taskdef name="ivy-configure" classname="org.apache.ivy.ant.IvyConfigure"/>
<taskdef name="ivy-resolve" classname="org.apache.ivy.ant.IvyResolve"/>
<taskdef name="ivy-retrieve" classname="org.apache.ivy.ant.IvyRetrieve"/>
<taskdef name="ivy-publish" classname="org.apache.ivy.ant.IvyPublish"/>-
replace ivy:xxx tasks by ivy-xxx You can now run the build, if it is successful, you have successfully installed Ivy!
If the build is not successful, check the FAQ to see what might be the problem with the ivyrep resolver.
Ivy dependencies
One of the two binary versions of Ivy doesn’t include the optional dependencies. To download them using Ivy, all you need is to run the Ant build file provided in the distribution. This will use Ivy itself to download the dependencies. Then you should see the Ivy optional dependencies in the lib directory, organized per configuration (see the ivy.xml for details about the configurations and their use).
Automatically
If you want to use Ivy only in your Ant build scripts, and have an internet connection when you build, you can download Ivy from this site and use the downloaded version automatically, using this simple build snippet:
<project xmlns:ivy="antlib:org.apache.ivy.ant">
<property name="ivy.install.version" value="2.5.0"/>
<condition property="ivy.home" value="${env.IVY_HOME}">
<isset property="env.IVY_HOME"/>
</condition>
<property name="ivy.home" value="${user.home}/.ant"/>
<property name="ivy.jar.dir" value="${ivy.home}/lib"/>
<property name="ivy.jar.file" value="${ivy.jar.dir}/ivy.jar"/>
<target name="download-ivy" unless="offline">
<mkdir dir="${ivy.jar.dir}"/>
<!-- download Ivy from web site so that it can be used even without any special installation -->
<get src="https://repo1.maven.org/maven2/org/apache/ivy/ivy/${ivy.install.version}/ivy-${ivy.install.version}.jar"
dest="${ivy.jar.file}" usetimestamp="true"/>
</target>
<target name="init-ivy" depends="download-ivy">
<!-- try to load Ivy here from Ivy home, in case the user has not already dropped
it into Ant's lib dir (note that the latter copy will always take precedence).
We will not fail as long as local lib dir exists (it may be empty) and
Ivy is in at least one of Ant's lib dir or the local lib dir. -->
<path id="ivy.lib.path">
<fileset dir="${ivy.jar.dir}" includes="*.jar"/>
</path>
<taskdef resource="org/apache/ivy/ant/antlib.xml"
uri="antlib:org.apache.ivy.ant" classpathref="ivy.lib.path"/>
</target>
</project>Then the only thing to do is to add the init-ivy target in the depends attribute of your targets using Ivy, and add the ivy namespace to your build script. See the self contained go-ivy example for details about this.
Java System Properties Affecting Ivy
XML Parser Settings
Starting with Ivy 2.5.2 Ivy’s XML parser can be controlled via the use of two newly introduced system properties.
If you want to restore the default behavior of Ivy 2.5.1 and earlier
you need to set ivy.xml.allow-doctype-processing to true and
ivy.xml.external-resources to ALL.
ivy.xml.allow-doctype-processing
This system property accepts true or false as values. When set to
false Ivy will not allow any processing of doctype declarations at
all, while setting it to true enables it.
The default is to allow doctype processing if and only if Ivy is parsing a Maven POM file.
ivy.xml.external-resources
This system property controls if external resources are read during
doctype processing - and if so, where they can be loadad from. The
value of this system property is only ever used if
ivy.xml.allow-doctype-processing is not false.
The accepted values are
-
PROHIBITmakes Ivy fail if any doctype tries to load an external resource. -
IGNOREmakes Ivy ignore any external resource that the doctype declaration wants to load. -
LOCAL_ONLYallows external resources to be loaded viafile:orjar:fileURIs only. -
ALLallows external resources to be loaded from any URI.
The default behavior is to not allow doctype processing at all, but if
it is enabled the value PROHIBIT is assumed unless the property has
been set explicitly.
When reading Maven POMs a specific internal system id is recognized as resource and will be loaded from a resource shipping with the Ivy distribution in order to deal with invalid POM files accepted by Apache Maven - and the default value for this property is `IGNORE`in that case. See IVY-921 for details.
Ivy Settings
In order to work as you want, Ivy sometimes needs some settings. Actually, Ivy can work with no specific settings at all, see the default settings documentation for details about that. But Ivy is able to work in very different contexts. You just have to configure it properly.
Settings are specified through an XML file, usually called ivysettings.xml. To configure Ivy from Ant, you just have to use the settings datatype with the path of your settings file.
In addition certain Java system properties affect the XML parsing behavior of Ivy.
Here is an example of the settings file:
<ivysettings>
<properties file="${ivy.settings.dir}/ivysettings-file.properties"/>
<settings defaultResolver="ibiblio"/>
<caches defaultCacheDir="${cache.dir}" checkUpToDate="false"/>
<resolvers>
<ibiblio name="ibiblio"/>
<filesystem name="internal">
<ivy pattern="${repository.dir}/[module]/ivy-[revision].xml"/>
<artifact pattern="${repository.dir}/[module]/[artifact]-[revision].[ext]"/>
</filesystem>
</resolvers>
<modules>
<module organisation="jayasoft" name=".*" resolver="internal"/>
</modules>
</ivysettings>Note: To work, this settings file needs a property file named ivysettings-file.properties in the same directory as the settings file, with Ivy variables you want in it.
Mainly, the settings enable you to configure the default cache directory used by Ivy and the dependency resolvers that it will use to resolve dependencies.
Some useful variables are available for use in settings files:
-
ivy.settings.dir
this variable references the directory in which the settings file itself is. This is available if the settings has been loaded as a file. In case of a URL, it takes the part before the last slash of the URL, if any. If the URL has no slash, then this variable is not set. -
ivy.settings.file
the path of the settings file itself if it has been loaded as a file only. If it has been loaded as a URL, this variable is not set. -
ivy.settings.url
the URL pointing to the settings file. This is set both when it has been loaded as a file or a URL.
(since 1.4) Note that all Java system properties are available as Ivy variables in your settings file.
Settings file structure
The settings file is structured in some parts and left open in others. In fact, each resolver has its own structure, thus it’s not the settings file itself which defines the structure for the resolvers.
ivysettings
ivysettings
Tag: ivysettings
Root tag of any Ivy settings file.
Child elements
| Element | Description | Cardinality |
|---|---|---|
set an Ivy variable |
0..n |
|
loads a properties file as Ivy variables |
0..n |
|
configures Ivy with some defaults |
0..1 |
|
includes another settings file |
0..n |
|
add a location in the classpath used to load plugins |
0..n |
|
defines new types in Ivy |
0..n |
|
defines lock strategies |
0..1 |
|
defines repository cache managers |
0..1 |
|
defines latest strategies |
0..1 |
|
defines module descriptor parsers |
0..1 |
|
defines new namespaces |
0..1 |
|
defines a new macro resolver |
0..n |
|
defines dependency resolvers |
0..1 |
|
defines conflict managers |
0..1 |
|
defines rules between modules and dependency resolvers |
0..1 |
|
defines the list of available report outputters |
0..1 |
|
defines the list of available statuses |
0..1 |
|
register triggers on Ivy events |
0..1 |
|
defines new version matchers |
0..1 |
|
defines the list of available timeout-constraints |
0..n |
property
Tag: property
Defines an Ivy variable.
(since 1.3) The optional override attribute enables you to avoid overriding the previous value of the variable, which makes the definition to behave like an Ant property, which is particularly useful to define default values (values which are used only if they haven’t been defined yet).
Attributes
| Attribute | Description | Required |
|---|---|---|
name |
the name of the variable to define |
Yes |
value |
the new value the variable must take |
Yes |
override |
true if the previous value (if any) of the variable should overridden, false otherwise |
No, defaults to true |
ifset |
the variable will be set only if the provided 'ifset' variable is already set (since 2.4) |
No |
unlessset |
the variable will not be set unless the provided 'unlessset' variable is set (since 2.4) |
No |
Examples
<property name="myvar" value="myvalue"/>Sets the variable myvar to the value myvalue.
<property name="myvar" value="myvalue" override="false"/>Sets the variable myvar to the value myvalue only if myvar has not been set yet.
<properties environment="env"/>
<property name="ivy.repos.server" value="${env.IVY_SERVER}" override="false" ifset="env.IVY_SERVER"/>
<property name="ivy.repos.server" value="http://ivy:8081" override="false"/>If the environment variable is set, it takes precedence over of default value.
properties
Tag: properties
Loads a properties file into Ivy variables. See the variables chapter above for details about Ivy variables.
(since 2.0) It is possible to access environment variables. This can be done by specifying the environment attribute. This attribute specifies the prefix which can be used to access these environment variables. For instance, if you specify environment="env", you can access the PATH environment variable with the env.PATH property name.
Attributes
| Attribute | Description | Required |
|---|---|---|
file |
a path to a properties file to load |
One of these |
environment |
the prefix to use when retrieving environment variables (since 2.0) |
|
override |
indicates if the variable found in the properties file should override its previous value, if any (since 1.3) |
No, defaults to true |
settings
Tag: settings
Configures some important Ivy behaviour: default resolver, latest strategy, conflict manager and some others.
The default resolver is used whenever nothing else is configured in the modules section of the settings file. It should give the name of a dependency resolver defined in the resolvers section of the settings file.
The default latest strategy and conflict manager can also be configured here.
validate indicates if Ivy files should generally be validated against the Ivy XSD or not. This setting is only a default value, and can be overridden:
-
in Ant tasks
-
in resolvers
So if there is a setting in the resolver, it always wins against all other settings.
Attributes
| Attribute | Description | Required |
|---|---|---|
defaultResolver |
the name of the default resolver to use |
No, but all modules should be configured in the modules section if not provided |
defaultLatestStrategy |
the name of the default latest strategy to use |
No, defaults to latest-revision |
defaultConflictManager |
the name of the default conflict manager to use |
No, defaults to latest-revision |
defaultBranch |
the default branch to use for all modules, except if they have a module specific branch setting. (since 1.4) |
No, defaults to no default branch |
defaultResolveMode |
the default resolve mode to use for all modules, except if they have a module specific resolve mode setting. (since 2.0) |
No, defaults to 'default' |
the name of the circular dependency strategy to use (since 1.4) |
No, defaults to warn |
|
validate |
Indicates if Ivy files should be validated against ivy.xsd or not. |
No, defaults to true |
useRemoteConfig |
true to configure ivyrep and ibiblio resolver from a remote settings file (updated with changes in those repository structure if any) (since 1.2) |
No, defaults to false |
httpRequestMethod |
specifies the HTTP method to use to retrieve information about an URL. Possible values are 'GET' and 'HEAD'. This setting can be used to solve problems with firewalls and proxies. (since 2.0) |
No, defaults to 'HEAD' |
defaultCache |
a path to a directory to use as default basedir for both resolution and repository cache(s). |
No, defaults to .ivy2/cache in user home |
checkUpToDate |
Indicates if date should be checked before retrieving artifacts from cache. |
No, defaults to true |
cacheIvyPattern |
a pattern to indicate where Ivy files should be put in cache. |
No, defaults to [organisation]/[module]/ivy-[revision].xml |
cacheArtifactPattern |
a pattern to indicate where artifact files should be put in cache. |
No, defaults to [organisation]/[module]/[type]s/[artifact]-[revision].[ext] |
include
Tag: include
[since 1.3]
Includes another Ivy settings file as if it were part of this one.
The included Ivy settings file has to be a complete well formed Ivy settings file, i.e. it does have to include the <ivysettings> tag.
Attributes
| Attribute | Description | Required |
|---|---|---|
url |
a URL to the Ivy settings file to include |
Yes, unless file is specified |
file |
a path to the Ivy settings file to include |
Yes, unless url is specified |
optional |
indicates whether Ivy should throw an error if the specified file doesn’t exist (since 2.4). |
No, default to false |
Examples
<ivysettings>
<property name="myrepository" value="path/to/my/real/rep"/>
<settings defaultResolver="default"/>
<include file="path/to/ivysettings-default.xml"/>
</ivysettings>with ivysettings-default.xml:
<ivysettings>
<property name="myrepository" value="path/to/rep" overwrite="false"/>
<resolvers>
<ivyrep name="default" ivyroot="${myrepository}"/>
</resolvers>
</ivysettings>The included Ivy settings defines a resolver named default, which is an ivyrep resolver, with its root configured as being the value of myrepository variable. This variable is given the value path/to/rep in the included file, but because the attribute overwrite is set to false, it will not override the value given in the main Ivy settings including this one, so the value used for myrepository will be path/to/my/real/rep.
<ivysettings>
<include file="ivysettings-macro.xml"/>
<resolvers>
<mymacro name="includeworks" mymainrep="included/myrep" mysecondrep="included/secondrep"/>
</resolvers>
</ivysettings>with ivysettings-macro.xml being the Ivy settings example given on the macrodef documentation page. This lets us easily reuse the custom macro resolver.
classpath
Tag: classpath
[since 1.4]
Includes a jar in the classpath used to load plugins.
This lets you add Ivy plugins without relying on an external classpath (the Ant classpath, for instance), therefore easing the use of Ivy in multiple execution environments (Ant, standalone, IDE plugins, …).
Attributes
| Attribute | Description | Required |
|---|---|---|
url |
the URL of a jar to add to the classpath |
Yes, unless file is specified |
file |
a jar to add to the classpath |
Yes, unless url is specified |
Examples
<ivysettings>
<classpath file="${ivy.settings.dir}/custom-resolver.jar"/>
<typedef name="custom" classname="org.apache.ivy.resolver.CustomResolver"/>
<resolvers>
<custom name="custom"/>
</resolvers>
</ivysettings>Adds the custom-resolver.jar (found in the same directory as the ivysettings.xml file) to the classpath, then defines a custom resolver and uses it.
<ivysettings>
<classpath url="http://www.myserver.com/ivy/custom-resolver.jar"/>
<typedef name="custom" classname="org.apache.ivy.resolver.CustomResolver"/>
<resolvers>
<custom name="custom"/>
</resolvers>
</ivysettings>Same as above, but finds the jar on a web server.
typedef
Tag: typedef
Defines a new type in Ivy. Useful to define new dependency resolvers, in particular, but also latest strategies. See how to write and plug your own dependency resolver for details.
Attributes
| Attribute | Description | Required |
|---|---|---|
name |
the name of the type to define. This name is then used as an xml tag. |
Yes |
classname |
the fully qualified class name of the type to define. |
Yes |
credentials
Tag: credentials
[since 2.0]
Configures HTTP authentication credentials.
Attributes
| Attribute | Description | Required |
|---|---|---|
host |
the name of the host |
Yes |
realm |
the name of the realm |
No |
username |
the username |
Yes |
passwd |
the password |
Yes |
signers
Tag: signers
[since 2.2]
Defines a list of detached signature generators usable in Ivy. Each generator is identified by its name, given as an attribute. The child tags used to configure the signature generator must be equal to the name of a signature generator type (either built-in or added with the typedef tag).
Ivy supports the following signature generator out of the box:
-
pgp
generates an OpenPGP compatible ASCII armored detached signature.
Child elements
| Element | Description | Cardinality |
|---|---|---|
any signature generator |
adds a signature generator to the list of registered generators |
1..n |
Built-in Generators
PGP
This generator is capable of generating an OpenPGP compatible ASCII armored detached signature.
Remark: This generator uses the BouncyCastle OpenPGP library. Before this generator can be used, the library and its JCE provider library must be available on Ivy’s classpath.
| Attribute | Description | Required |
|---|---|---|
name |
The name of the signature generator. |
Yes |
secring |
The location of the secret keyring. |
No, defaults to |
keyId |
The identifier of the key to use. The keyword |
No, defaults to |
password |
The password of the private key. |
Yes |
Examples
<signers>
<pgp name="mypgp" password="my-password"/>
</signers>Defines a detached signature generator with name 'mypgp' which uses the secret key ring on the default location and automatically selects a private key.
<signers>
<pgp name="mypgp" password="my-password" keyId="123ABC45"/>
</signers>Same as before, but this time the key 123ABC45 is used to generate the detached signature.
Lock Strategies
Tag: lock-strategies
[since 2.0]
Defines a list of lock strategies usable in Ivy.
A lock strategy is used by a cache manager to decide when and how locking should be performed (see caches to see how to configure the lock strategy to use).
The following strategies are registered by default:
-
no-lock
This lock strategy actually performs no locking at all, and thus should not be used in an environment where the cache is shared by multiple processes. -
artifact-lock
This strategy acquires a lock whenever a module descriptor or an artifact is downloaded to the cache, which makes a good solution when you want to share your repository cache. Note that this strategy is based on file locking, performed by default using thejava.io.File.createNewFile()atomicity (which is documented as atomic in the javadoc, but not recommended to perform locks). -
artifact-lock-nio (since 2.4)
Like theartifact-lockstrategy, this one also acquires a lock whenever a module descriptor or artifact is downloaded to the cache. But here the implementation is done with ajava.nio.FileLock.
The child tag used for the lock strategy must be equal to a name of a lock strategy type (added with the typedef tag).
Child elements
| Element | Description | Cardinality |
|---|---|---|
any lock strategy |
adds a lock strategy to the list of available ones |
0..n |
caches
Tag: caches
[since 2.0]
Configures the Ivy cache system.
See cache concept for details on the Ivy cache concept.
By default, Ivy defines one repository cache instance, called default-cache, which uses the default cache settings defined using attributes on this tag. This default instance is defined as long as you don’t define your own default cache using the default attribute, and have at least one dependency resolver which doesn’t specify which cache instance to use.
defaultCacheDir is the default directory used for both the resolution and repository cache(s). It usually points to a directory in your filesystem. If you want to isolate resolution cache from repository cache, we recommend setting both the resolutionCacheDir and repositoryCacheDir attributes on this tag instead of using defaultCacheDir.
Since repository cache implementations are pluggable, you can either define new cache instances based on the default implementation provided in Ivy using the cache child element, or use custom cache implementations using child elements as you have defined using typedef.
ivyPattern and artifactPattern are used to configure the default way Ivy stores Ivy files and artifacts in repository cache(s). Usually you do not have to change this, unless you want to use the cache directly from another tool, which is not recommended. These patterns are relative to the repository cache base directory.
checkUpToDate indicates to Ivy if it must check date of artifacts before retrieving them (i.e. copying them from cache to another place in your filesystem). Usually it is a good thing to check date to avoid unnecessary copy, even if it’s most of the time a local copy.
Attributes
| Attribute | Description | Required |
|---|---|---|
default |
the name of the default cache to use on all resolvers not defining the cache instance to use |
No, defaults to a default cache manager instance named 'default-cache' |
defaultCacheDir |
a path to a directory to use as default basedir for both resolution and repository cache(s) |
No, defaults to .ivy2/cache in the user’s home directory |
resolutionCacheDir |
the path of the directory to use for all resolution cache data |
No, defaults to defaultCacheDir |
repositoryCacheDir |
the path of the default directory to use for repository cache data. This should not point to a directory used as a repository! |
No, defaults to defaultCacheDir |
ivyPattern |
default pattern used to indicate where Ivy files should be put in the repository cache(s) |
No, defaults to [organisation]/[module]/ivy-[revision].xml |
artifactPattern |
default pattern used to indicate where artifact files should be put in the repository cache(s) |
No, defaults to [organisation]/[module]/[type]s/[artifact]-[revision].[ext] |
checkUpToDate |
Deprecated, we recommend using overwriteMode on the retrieve task instead. Indicates if date should be checked before retrieving artifacts from cache. |
No, defaults to true |
useOrigin |
the default value to use for useOrigin for caches in which it isn’t specifically defined. Use true to avoid the copy of local artifacts to the cache and use directly their original location. |
No, defaults to false |
lockStrategy |
the name of the default lock strategy to use when accessing repository cache(s) |
No, defaults to no-lock |
Child elements
| Element | Description | Cardinality |
|---|---|---|
defines a new repository cache instance, based on the default repository cache implementation |
0..n |
Examples
<caches>
<cache name="mycache" basedir="path/to/my/cache/1"/>
<cache name="mycache2" basedir="path/to/my/cache/2"/>
</caches>Define 2 cache instances, named mycache and mycache2, using two different directories as base directory, and using the default patterns and lock strategies. The default cache instance will still be defined as long as at least one dependency resolver does not declare which cache manager to use.
cache
Tag: cache
[since 2.0]
Defines a repository cache instance based on the default repository cache implementation.
The default repository cache implementation caches files on the local filesystem in subdirectories of a configured base directory.
By default also, the parsed module descriptors read from the cache are kept in a memory cache in case they are reused. This may enhance the performance of multi-module build, provided that all modules are built using the same Ivy instance. The size of this memory cache is configurable in terms of number of module descriptors. A size of 0 means no memory caching.
Attributes
| Attribute | Description | Required |
|---|---|---|
name |
name of the cache instance |
Yes |
basedir |
the path of the base directory to use to put repository cache data. This should not point to a directory used as a repository! |
No, defaults to repositoryCacheDir defined in caches |
ivyPattern |
the pattern to use to store cached Ivy files |
No, defaults to default cache Ivy pattern as configured in caches |
artifactPattern |
the pattern to use to store cached artifacts |
No, defaults to default cache artifact pattern as configured in caches |
useOrigin |
true to avoid the copy of local artifacts to the cache and use directly their original location, false otherwise. To know if an artifact is local, Ivy asks the resolver. Only filesystem resolver is considered local by default, but this can be disabled if you want to force the copy on one filesystem resolver and use the original location on another. Note that it is safe to use useOrigin even if you use the cache for some non local resolvers. In this case the cache will behave as usual, copying files to the cache. Note also that this only applies to artifacts, not to Ivy files, which are still copied in the cache. |
No. defaults to the default value configured in caches |
lockStrategy |
the name of the lock strategy to use for this cache |
No, defaults to default lock strategy as configured in caches |
defaultTTL |
the default TTL to use when no specific one is defined |
No, defaults to ${ivy.cache.ttl.default} |
memorySize |
the number of parsed module descriptors to keep in a memory cache. |
No, default to 150 |
Child elements
| Element | Description | Cardinality |
|---|---|---|
defines a TTL rule |
0..n |
Examples
<cache name="mycache"
basedir="/path/to/mycache"
ivyPattern="[module]/ivy-[revision].xml"
artifactPattern="[module]/[artifact]-[revision].[ext]"
lockStrategy="no-lock"
defaultTTL="1s">
<ttl revision="latest.integration" duration="200ms"/>
<ttl organisation="org1" duration="10m 20s"/>
<ttl organisation="org2" duration="5h"/>
<ttl organisation="org3" duration="2d 12h"/>
</cache>Defines a cache called mycache, storing files in the /path/to/mycache directory using [module]/ivy-[revision].xml as a pattern to store Ivy files and [module]/[artifact]-[revision].[ext] as a pattern to store other artifacts. The lock strategy used by this cache is the no-lock strategy, which does not perform any locking. The defaultTTL used is 1 s, meaning that by default dynamic revision result will be stored and used for one second. TTL rules then define that all latest.integration revisions will be stored and used for 200 ms, while other dynamic revisions from org1 org2 and org3 modules will be stored respectively for 10 minutes 20 seconds; 5 hours; and 2 days and 12 hours.
ttl
Tag: ttl
[since 2.0]
Defines a TTL (Time To Live) rule for resolved revision caching.
When Ivy resolves a dynamic version constraint (like latest.integration or a version range), it can store the result of the resolution (like latest.integration=1.5.1) for a given time, called TTL. It means that Ivy will reuse this dynamic revision resolution result without accessing the repositories for the duration of the TTL, unless running resolve in refresh mode.
This tag lets you define a rule to define a TTL specific to a set of dynamic revision, based on the whole module revision information (organization, module name, revision, …). The revision considered in the rule is the revision before the resolution (for instance, latest.integration) and not the resolved revision (for instance, 1.5.1).
The rules are evaluated in order, the first matching rule being used to define the TTL. If no rule matches, the cache defaultTTL will be used.
The format used to specify the TTL is of the form:
XXd XXh XXm XXs XXXmsWhere 'd' stands for days, 'h' for hours, 'm' for minutes, 's' for seconds and 'ms' for milliseconds. Any part of the specification can be omitted, so '12d', '2h 5m' and '1d 5ms' are all valid.
The TTL duration can also be set to eternal, in which case once resolved the revision is always use, except when resolving in refresh mode.
Using a 0ms TTL disable resolved revision caching for the given rule.
Attributes
| Attribute | Description | Required |
|---|---|---|
organisation |
the organisation to match to apply the rule. |
No, defaults to * |
module |
the module’s name to match to apply the rule. |
No, defaults to * |
revision |
the module’s revision to match to apply the rule. Note that the version is not resolved when evaluating the rule ('latest.integration', for instance). |
No, defaults to * |
any extra attribute |
an extra attribute to match to apply the rule. |
No, defaults to * |
matcher |
the matcher to use to match the modules to which the resolver should be applied |
No, defaults to exact |
duration |
the TTL to apply (see above for format) |
Yes |
Latest strategies
Tag: latest-strategies
Defines a list of latest strategies usable in Ivy. Each latest strategy is identified by its name, given as an attribute.
The child tag used for the latest strategy must be equal to a name of a latest strategy type (usually added with the typedef tag).
The latest strategies which are included in Ivy by default are:
-
latest-time
compares the revision dates to know which is the latest. While this is often a good strategy in terms of pertinence, its drawback is that it can be slow when dealing with remote repositories. If you use ivyrep, for example, Ivy has to ask the HTTP server for the date of each Ivy file before knowing which is the latest. -
latest-revision
compares the revisions as strings, using an algorithm close to the one used in PHPversion_comparefunction. This algorithm takes into account the special meaning of some text. For instance, with this strategy,1.0-dev1is considered before1.0-alpha1, which in turn is before1.0-rc1, which is before1.0, which is before1.0.1. -
latest-lexico
compares the revisions as strings using lexicographic order (the one used by Java string comparison).
Child elements
| Element | Description | Cardinality |
|---|---|---|
any latest strategy |
adds a latest strategy to the list of available strategies |
0..n |
latest-revision
[since 1.4]
The latest-revision can now be configured to handle more words with special meanings than the one defined in PHP version_compare function.
Here is an example of how you can do so:
<latest-strategies>
<latest-revision name="mylatest-revision">
<specialMeaning name="PRE" value="-2"/>
<specialMeaning name="QA" value="4"/>
<specialMeaning name="PROD" value="5"/>
</latest-revision>
</latest-strategies>Knowing that the default "special meaning" words are the following:
<specialMeaning name="dev" value="-1"/>
<specialMeaning name="rc" value="1"/>
<specialMeaning name="final" value="2"/>You can even remove or redefine the default special meanings by setting usedefaultspecialmeanings="false" on the latest-revision tag.
Example:
<latest-strategies>
<latest-revision name="mylatest-revision" usedefaultspecialmeanings="false">
<specialMeaning name="pre" value="-2"/>
<specialMeaning name="m" value="1"/>
<specialMeaning name="rc" value="2"/>
<specialMeaning name="prod" value="3"/>
</latest-revision>
</latest-strategies>parsers
Tag: parsers
Defines a list of module descriptor parsers usable in Ivy. Each parser defines which resources (which descriptor file) it accepts.
The child tag used for the parser must be equal to a name of a parser type (added with the typedef tag).
Note that when looking for a parser, Ivy queries the parsers list in the reverse order. So the last parser in the list will be queried first. Consequently, if the last parser accepts all resources, the other parsers will never have a chance to parse the resource.
Two parsers are available by default and thus do not need to be declared in this section:
-
Ivy file parser
this is the parser used for Ivy XML files. This parser is used for resources that aren’t accepted by any other parser. -
POM parser
this parser is able to parse Maven 2 POM XML files
Child elements
| Element | Description | Cardinality |
|---|---|---|
any module descriptor parser |
adds a module descriptor parser to the list of available parsers |
0..n |
namespaces
Tag: namespaces
Namespaces are an advanced feature of Ivy which let you use resolvers in which module names and organisations are not consistent between each other.
For instance, if you want to use both a Maven 2 repository and an ivyrep, you will face some naming issues. For example, all Apache Commons projects are declared to be part of the organisation apache in ivyrep whereas in Maven 2 ibiblio repository, their organisation is same as the module.
So if you try to use both Maven 2 and ivyrep repositories, you will face some issues like:
How do I declare a dependency on commons-lang? I have an error while trying to resolve module xxx. It says that it depends on [commons-httpclient commons-httpclient] and that it isn’t available.
Ivy’s answer to this issue is called namespaces. In short, you can attach a namespace to each dependency resolver in Ivy, and each namespace defines rules to convert names from the system namespace to the defined namespace itself, and vice versa.
This very powerful feature is thoroughly used in the build your own repository tutorial, so is the best place to see an example of what can be done with namespaces.
Child elements
| Element | Description | Cardinality |
|---|---|---|
defines a new namespace |
0..n |
namespace
Tag: namespace
Defines a new namespace. A namespace is identified by a name, which can be referenced by one of the resolvers.
An overview of namespaces is given in the namespaces documentation.
A namespace mainly consists of a list of rules, each rule defining a translation between a system namespace and the defined namespace, and vice versa.
There are two main possibilities for using these rules. By default, a namespace iterates through the rules, and when it finds one that translates the given name, it returns the translated name. But the namespace can be configured to use the list as a translator chain: in this case, all rules are applied in order, the result of the first rule translation being passed to the second, and so on.
Attributes
| Attribute | Description | Required |
|---|---|---|
name |
the namespace name |
Yes |
chainrules |
true to indicate that namespaces rules should be chained, false otherwise |
No, defaults to false |
Child elements
| Element | Description | Cardinality |
|---|---|---|
defines a new namespace rule |
0..n |
Example
<namespace name="test">
<rule>
<fromsystem>
<src org="systemorg"/>
<dest org="A"/>
</fromsystem>
<tosystem>
<src org="A"/>
<dest org="systemorg"/>
</tosystem>
</rule>
</namespace><namespace name="test">
<rule>
<fromsystem>
<src org="systemorg2" module="system\-(.+)"/>
<dest org="B" module="$m1"/>
</fromsystem>
<tosystem>
<src org="B" module=".+"/>
<dest org="systemorg2" module="system-$m0"/>
</tosystem>
</rule>
</namespace><namespace name="test" chainrules="true">
<rule>
<fromsystem>
<src org="systemorg"/>
<dest org="A"/>
</fromsystem>
<tosystem>
<src org="A"/>
<dest org="systemorg"/>
</tosystem>
</rule>
<rule>
<fromsystem>
<src module="systemmod"/>
<dest module="A"/>
</fromsystem>
<tosystem>
<src module="A"/>
<dest module="systemmod"/>
</tosystem>
</rule>
<rule>
<fromsystem>
<src module="systemmod2"/>
<dest module="B"/>
</fromsystem>
<tosystem>
<src module="B"/>
<dest module="systemmod2"/>
</tosystem>
</rule>
</namespace>rule
Tag: rule
Defines a new namespace rule. A rule defines a translation between system namespace and the defined namespace, and vice versa.
See the namespace doc for details.
Child elements
| Element | Description | Cardinality |
|---|---|---|
defines the translation to apply from the system namespace to the defined namespace |
1 |
|
defines the translation to apply from the defined namespace to the system namespace |
1 |
fromsystem / tosystem
Tag: fromsystem / tosystem
Defines a one way translation rule, i.e. a translation from system namespace to the defined namespace or vice versa.
Child elements
src
Tag: src
Defines the matching part of a translation rule. If a name matches this src, it will be translated using the dest part.
Attributes
| Attribute | Description | Required |
|---|---|---|
org |
the organisation to match as a regexp |
No, defaults to .* |
module |
the module name to match as a regexp |
No, defaults to .* |
rev |
the revision to match as a regexp |
No, defaults to .* |
dest
Tag: dest
Defines the translation part of a translation rule. If a name has matched a corresponding src, it will be translated using this dest part.
The new names can contain references to groups of the matched name, using a slightly modified regexp syntax. In fact, referenced groups can be part of either the organisation, module or revision part of the original name. So, to reference the groups, you just have to add a letter identifying the part in which the group should be selected: o for organisation, m for module, and r for revision.
For instance, $o0 matches the whole matched organisation, and $m0 the whole matched module name. $o1 matches the first group of the matched organisation.
For details about regexp and groups, see the Pattern class documentation in the JDK.
Attributes
| Attribute | Description | Required |
|---|---|---|
org |
the new organisation name |
No, defaults to $o0 |
module |
the new module name |
No, defaults to $m0 |
rev |
the new revision |
No, defaults to $r0 |
Examples
<fromsystem>
<src org="systemorg2" module="system\-(.+)"/>
<dest org="B" module="$m1"/>
</fromsystem>Matches modules from systemorg2 which have a name beginning with system followed by a minus and anything else, and translate it to organisation B and module the part following system- of the original name.
macrodef
Tag: macrodef
[since 1.3]
Defines a new dependency resolver type based upon another. This definition is very similar to the macrodef feature of Ant for defining macro tasks.
This task eases the process of creating a new dependency resolver, because it avoids writing Java code.
It is generally used in combination with the include feature to help reuse a macro in multiple settings files.
A macro is defined by declaring an existing resolver within it. Then you can use attributes to pass parameters to the newly defined resolver type. Attributes are defined with a name, and optionally a default value, and are used using the following syntax:
@{attributename}Resolver names
Since you can use the same macro several times it can define several resolvers (in a chain, for instance), the resolver names need to be chosen carefully to avoid name conflicts (each resolver must have a unique name).
Here is how Ivy deals with the names of the resolvers defined in a macro:
-
if there is no name attribute on a resolver in the macrodef, then Ivy will use the name given when using the macro. This is what usually should be done for the main resolver defined in the macro
-
if there is a name attribute on a resolver in the macrodef, but this name doesn’t contain a
@{name}inside, then Ivy will use the provided name prefixed with the name of the macro separated by a dash -
if there is a name attribute on a resolver in the macrodef, and this name contains
@{name}somewhere, then Ivy will use this name, and replace@{name}with the name provided when using the macro.
Example:
<ivysettings>
<macrodef name="mymacro">
<chain>
<ibiblio name="ex1"/>
<ibiblio name="ex2.@{name}" m2compatible="true"/>
</chain>
</macrodef>
<resolvers>
<mymacro name="default"/>
<mymacro name="other"/>
</resolvers>
</ivysettings>This is equivalent to:
<ivysettings>
<resolvers>
<chain name="default">
<ibiblio name="default-ex1"/>
<ibiblio name="ex2.default" m2compatible="true"/>
</chain>
<chain name="other">
<ibiblio name="other-ex1"/>
<ibiblio name="ex2.other" m2compatible="true"/>
</chain>
</resolvers>
</ivysettings>Attributes
| Attribute | Description | Required |
|---|---|---|
name |
name of the resolver type created |
Yes |
Child elements
| Element | Description | Cardinality |
|---|---|---|
defines an attribute for the macro resolver |
0..n |
|
any resolver |
defines the base resolver upon which this macro is defined |
1 |
Examples
Defining a simple macro:
<macrodef name="mymacro">
<attribute name="mymainrep"/>
<filesystem name="fs1">
<ivy pattern="@{mymainrep}/[organisation]/[module]/[type]s/[artifact]-[revision].[ext]"/>
<artifact pattern="@{mymainrep}/[organisation]/[module]/[type]s/[artifact]-[revision].[ext]"/>
</filesystem>
</macrodef>Using it:
<resolvers>
<mymacro name="default" mymainrep="path/to/myrep"/>
</resolvers>A complete example:
<ivysettings>
<macrodef name="mymacro">
<attribute name="mymainrep"/>
<attribute name="mysecondrep"/>
<attribute name="myseconddirlayout" default="[organisation]/[module]/[type]s"/>
<chain>
<filesystem name="fs1">
<ivy pattern="@{mymainrep}/[organisation]/[module]/[type]s/[artifact]-[revision].[ext]"/>
<artifact pattern="@{mymainrep}/[organisation]/[module]/[type]s/[artifact]-[revision].[ext]"/>
</filesystem>
<filesystem name="fs2" latest="latest-time">
<ivy pattern="@{mysecondrep}/@{myseconddirlayout}/ivy-[revision].xml"/>
<artifact pattern="@{mysecondrep}/@{myseconddirlayout}/[artifact]-[revision].[ext]"/>
</filesystem>
</chain>
</macrodef>
<resolvers>
<mymacro name="default" mymainrep="path/to/myrep" mysecondrep="path/to/secondrep"/>
<mymacro name="other"
mymainrep="path/to/myrep"
mysecondrep="path/to/secondrep"
myseconddirlayout="[module]/[type]s"/>
</resolvers>
</ivysettings>attribute
Tag: attribute
Defines a macrodef attribute. See macrodef for details.
Attributes
| Attribute | Description | Required |
|---|---|---|
name |
the name of the attribute |
Yes |
default |
the default value of the attribute if none is specified |
No, by default attribute are required |
resolvers
Tag: resolvers
Defines a list of dependency resolvers usable in Ivy. Each dependency resolver is identified by its name, given as an attribute.
The child tag used for the dependency resolver must be equal to a name of a dependency resolver type (either built-in or added with the typedef tag).
(since 1.3) Once defined, resolvers can be referenced by their name, using the following syntax:
<resolver ref="alreadydefinedresolver"/>Note that this works only if the resolver has already been defined and NOT if it is defined later in the Ivy settings file.
Child elements
| Element | Description | Cardinality |
|---|---|---|
any resolver |
adds a resolver to the list of available resolvers |
1..n |
Built-in Resolvers
Ivy comes with a set of built-in dependency resolvers that handle most common needs.
If you don’t find the one you want here, you can also check if someone has contributed it on the links page, or even write your own.
There are basically two types of resolvers in Ivy - composite and standard. A composite resolver is a resolver which delegates the work to other resolvers. The other resolvers are standard resolvers.
Here is the list of built-in resolvers:
| Name | Type | Description |
|---|---|---|
Standard |
Finds Ivy files on ivyrep and artifacts on ibiblio. |
|
Standard |
Finds artifacts on ibiblio. |
|
Standard |
Finds artifacts on bintray. |
|
Standard |
Finds Ivy files and packaging instructions via URLs, then creates artifacts by following the instructions. |
|
Standard |
This very performant resolver finds Ivy files and artifacts in your file system. |
|
Standard |
Finds Ivy files and artifacts in any repository accessible with URLs. |
|
Standard |
Finds Ivy files and artifacts in any repository accessible with URLs from a mirror list. |
|
Standard |
Finds Ivy files and artifacts in any repository accessible with Apache Commons VFS. |
|
Standard |
Finds Ivy files and artifacts in any repository accessible with SSH. |
|
Standard |
Finds Ivy files and artifacts in any repository accessible with SFTP. |
|
Standard |
Finds Ivy files and artifacts within a specified jar. |
|
Composite |
Delegates the finding to a chain of sub resolvers. |
|
Composite |
Delegates the finding of Ivy files to one resolver and of artifacts to another. |
|
Standard |
Resolve modules as OSGi bundles listed by an OSGi obr.xml. |
|
Standard |
Resolve modules as OSGi bundles which are hosted on an Eclipse update site. |
|
Composite |
Delegates the finding to a chain of sub resolvers supporting OSGi bundles. |
Common features and attributes
All resolvers of the same type share some common features and attributes detailed here.
Features
validation
All standard resolvers support several options for validation.
The validate attribute is used to configure if Ivy files should be checked against the Ivy file XML schema.
The checkconsistency attribute allows you to enable or disable consistency checking between what is expected by Ivy when it finds a module descriptor, and what the module descriptor actually contains.
The descriptor attribute lets you define if module descriptors are mandatory or optional.
The checksums attribute is used to define the list of checksums files to use to check if the content of downloaded files has not been corrupted (eg during transfer).
force
Any standard resolver can be used in force mode, which is used mainly to handle local development builds. In force mode, the resolver attempts to find a dependency whatever the requested revision is (internally it replace the requested revision by latest.integration), and if it finds one, it forces this revision to be returned, even when used in a chain with returnFirst=false.
By using such a resolver at the beginning of a chain, you can be sure that Ivy will pick up whatever module is available in this resolver (usually a private local build) instead of the real requested revision. This allows to handle use case like a developer working on modules A and C, where A → B → C, and pick up the local build for C without having to publish a local version of B. (since 2.0)
timeoutConstraint
[since 2.5]
All standard resolvers support the timeoutConstraint attribute. The value for this attribute is the name of the timeout-constraint that’s been defined in the Ivy settings.
Resolvers can be optionally configured to use a timeoutConstraint so that the timeouts defined on that constraint dictate how the resolvers behave when it comes to dealing with timeouts while establishing connections and reading content, during module descriptor and artifact resolutions.
Maven
Any resolver which is able to parse a Maven pom.xml file has to detect the related sources or javadocs artifacts. This often involves several network connections even if neither the sources nor the javadoc are requested to be downloaded.
(since 2.5) Setting the property ivy.maven.lookup.sources to false disables the lookup of the sources artifact.
And setting the property ivy.maven.lookup.javadoc to false disables the lookup of the javadoc artifact.
Attributes
| Attribute | Description | Required | Composite | Standard |
|---|---|---|---|---|
name |
the name which identifies the resolver |
Yes |
Yes |
Yes |
validate |
indicates if resolved Ivy files should be validated against Ivy XSD |
No, defaults to call setting |
Yes |
Yes |
force |
Indicates if this resolver should be used in force mode (see above). (since 2.0) |
No, defaults to false |
No |
Yes |
checkmodified |
Indicates if this resolver should check lastmodified date to know if an Ivy file is up to date. |
No, defaults to ${ivy.resolver.default.check.modified} |
No |
Yes |
changingPattern |
Indicates for which revision pattern this resolver should check lastmodified date to know if an artifact file is up to date (since 1.4). See cache and change management for details. |
No, defaults to none |
Yes |
Yes |
changingMatcher |
The name of the pattern matcher to use to match a revision against the configured changingPattern (since 1.4). See cache and change management for details. |
No, defaults to exactOrRegexp |
Yes |
Yes |
alwaysCheckExactRevision |
Indicates if this resolver should check the given revision even if it’s a special one (like latest.integration) (since 1.3). |
No, defaults to ${ivy.default.always.check.exact.revision} |
No |
Yes |
namespace |
The name of the namespace to which this resolver belongs (since 1.3) |
No, defaults to 'system' |
Yes |
Yes |
checkconsistency |
true to check consistency of module descriptors found by this resolver, false to avoid consistency check (since 1.3) |
No, defaults to true |
No |
Yes |
descriptor |
'optional' if a module descriptor (usually an Ivy file) is optional for this resolver, 'required' to refuse modules without module descriptor (since 2.0) |
No, defaults to 'optional' |
No (except dual) |
Yes |
allownomd |
Deprecated, we recommend using descriptor="required | optional" instead. true if the absence of module descriptor (usually an Ivy file) is authorised for this resolver, false to refuse modules without module descriptor (since 1.4) |
No, defaults to true |
No (except dual) |
Yes |
checksums |
a comma separated list of checksum algorithms to use both for publication and checking (since 1.4) |
No, defaults to ${ivy.checksums} |
No |
Yes |
latest |
The name of the latest strategy to use. |
No, defaults to 'default' |
Yes |
Yes |
cache |
The name of the cache manager to use. |
No, defaults to the value of the default attribute of caches |
No |
Yes |
signer |
The name of the detached signature generator to use when publishing artifacts. (since 2.2) |
No, by default published artifacts will not get signed by Ivy. |
No |
Yes |
timeoutConstraint |
The name of the timeout-constraint to use for the resolver. (since 2.5) |
No. In the absence of a |
No |
Yes |
Examples
<resolvers>
<filesystem name="1" cache="cache-1">
<ivy pattern="${ivy.settings.dir}/1/[organisation]/[module]/ivys/ivy-[revision].xml"/>
<artifact pattern="${ivy.settings.dir}/1/[organisation]/[module]/[type]s/[artifact]-[revision].[ext]"/>
</filesystem>
<chain name="chain1">
<resolver ref="1"/>
<ivyrep name="ivyrep"/>
</chain>
<chain name="chain2" returnFirst="true" dual="true">
<resolver ref="1"/>
<ibiblio name="ibiblio"/>
</chain>
</resolvers>Defines a filesystem resolver, named 1, which is then used in two chains, the first combining the filesystem resolver with an ivyrep resolver, and second combining the filesystem resolver with an ibiblio resolver, which returns the first module found, and uses the whole chain to download artifacts (see corresponding resolvers documentation for details about them). Resolver 1 will use a cache named cache-1 which should have been defined in the caches element.
IvyRep resolver
Tag |
ivyrep |
Handle latest |
yes, at least if the repository server is apache based |
Handle publish |
no |
This resolver usually uses an URL based repository usually similar in structure to the, now defunct, http://ivyrep.jayasoft.org/ repo, to find Ivy files, and ibiblio to find artifacts. It can also be configured to use other similar repositories.
|
Note
|
Since ivyrep is not maintained anymore, the ivyroot attribute is mandatory, and the use of this resolver is not recommended (we recommend using url resolver as replacement in most cases). |
Attributes
This resolver shares the common attributes of standard resolvers.
| Attribute | Description | Required |
|---|---|---|
ivyroot |
the root of the Ivy repository. |
Yes, but may be provided through ${ivy.ivyrep.default.ivy.root} (since 2.0) |
ivypattern |
a pattern describing the layout of the Ivy repository. |
No, defaults to ${ivy.ivyrep.default.ivy.pattern} |
artroot |
the root of the artifacts repository. |
No, defaults to ${ivy.ivyrep.default.artifact.root} |
artpattern |
a pattern describing the layout of the artifacts repository. |
No, defaults to ${ivy.ivyrep.default.artifact pattern} |
Examples
<ivyrep name="ivyrep" ivyroot="http://ivyrep.mycompany.com"/>Looks for Ivy files in an ivyrep like web site located at http://ivyrep.mycompany.com.
Ibiblio resolver
Tag |
ibiblio |
Handle latest |
yes, at least if the repository server is apache based |
Handle publish |
no |
This resolver usually uses ibiblio to find artifacts.
(since 1.3) Using the m2compatible attribute, you can benefit from Maven 2 repository compatibility (convert dots in organisation into slashes, search for POMs, use transitive dependencies of POMs). This setting also affects the default place where the resolver looks for its artifacts to point to the Maven 2 repository. So setting this attribute to true is sufficient to use Maven 2 ibiblio repository.
(since 1.4) When using the m2compatible flag, you can disable the use of POMs by setting the usepoms flag to false. It is then roughly equivalent to a URL resolver configured like this:
<url name="test" m2compatible="true">
<artifact pattern="https://repo1.maven.org/maven2/[organisation]/[module]/[revision]/[artifact]-[revision].[ext]"/>
</url>(since 2.0) When used in m2compatible mode with the default pattern, this resolver uses maven-metadata.xml files (if present) to list the revisions available on the repository. This is especially useful when using a Maven specific proxy, which does not serve directory listing. This can be disabled by using the useMavenMetadata flag.
Limitation: in m2compatible mode, this resolver is not able list available organizations. It means some features like repreport are not available.
Attributes
This resolver shares the common attributes of standard resolvers.
| Attribute | Description | Required |
|---|---|---|
root |
the root of the artifact repository. |
No, defaults to ${ivy.ibiblio.default.artifact.root} |
pattern |
a pattern describing the layout of the artifact repository. |
No, defaults to ${ivy.ibiblio.default.artifact.pattern} |
m2compatible |
True if this resolver should be Maven 2 compatible, false otherwise (since 1.3) |
No, defaults to false |
usepoms |
True if this resolver should use Maven POMs when it is already in m2compatible mode, false otherwise (since 1.4) |
No, defaults to true |
useMavenMetadata |
True if this resolver should use maven-metadata.xml files to list available revisions, false to use directory listing (since 2.0) |
No, defaults to true |
Examples
<ibiblio name="maven2" m2compatible="true"/>Defines a resolver called maven2 using the Maven 2 public repository to find module metadata (using Maven 2 POMs) and artifacts.
<ibiblio name="maven" m2compatible="true" usepoms="false"/>Same as above, but doesn’t use POMs, only artifacts.
Packager resolver
Tag |
packager |
Handle latest |
yes with HTTP URLs (and Apache server) and with file URLs, no with other URLs |
Handle publish |
no |
(since 2.0)
This resolver accesses Ivy files and "packaging instructions" from an online "packager" repository. "Packager" repositories contain no actual artifacts. To get the artifacts, the packaging instructions are downloaded from the repository and executed locally. These instructions specify additional resource(s) to download and how to create the artifacts from them, for example, by downloading a project’s original distribution archive directly from their web site and extracting the desired artifacts.
Packager repositories allow the creation of Ivy repositories that require neither the participation of any of the modules' creators nor setting up a huge mirror site.
The Packager resolver supports a "resource cache", where downloaded archives can be stored to avoid duplicate downloads. This cache is entirely separate from the normal Ivy cache: it is "private" to the Packager resolver, and it stores unmodified original software archives, not Ivy artifacts. See the resourceCache attribute below for details.
The packaging instructions are contained in "packager.xml" in a simple XML format. At resolve time this file gets converted into a "build.xml" file via XSLT and then executed using Ant. Therefore, Ant must be available as an executable on the platform. The Ant task executes in a separate Ant project and so is not affected by properties, etc. that may be set in any existing Ant environment in which Ivy is running. However, Ivy will define a few properties for convenience; see the "Properties" listed below.
For security reasons, the XSLT transform ensures that
-
all downloaded archives have verified SHA1 checksums (including cached resources); and
-
only a very limited set of Ant tasks can be performed during the artifact "build" phase; currently these include move, copy, mkdir, zip, unzip, tar, and untar (this restriction may be overridden however; see below).
The Packager resolver is based on the URL resolver and is configured similarly, except the artifact child tags specify where to find the packager.xml files, rather than the artifacts themselves.
Because the packaging process is relatively slow, it is important to use Ivy’s caching support to avoid repeated execution of the packaging instructions.
Attributes
This resolver shares the common attributes of standard resolvers, plus the following:
| Attribute | Description | Required |
|---|---|---|
buildRoot |
Defines the root of the temporary build directory hierarchy |
Yes |
resourceCache |
Directory where downloaded resources should be cached |
No; defaults to none |
resourceURL |
Ivy pattern that specifies a base URL to use for downloading all resources; overrides the URLs in the packaging instructions |
No; defaults to none |
restricted |
True if this resolver should only allow "safe" Ant tasks in the packaging instructions. Warning: setting |
No; defaults to true |
verbose |
True to run Ant with the -verbose flag |
No; defaults to false |
quiet |
True to run Ant with the -quiet flag |
No; defaults to false |
validate |
True if this resolver should validate (via XSD) the downloaded XML packaging instructions |
No; defaults to true |
preserveBuildDirectories |
True if this resolver should not delete the temporary build directories in which the Ant tasks are executed (for debugging purposes) |
No; defaults to false |
Setting a resourceURL will cause the resolver to override the URLs for resources specified by the packaging instructions. Instead, all resources will be downloaded from an URL constructed by first resolving the resourceURL pattern into a base URL, and then resolving the resource filename relative to that base URL. In other words, the resourceURL pattern specifies the URL "directory", so it should always end in a forward slash.
If a resourceURL download fails, the resolver will fall back to the original URL from the packaging instructions.
Configure a resourceURL in situations where you don’t want to rely on (or wait for) the web sites configured in the packaging instructions, and have access to a better (perhaps private) mirror site.
Child elements
| Element | Description | Cardinality |
|---|---|---|
ivy |
Defines a pattern for ivy.xml files, using the pattern attribute |
1..n |
artifact |
Defines a pattern for packager.xml files, using the pattern attribute |
1..n |
Examples
<packager name="ivyroundup"
buildRoot="${user.home}/.ivy2/packager/build"
resourceCache="${user.home}/.ivy2/packager/cache"
resourceURL="ftp://mirror.example.com/pub/resources/[organisation]/[module]/">
<ivy pattern="http://ivyroundup.googlecode.com/svn/trunk/repo/modules/[organisation]/[module]/[revision]/ivy.xml"/>
<artifact pattern="http://ivyroundup.googlecode.com/svn/trunk/repo/modules/[organisation]/[module]/[revision]/packager.xml"/>
</packager>Defines a packager resolver which points to the http://ivyroundup.googlecode.com/ online repository. Builds will occur in a subdirectory of
${user.home}/.ivy2/packager/build, downloaded resources will be cached in ${user.home}/.ivy2/packager/cache and the mirror site organisation/[module]/ will be tried first for all resources.
Packaging Instructions
The goal of the packaging instructions is to download the required archives, extract the artifacts, and put the artifacts into a subdirectory. Each artifact should be written to artifacts/[type]s/[artifact].[ext] when the Ant build completes.
Below is an example of packaging instructions for TestNG:
<packager-module version="1.0">
<property name="name" value="${ivy.packager.module}"/>
<property name="version" value="${ivy.packager.revision}"/>
<property name="zipname" value="${name}-${version}"/>
<resource dest="archive" url="http://testng.org/${zipname}.zip" sha1="2ea19275dc17453306f8bb780fe6ef6e9af7756b">
<url href="http://mirror.example.com/archives/${zipname}.zip"/>
<include name="${zipname}/src/main/**/*"/>
<include name="${zipname}/src/jdk15/**/*"/>
<include name="${zipname}/javadocs/**/*"/>
<include name="${zipname}/*.jar"/>
</resource>
<build>
<!-- jar -->
<move file="archive/${zipname}/${zipname}-jdk14.jar" tofile="artifacts/jars/${name}-jdk14.jar"/>
<move file="archive/${zipname}/${zipname}-jdk15.jar" tofile="artifacts/jars/${name}-jdk15.jar"/>
<!-- source -->
<zip destfile="artifacts/sources/${name}.zip">
<fileset dir="archive/${zipname}/src/main">
<include name="**/*.java"/>
</fileset>
<fileset dir="archive/${zipname}/src/jdk15">
<include name="**/*.java"/>
</fileset>
</zip>
<!-- javadoc -->
<zip destfile="artifacts/javadocs/javadoc.zip">
<fileset dir="archive/${zipname}/javadocs"/>
</zip>
</build>
</packager-module>Of course, packaging instructions must produce artifacts consistent with those listed in the associated ivy.xml file.
Build-time properties
This resolver ensures that the following Ant properties are defined when it executes the Ant build task.
| Property | Description |
|---|---|
ivy.packager.organisation |
Organization of the Ivy module whose artifacts are being built |
ivy.packager.module |
Module of the Ivy module whose artifacts are being built |
ivy.packager.revision |
Revision of the Ivy module whose artifacts are being built |
ivy.packager.branch |
Branch of the Ivy module whose artifacts are being built |
ivy.packager.resourceCache |
The configured |
ivy.packager.resourceURL |
The resolved |
Packager XML Elements
The packager.xml document element can contain the following child tags.
| Element | Description | Cardinality |
|---|---|---|
property |
Set an Ant property |
0..n |
resource |
Define a resource to download and (optionally) unpack |
0..n |
m2resource |
Define a Maven 2 resource to download and (optionally) unpack |
0..n |
build |
Specify Ant tasks that ultimately result in each artifact being placed into artifacts/[type]s/[artifact].[ext] |
0..1 |
Which Ant tasks are allowed within the build tag is controlled by the restricted configuration attribute. When true (the default), only the following Ant tasks are allowed: copy, jar, mkdir, move, tar, unjar, untar, unwar, unzip, war, and zip. When false, all Ant tasks are allowed.
Warning: setting restricted to false creates a security problem due to Ant tasks like delete, exec, etc. Do not use this setting when your configuration points to an untrusted repository.
Resource XML Elements
The resource XML tag supports the following attributes:
| Attribute | Description | Required |
|---|---|---|
url |
Primary URL for the resource |
Yes |
sha1 |
SHA1 checksum of the resource |
Yes |
dest |
Defines the name of the subdirectory into which the artifact should be unpacked |
No; defaults to "archive" |
tofile |
Where to put the file directly; if present no extraction will be performed |
No; if present, "dest" is ignored |
filename |
Name of the file to download |
No; if not present, same as the last component of the URL |
type |
Type of archive: "zip", "jar", "war", "tar", "tgz", "tar.gz", "tar.bz2" |
No; if not present, will be automatically determined from the filename suffix |
The resource XML tag may contain child elements. An url tag with an href attribute specifies an alternate URL for the resource (see TestNG example above). Any other tags will be included as children of an automatically generated fileset tag.
Maven 2 Resources
Special support is included for Maven 2 resources. For these resources, use the m2resource tag instead of the resource tag. Each m2resource tag specifies one or more artifacts that are downloaded from the Maven 2 repository.
M2Resource XML Elements
The m2resource XML tag supports the following attributes:
| Attribute | Description | Required |
|---|---|---|
groupId |
Maven group ID |
No; defaults to ${ivy.packager.organisation} |
artifactId |
Maven artifact ID |
No; defaults to ${ivy.packager.module} |
version |
Maven version |
No; defaults to ${ivy.packager.revision} |
repo |
Maven repository URL |
No; defaults to https://repo1.maven.org/maven2/ |
Each m2resource XML tag must have one or more artifact tags that define the artifacts to directly download. The URL for each artifact is constructed automatically based on the attributes in the m2resource and artifact tags.
M2Resource Artifact Attributes
The artifact children of m2resource tags support the following attributes:
| Attribute | Description | Required |
|---|---|---|
ext |
Maven filename extension |
No; defaults to "jar" |
classifier |
Maven classifier (e.g., "sources", "javadoc") |
No; defaults to none |
sha1 |
SHA1 checksum of the resource |
Yes |
dest |
Defines the name of the subdirectory into which the artifact should be unpacked |
Exactly one of "dest" or "tofile" must be supplied |
tofile |
Where to put the file; no extraction will be performed |
|
type |
Type of archive: "zip", "jar", "war", "tar", "tgz", "tar.gz", "tar.bz2" |
No; if not present, will be automatically determined from the filename suffix |
Below is an example of packaging instructions for the Apache Commons Email module. Note that no build tag is required because all of the Maven 2 artifacts are usable directly (i.e., without unpacking anything).
<packager-module version="1.0">
<m2resource>
<artifact tofile="artifacts/jars/${ivy.packager.module}.jar" sha1="a05c4de7bf2e0579ac0f21e16f3737ec6fa0ff98"/>
<artifact classifier="javadoc" tofile="artifacts/javadocs/javadoc.zip" sha1="8f09630f1600bcd0472a36fb2fa2d2a6f2836535"/>
<artifact classifier="sources" tofile="artifacts/sources/source.zip" sha1="15d67ca689a792ed8f29d0d21e2d0116fa117b7e"/>
</m2resource>
</packager-module>Filesystem resolver
Tag |
filesystem |
Handle latest |
yes |
Handle publish |
yes |
This resolver uses the file system to resolve Ivy files and artifacts. An advantage of this resolver is that it usually provides very good performance. Moreover, it is easy to setup using basic OS file sharing mechanisms.
The configuration of such a resolver is mainly done through Ivy and artifact patterns, indicating where Ivy files and artifacts can be found in the file system. These patterns must be absolute paths (since 2.0). You can indicate a list of patterns which will be checked one after the other.
(since 1.3) Using the m2compatible attribute, this resolver will convert dots found in organisation into slashes like Maven 2 does for groupId. For instance, it will transform the organisation from com.company into com/company when replacing the token [organisation] in your pattern.
Limitation: in m2compatible mode, this resolver is not able list available organizations. It means some features like repreport are not available.
Atomic publish support
[since 2.0]
This resolver supports atomic publish, which is useful for environments with a lot of concurrent publish and resolve actions. The atomic publish relies on the atomicity of the rename operation in the underlying filesystem (which includes NTFS and POSIX based filesystems).
In this case the resolver starts by publishing the module according to the pattern, but where a .part suffix is appended to the revision. Then the publish is committed with a rename to the final location.
Limitations Atomic publish is currently limited in several ways:
-
you need to use a pattern for both the artifact and the Ivy files which uses the revision as a directory. For instance,
${repository.dir}/[module]/[revision]/[artifact].[ext]works,${repository.dir}/[module]/[artifact]-[revision].[ext]doesn’t -
both the artifact and Ivy pattern should have the same prefix until the
[revision]token. -
overwrite during publish is not supported
-
you should not use revision names ending with
.part
The transactional attribute can be used to configure the atomicity behavior:
-
auto
use transaction if possible (according to limitation), otherwise don’t -
true
always use transaction, fail the build if a limitation is not fulfilled -
false
don’t use transaction at all
Attributes
This resolver shares the common attributes of standard resolvers.
| Attribute | Description | Required |
|---|---|---|
m2compatible |
True if this resolver should be Maven 2 compatible, false otherwise (since 1.3) |
No, defaults to false |
local |
True if this resolver should be considered local, false otherwise (since 1.4). See useOrigin attribute on the caches element for details. |
No, defaults to true |
transactional |
true to force the use of transaction, false to prevent the use of transaction, auto to get transaction when possible (since 2.0). See above for details. |
No, defaults to auto |
Child elements
| Element | Description | Cardinality |
|---|---|---|
ivy |
defines a pattern for Ivy files, using the pattern attribute |
0..n |
artifact |
defines a pattern for artifacts, using the pattern attribute |
1..n |
URL resolver
Tag |
url |
Handle latest |
yes with HTTP URLs (and Apache server) and with file URLs, no with other URLs |
Handle publish |
yes with HTTP URLs whose destination supports publishing (as of Ivy 2.0) |
This resolver is one of the most generic. In fact, most of the previous resolvers can be obtained by a particular configuration of this one. Indeed it uses URLs to find Ivy files and artifacts. The URLs it uses are defined through Ivy and artifact children, each giving a pattern to find Ivy files or artifacts.
Limitation: in m2compatible mode, this resolver is not able list available organizations. It means some features like repreport are not available.
Attributes
This resolver shares the common attributes of standard resolvers.
| Attribute | Description | Required |
|---|---|---|
m2compatible |
True if this resolver should be Maven 2 compatible, false otherwise (since 1.3) |
No, defaults to false |
Child elements
| Element | Description | Cardinality |
|---|---|---|
ivy |
defines a pattern for Ivy files, using the pattern attribute |
0..n |
artifact |
defines a pattern for artifacts, using the pattern attribute |
1..n |
Example
<url name="two-patterns-example">
<ivy pattern="http://ivyrep.mycompany.com/[module]/[revision]/ivy-[revision].xml"/>
<artifact pattern="http://ivyrep.mycompany.com/[module]/[revision]/[artifact]-[revision].[ext]"/>
<artifact pattern="http://ivyrep.mycompany.com/[module]/[revision]/[artifact].[ext]"/>
</url>Looks for Ivy files in one place and for artifacts in two places: with or without revision in name (revision being already in the directory structure).
Chain resolver
Tag |
chain |
Handle latest |
depends on sub resolvers |
Handle publish |
delegates to first sub resolver in chain |
This resolver is only a container of a chain of other resolvers. The sub resolvers can be any resolver, including a chain. An attribute enable to indicate if the chain must be iterated after the first found or not (at least when asking for a latest revision). If the chain is iterated, then it’s the latest among the ones found that is returned. If the chain is not iterated, then it’s the first found which is returned.
Attributes
This resolver shares the common attributes of composite resolvers.
| Attribute | Description | Required |
|---|---|---|
returnFirst |
true if the first found should be returned. |
No, defaults to false |
dual |
true if the chain should behave like a dual chain. (since 1.3) |
No, defaults to false |
Child elements
| Element | Description | Cardinality |
|---|---|---|
any resolver |
a sub resolver to use |
1..n |
Examples
<chain name="test">
<filesystem name="1">
<ivy pattern="${ivy.settings.dir}/1/[organisation]/[module]/ivys/ivy-[revision].xml"/>
<artifact pattern="${ivy.settings.dir}/1/[organisation]/[module]/[type]s/[artifact]-[revision].[ext]"/>
</filesystem>
<ivyrep name="2"/>
</chain>Both a filesystem and ivyrep will be used to look for Ivy files. If a dynamic revision is required, then both the filesystem and ivyrep will be queried to find the most recent revision among the two resolvers. Once the most recent revision is found in one resolver, it’s the same resolver which will be used to download artifacts.
<chain name="test" returnFirst="true">
<filesystem name="1">
<ivy pattern="${ivy.settings.dir}/1/[organisation]/[module]/ivys/ivy-[revision].xml"/>
<artifact pattern="${ivy.settings.dir}/1/[organisation]/[module]/[type]s/[artifact]-[revision].[ext]"/>
</filesystem>
<ivyrep name="2"/>
</chain>Same as before, except that if a revision is found in the filesystem then ivyrep will not be queried: its the filesystem which will be used for both the Ivy file and the artifacts.
<chain name="test" dual="true">
<filesystem name="1">
<ivy pattern="${ivy.settings.dir}/1/[organisation]/[module]/ivys/ivy-[revision].xml"/>
<artifact pattern="${ivy.settings.dir}/1/[organisation]/[module]/[type]s/[artifact]-[revision].[ext]"/>
</filesystem>
<ivyrep name="2"/>
</chain>Same as first example, except that once a module is found by either filesystem or ivyrep, then it’s the whole chain which will be queried to download the artifacts. So in this case Ivy file and artifacts may be split across the two resolvers for the same module.
Dual resolver
Tag |
dual |
Handle latest |
depends on sub resolvers |
Handle publish |
delegates to Ivy sub resolver if artifact to publish is of "ivy" type, to artifact sub resolver otherwise |
This resolver delegates its job to one resolver for Ivy files and another for artifacts.
Attributes
This resolver shares the common attributes of composite resolvers.
Child elements
| Element | Description | Cardinality |
|---|---|---|
any resolver |
two resolvers, the first being the Ivy resolver, the second the artifact resolver |
2 |
SFTP resolver
Tag |
sftp |
Handle latest |
yes |
Handle publish |
yes |
[since 1.4]
This resolver can be used when your Ivy repository is located on a server accessible via SFTP. The secured nature of SFTP and its widespread implementation on most *nix servers makes this resolver a very good candidate in an enterprise environment.
If your server supports SSH but not SFTP, there is also an SSH resolver.
Note that SFTP is also supported by VFS, so you can use a VFS resolver instead. The advantage of this resolver is that you have a better control over authentication, it can prompt for username/password credentials, or you can use private/public key authentication, which is not possible with the VFS resolver. When it prompts for username/password, it uses a Swing dialog, which is not possible in a headless environment. If you want to prompt for the credentials on the command line, use Ant input task, for example, before calling Ivy.
All necessary connection parameters can be set here via attributes, or via an OpenSSH-style config file specified by sshConfig.
However all attributes defined in the pattern URL of the resolver will have higher priority and will overwrite the values given here. To specify connection parameters in the pattern, you have to specify a full URL and not just a path as pattern.
e.g. pattern="/path/to/my/repos/[artifact].[ext]" will use all connection parameters from this class
e.g. pattern="sftp://myserver.com/path/to/my/repos/[artifact].[ext]" will use all parameters from the attributes with the exception of the host, which will be "myserver.com"
e.g. pattern="sftp://user:geheim@myserver.com:8022/path/to/my/repos/[artifact].[ext]" will use only the keyFile and keyFilePassword from the attributes (if needed). Rest will come from the URL.
Note that the authentication features of this resolver are exactly the same as the SSH resolver. Choosing between the two is often a matter of server implementation. If your server supports SFTP, usually it’s preferable.
Internally this resolver relies on jsch as SSH client, which is a popular Java SSH client, used for example in Eclipse.
Attributes
This resolver shares the common attributes of standard resolvers.
| Attribute | Description | Required |
|---|---|---|
user |
The username to provide as credential |
No, defaults to username given on the patterns, or prompt if none is set |
userPassword |
The password to provide as credential |
No, defaults to password given on the patterns, or prompt if none is set |
keyFile |
Path to the keyfile to use for authentication |
No, defaults to username/password authentication |
keyFilePassword |
the password used to protect the key file |
No, will prompt for password if keyFile authentication is used and if it is password encrypted |
host |
The host to connect to |
No, defaults to host given on the patterns, fail if none is set |
port |
The port to connect to |
No, defaults to 22 |
sshConfig |
Path to an OpenSSH-style config file containing additional configuration |
No |
Child elements
| Element | Description | Cardinality |
|---|---|---|
ivy |
defines a pattern for Ivy files, using the pattern attribute |
0..n |
artifact |
defines a pattern for artifacts, using the pattern attribute |
1..n |
Example
<sftp user="myuser" host="myhost.com">
<ivy pattern="/path/to/ivy/[module]/ivy.xml"/>
<artifact pattern="/path/to/[organisation]/[module]/[artifact].[ext]"/>
</sftp>Will connect to myhost.com using myuser and prompt for the password.
<sftp user="${myuser}" userPassword="${my.password}" host="myhost.com">
<ivy pattern="path/to/ivy/[module]/ivy.xml"/>
<artifact pattern="path/to/[organisation]/[module]/[artifact].[ext]"/>
</sftp>Will connect to myhost.com using user and password provided with Ivy variables.
<sftp>
<ivy pattern="sftp://user:geheim@yourserver.com:8022/path/to/repos/[module]/[revision]/ivy.xml"/>
<artifact pattern="sftp://user:secret@myserver.com:8022/path/to/my/repos/[artifact].[ext]"/>
</sftp>Will connect to yourserver.com on port 8022 with user 'user' and password 'geheim' for authentication for Ivy files, and to myserver.com on port 8022 using user 'user' and password 'secret' for the artifacts.
<sftp keyFile="path/to/key/file" keyFilePassword="${password}">
<ivy pattern="sftp://user@yourserver.com:8022/path/to/repos/[module]/[revision]/ivy.xml"/>
<artifact pattern="sftp://user@myserver.com:8022/path/to/my/repos/[artifact].[ext]"/>
</sftp>Will connect to yourserver.com on port 8022 with user 'user' and use keyFile path/to/key/file for keyFile and the value of password variable for keyFilePassword authentication for Ivy files, and to myserver.com on port 8022 using user 'user' with the same keyFile/keyFilePassword pair for the artifacts.
<sftp host="myhost" sshConfig="/path/to/.ssh/config">
<ivy pattern="/path/to/ivy/[module]/ivy.xml"/>
<artifact pattern="/path/to/[organisation]/[module]/[artifact].[ext]"/>
</ssh>Will connect to the host named by myhost according to the config file in /path/to/.ssh/config, using the hostname, username, and optionally IdentityFile specified in the config section "Host myhost". For example, if the corresponding Host section contains "Hostname yourserver.com" and "User myremoteusername", it will connect to yourserver.com using username myremoteusername.
SSH resolver
Tag |
ssh |
Handle latest |
yes |
Handle publish |
yes |
[since 1.4]
This resolver can be used when your Ivy repository is located on a server accessible via SSH. The secured nature of SSH and its widespread implementation on most *nix servers makes this resolver a very good candidate in an enterprise environment.
If your server supports SFTP, you can consider using the SFTP resolver.
Internally this resolver shares most of its behaviour with the SFTP resolver, so refer to its documentation for details.
Attributes
This resolver shares the common attributes of standard resolvers.
| Attribute | Description | Required |
|---|---|---|
user |
The username to provide as credential |
No, defaults to username given on the patterns, or prompt if none is set |
userPassword |
The password to provide as credential |
No, defaults to password given on the patterns, or prompt if none is set |
keyFile |
Path to the keyfile to use for authentication |
No, defaults to username/password authentication |
keyFilePassword |
the password used to protect the key file |
No, will prompt for password if keyFile authentication is used and if it is password encrypted |
host |
The host to connect to |
No, defaults to host given on the patterns, fail if none is set |
port |
The port to connect to |
No, defaults to 22 |
sshConfig |
Path to an OpenSSH-style config file containing additional configuration |
No |
publishPermissions |
A four digit string (e.g., 0644, see "man chmod", "man open") specifying the permissions of the published files. (since 2.0) |
No, defaults to scp standard behaviour |
Child elements
| Element | Description | Cardinality |
|---|---|---|
ivy |
defines a pattern for Ivy files, using the pattern attribute |
0..n |
artifact |
defines a pattern for artifacts, using the pattern attribute |
1..n |
Example
<ssh user="myuser" host="myhost.com">
<ivy pattern="/path/to/ivy/[module]/ivy.xml"/>
<artifact pattern="/path/to/[organisation]/[module]/[artifact].[ext]"/>
</ssh>Will connect to myhost.com using myuser and prompt for the password.
<ssh keyFile="path/to/key/file" keyFilePassword="${password}">
<ivy pattern="ssh://user:geheim@yourserver.com:8022/path/to/repos/[module]/[revision]/ivy.xml"/>
<artifact pattern="ssh://user:geheim@myserver.com:8022/path/to/my/repos/[artifact].[ext]"/>
</ssh>Will connect to yourserver.com on port 8022 with user geheim and use path/to/key/file for keyFile and the value of password variable for keyFilePassword authentication for Ivy files, and to myserver.com on port 8022 using user geheim with the same keyFile/keyFilePassword pair for the artifacts.
<ssh host="myhost" sshConfig="/path/to/.ssh/config">
<ivy pattern="/path/to/ivy/[module]/ivy.xml"/>
<artifact pattern="/path/to/[organisation]/[module]/[artifact].[ext]"/>
</ssh>Will connect to the host named by myhost according to the config file in /path/to/.ssh/config, using the hostname, username, and optionally IdentityFile specified in the config section "Host myhost". For example, if the corresponding Host section contains "Hostname yourserver.com" and "User myremoteusername", it will connect to yourserver.com using username myremoteusername.
VFS resolver
Tag |
vfs |
Handle latest |
depend on VFS capacity, usually yes |
Handle publish |
depend on VFS capacity, usually yes |
[since 1.4]
This resolver is certainly the most capable, since it relies on Apache Commons VFS, which gives an uniform access to a good number of file systems, including FTP, WebDAV, zip, …
Attributes
This resolver shares the common attributes of standard resolvers.
Child elements
| Element | Description | Cardinality |
|---|---|---|
ivy |
defines a pattern for Ivy files, using the pattern attribute |
0..n |
artifact |
defines a pattern for artifacts, using the pattern attribute |
1..n |
Example
<vfs name="vfs-resolver">
<ivy pattern="sftp://username:password@host/[organisation]/[module]/[revision]/ivy.xml"/>
<artifact pattern="sftp://username:password@host/[organisation]/[module]/[revision]/[artifact].[ext]"/>
</vfs>Access Ivy and artifact files using SFTP.
Jar resolver
Tag |
jar |
Handle latest |
yes |
Handle publish |
no |
[since 2.3]
This resolver uses a specified jar resolve Ivy files and artifacts.
This kind of resolver helps the packaging of an entire repository. Since the entire "repository" jar is expected to be local at some point, the size of a such repository should be considered to be not too large if it is expected to be remote; hence the artifacts in a such repo should be little in size.
The configuration of such a resolver is done via specifying the location of the jar, and through Ivy and artifact patterns, indicating where Ivy files and artifacts can be found in the jar. You can indicate a list of patterns which will be checked one after the other. Note that the patterns MUST NOT start with a slash.
Attributes
This resolver shares the common attributes of standard resolvers.
| Attribute | Description | Required |
|---|---|---|
file |
the absolute path of the jar |
One of 'file' or 'url' is required |
url |
the URL of the jar |
One of 'file' or 'url' is required |
Child elements
| Element | Description | Cardinality |
|---|---|---|
ivy |
defines a pattern for Ivy files, using the pattern attribute |
0..n |
artifact |
defines a pattern for artifacts, using the pattern attribute |
1..n |
Examples
<jar name="my-local-jar-resolver" file="/home/me/myrepo.jar">
<ivy pattern="[organisation]/[module]/ivys/ivy-[revision].xml"/>
<artifact pattern="[organisation]/[module]/[type]s/[artifact]-[revision].[type]"/>
</jar>A simple local jar repository.
<jar name="my-remote-jar-resolver" url="http://www.mywebsite.com/dist/myrepo.jar">
<ivy pattern="dir_in_jar/subdir_in_jar/[organisation]/[module]/ivys/ivy-[revision].xml"/>
<ivy pattern="dir_in_jar/another_subdir_in_jar/[organisation]/[module]/ivys/ivy-[revision].xml"/>
<artifact pattern="dir_in_jar/subdir_in_jar/[organisation]/[module]/[type]s/[artifact]-[revision].[type]"/>
<artifact pattern="dir_in_jar/another_subdir_in_jar/[organisation]/[module]/[type]s/[artifact]-[revision].[type]"/>
<artifact pattern="dir_in_jar/yet_another_subdir_in_jar/[organisation]/[module]/[type]s/[artifact]-[revision].[type]"/>
</jar>A remote jar repository with multiple Ivy and artifact patterns, patterns pointing in some sub directories in the jar.
OSGi Bundle Repository
Tag |
obr |
Handle latest |
yes |
Handle publish |
no |
[since 2.3]
This resolver is one of the resolver which supports OSGi™ dependencies. A part of the OSGi specification defines OBR (OSGi Bundle Repository). OBR aggregates the OSGi metadata of every bundle included in a repository. So contrary to the other resolvers, this resolver needs to get the descriptor of the repository (an obr.xml) before starting to resolve modules.
Attributes
This resolver shares the common attributes of composite resolvers.
| Attribute | Description | Required |
|---|---|---|
repoXmlURL |
the URL of the obr.xml to load. |
Yes |
repoXmlFile |
the local path of the obr.xml to load. |
Yes |
requirementStrategy |
defines how strict should be the OSGi resolution. Can be one of |
No, default to |
metadataTtl |
the time in milliseconds the obr.xml is considered up to date |
No, default to 3600000 (1 hour) |
forceMetadataUpdate |
force the update of the obr.xml without checking its freshness |
No, default to false |
The requirement strategy is defining how the resolver should behave when facing several choices. In the OSGi dependency model, an Import-Package requirement can be satisfied by several different bundles. So when resolving such requirement, Ivy will first look into the already resolved bundles if one provides that package. If it fails to find one, then two behaviours can occur:
-
if the requirement strategy is
first, among the bundles satisfying the requirement, it will choose the first one. A warning will be logged about the choice Ivy has to arbitrarily do. -
if the requirement strategy is
noambiguity, Ivy will make the resolution fail.
Examples
<obr name="felix-repo" repoXmlURL="http://felix.apache.org/obr/releases.xml"/>A simple repository configured to use the Felix OBR.
<obr name="my-osgi-repo" repoXmlFile="${ivy.settings.dir}/obr/obr.xml" requirementStrategy="first"/>A local repository which is trusted to always provide correct dependency for the Import-Package requirements.
Aggregate OSGi Repository
Attributes
This resolver shares the common attributes of composite resolvers.
Elements
As sub element, this resolver accept any kind of OSGi resolver: obr, updatesite, or any other osgi-agg.
Examples
<updatesite name="ivyde-updatesite" url="http://www.apache.org/dist/ant/ivyde/updatesite"/>
<obr name="felix-repo" repoXmlURL="http://felix.apache.org/obr/releases.xml"/>
<osgi-agg name="all-osgi">
<resolver ref="ivyde-updatesite"/>
<resolver ref="felix-repo"/>
</osgi-agg>An aggregated OSGi repository composed of the Apache IvyDE Eclipse update site and the Felix OBR.
Eclipse Updatesite resolver
Tag |
updatesite |
Handle latest |
yes |
Handle publish |
no |
[since 2.3]
This resolver is one of the resolvers which support OSGi™ dependencies. It resolves modules (OSGi bundles) which are hosted in an Eclipse™ update site.
This resolver supports old style Eclipse updatesite, based on a single file, site.xml. It also supports Eclipse P2 repositories.
Attributes
This resolver shares the common attributes of composite resolvers.
| Attribute | Description | Required |
|---|---|---|
url |
the URL of the Eclipse updatesite |
Yes |
requirementStrategy |
defines how strict should be the OSGi resolution. Can be one of |
No, default to |
metadataTtl |
the time in milliseconds the updatesite metadata are considered up to date |
No, default to 3600000 (1 hour) |
forceMetadataUpdate |
force the update of the updatesite metadata without checking their freshness |
No, default to false |
The requirement strategy is defining how the resolver should behave when facing several choices. In the OSGi dependency model, an Import-Package requirement can be satisfied by several different bundles. So when resolving such requirement, Ivy will first look into the already resolved bundles if one provides that package. If it fails to find one, then two behaviours can occur:
-
if the requirement strategy is
first, among the bundles satisfying the requirement, it will choose the first one. A warning will be logged about the choice Ivy has to arbitrarily do. -
if the requirement strategy is
noambiguity, Ivy will make the resolution fail.
Examples
<updatesite name="ivyde-updatesite" url="http://www.apache.org/dist/ant/ivyde/updatesite"/>A simple repository configured to load the Apache IvyDE Eclipse update site.
Mirrored resolver
Tag |
mirroredurl |
Handle latest |
yes with HTTP URLs (and Apache server) and with file URLs, no with other URLs |
Handle publish |
no |
[since 2.3]
This resolver can resolve dependencies against several mirrors of the same repository. From a list of mirror URLs, it will iteratively try to resolve the dependencies against each one.
Attributes
This resolver shares the common attributes of standard resolvers.
| Attribute | Description | Required |
|---|---|---|
m2compatible |
True if this resolver should be Maven 2 compatible, false otherwise |
No, defaults to false |
mirrorListUrl |
The URL where to retrieve the list of mirror URLs. |
Yes |
Child elements
| Element | Description | Cardinality |
|---|---|---|
ivy |
defines a pattern for Ivy files, using the pattern attribute |
0..n |
artifact |
defines a pattern for artifacts, using the pattern attribute |
1..n |
Example
Having the file mavenrepolist.txt content:
https://repo1.maven.org/maven2/
http://repo2.maven.org/maven2/And the piece of settings:
<mirroredurl name="mirrored-maven" m2compatible="true" mirrorListUrl="file:///Users/me/dev/repo/mavenrepolist.txt">
<artifact pattern="[organisation]/[module]/[revision]/[artifact]-[revision].[ext]"/>
</mirroredurl>It will resolve first on the repo1 and if failing it will fall back on repo2.
The mirror list can be retrieved from a geo-location aware URL:
<mirroredurl name="mirrored-asf" mirrorListUrl="http://www.apache.org/dyn/closer.cgi">
<ivy pattern="repo/[organisation]/[module]/[revision]/ivy.xml"/>
<artifact pattern="repo/[organisation]/[module]/[revision]/[artifact]-[revision].[ext]"/>
</mirroredurl>Bintray resolver
Tag |
bintray |
Handle latest |
yes, at least if the repository server is apache based |
Handle publish |
no |
[since 2.4]
This resolver uses Bintray DaaS (Distribution as a Service) platform to retrieve artifacts.
Attributes
| Attribute | Description | Required |
|---|---|---|
subject |
Bintray username of a repository owner. |
No, defaults to Bintray |
repo |
User’s repository name. |
No, defaults to JCenter |
Examples
<bintray/>A default, defines a JCenter bintray resolver. In most circumstances you won’t need any other resolvers as JCenter is already a super-set of many other repositories, including Maven Central.
|
Note
|
Bintray and JCenter are being decommissioned by their service provider in the year 2021/2022. Once they are decommissioned, this resolver will no longer work. The original announcement can be read at https://jfrog.com/blog/into-the-sunset-bintray-jcenter-gocenter-and-chartcenter/ |
<bintray subject="dsowerby" repo="maven"/>
<bintray subject="igelgrun" repo="batrak"/>Defines two resolvers to use a repository "maven" of user "dsowerby" (https://dl.bintray.com/dsowerby/maven/) and repository "batrak" of user "igelgrun" (https://dl.bintray.com/igelgrun/batrak/).
conflict-managers
Tag: conflict-managers
Defines a list of conflict managers usable in Ivy. Each conflict manager is identified by its name, given as an attribute.
The child tag used for the conflict manager must be equal to a name of a conflict manager type (either built-in or added with the typedef tag).
Here is a list of built-in conflict managers (which do not require anything in the settings file):
-
all
this conflict manager resolve conflicts by selecting all revisions. Also called theNoConflictManager, it doesn’t evict any modules. -
latest-time
this conflict manager selects only thelatestrevision, latest being defined as the latest in time. Note that latest in time is costly to compute, so prefer latest-revision if you can. -
latest-revision
this conflict manager selects only thelatestrevision, latest being defined by a string comparison of revisions. -
latest-compatible
this conflict manager selects the latest version in the conflicts which can result in a compatible set of dependencies. This means that in the end, this conflict manager does not allow any conflicts (similar to the strict conflict manager), except that it follows a best effort strategy to try to find a set of compatible modules (according to the version constraints) -
strict
this conflict manager throws an exception (i.e. causes a build failure) whenever a conflict is found.
The two "latest" conflict managers also take into account the force attribute of the dependencies. In fact, direct dependencies can declare a force attribute (see dependency), which indicates that the revision given in the direct dependency should be preferred over indirect dependencies.
Here is a list of conflict manager types available, which can be used to define your own custom conflict managers:
-
latest-cm
The latest conflict manager uses a latest strategy to select the latest revision among several ones. Bothlatest-timeandlatest-revisionconflict managers are based on this conflict manager type. It takeslatestas attribute to define which latest strategy should be used. Example:
<latest-cm name="mylatest-conflict-manager" latest="my-latest-strategy"/>-
compatible-cm
The latest compatible conflict manager uses a latest strategy to select the latest revision among several ones. It takeslatestas an attribute to define which latest strategy should be used. Example:
<compatible-cm name="my-latest-compatible-conflict-manager" latest="my-latest-strategy"/>-
regexp-cm
This conflict manager is based on a regular expression and throws an exception (i.e. causes a build failure) when a conflict is found with versions with different matching group. For instance, if a conflict is found between 1.2.x and 1.3.y it will throw an exception if the regular expression is(.*)\.\d, because the matching group will match different strings (1.2 and 1.3). 1.2.1 and 1.2.2 won’t throw an exception with the same regular expression. The regular expression is set using theregexpattribute. AignoreNonMatchingattribute can also be set to simply warn when a version is found which does not match the regular expression, instead of throwing an exception.
Child elements
| Element | Description | Cardinality |
|---|---|---|
any conflict manager |
adds a conflict manager to the list of available conflict managers |
0..n |
modules
Tag: modules
Defines per module or module set settings.
The rules are given by defining a module set, using a pattern for module organisation and name, and giving some settings for the set, like the name of the corresponding resolver to use.
If no rules match a given module, the default setting will be used.
|
Note
|
You can greatly improve the performance of dependency resolution by configuring multiple smaller resolvers instead of one large resolver (i.e. chain). For instance, if you have a local repository for your modules and a remote repository for third party libraries, it is a good idea to have two separate resolvers, one for all of your modules and another for the rest (the default one). |
Child elements
| Element | Description | Cardinality |
|---|---|---|
defines a module set rule |
1..n |
module
Tag: module
Define a module set rule. The tag defines a module set, by giving an expression and the matcher to use for organisation, name, revision and any extra attribute identifying your modules. The rule matching is performed in order, and is using a pattern matcher. Hence you can use * to specify all, or simply avoid specifying the attribute.
The revision and extra attributes are only used for rules defining the resolver to use. For other settings, use only organisation and module name.
It also gives the specific setting to use for this module set.
For each module set, you can configure:
-
the resolver to use
-
the conflict manager to use
-
the default branch to use
-
the resolve mode to use
Attributes
| Attribute | Description | Required |
|---|---|---|
organisation |
the organisation to match to apply the rule. |
No, defaults to * |
name |
the module’s name to match to apply the rule. |
No, defaults to * |
revision |
the module’s revision to match to apply the rule. Note that the version may not be resolved yet (be |
No, defaults to * |
any extra attribute |
an extra attribute to match to apply the rule (since 2.0). |
No, defaults to * |
matcher |
the matcher to use to match the modules to which the resolver should be applied (since 1.3). |
No, defaults to exactOrRegexp |
resolver |
the name of the resolver to apply. The resolver must have been defined in the resolvers section of the settings file. |
No |
conflict-manager |
the name of the conflict manager to apply (since 1.4). |
No |
branch |
the default branch to apply (since 1.4). |
No |
resolveMode |
the resolve mode to use (since 2.0). |
No |
Examples
<modules>
<module organisation="apache" name="*" resolver="myprojectsresolver"/>
</modules>Uses myprojectresolver for all modules from apache.
<modules>
<module organisation="apache" name="commons-*" matcher="glob" resolver="myapachecommonsresolver"/>
</modules>Uses myapachecommonsresolver for all modules beginning with commons- from apache.
<modules>
<module organisation="apache" name="commons-[a-z]+" myextra="val.*" matcher="regexp" resolver="myapachecommonsresolver"/>
</modules>Uses myapachecommonsresolver for all modules from apache beginning with commons- followed by any number of alphabetic lowercase characters, and with the extra attribute myextra having a value beginning with val..
<modules>
<module organisation="apache" name="ivy*" matcher="glob" conflict-manager="latest-time"/>
</modules>Uses latest-time conflict manager for all modules from apache whose name begins with ivy.
<modules>
<module organisation="apache" name="ivy*" matcher="glob" branch="fix-103"/>
</modules>Uses fix-103 as default branch for all modules from apache whose name begins with ivy.
outputters
Tag: outputters
Defines a list of report outputters usable in Ivy.
A report outputter is used at the end of the resolve process to generate a report of how the resolve has been performed.
Two report outputters are registered by default:
-
a log report outputter (LogReportOutputter)
which produces the output on the console at the end of the resolve, which looks like this:
---------------------------------------------------------------------
| | modules || artifacts |
| conf | number| search|dwnlded|evicted|| number|dwnlded|
---------------------------------------------------------------------
| default | 1 | 1 | 0 | 0 || 1 | 1 |
----------------------------------------------------------------------
an xml report outputter (XmlReportOutputter)
which produces an XML report in the cache, which is mandatory for correct Ivy behaviour, since it’s that report which is used when you do a post resolve step in a separate build from the resolve itself. It’s also this XML report which is processed to generate all the different reports available in the report task.
The child tag used for the parser must be equal to a name of a report outputter type (added with the typedef tag).
To see how to define your own report outputter see Extending Ivy documentation
Child elements
| Element | Description | Cardinality |
|---|---|---|
any report outputter |
adds a report outputter to the list of available ones |
0..n |
statuses
Tag: statuses
[since 1.4]
Defines the list of available statuses.
By default, Ivy has 3 statuses: release, milestone and integration. By adding a statuses section to your Ivy settings file, you define the statuses you want to use. Note that in this case, if you still want to have Ivy default statuses, you will have to declare them.
The integration property on each status is only used for recursive delivery, an integration dependency being delivered if the caller is not in integration state itself.
The default status is the one used when none is defined in a module descriptor. If not specified, it defaults to the last defined status.
|
Note
|
The statuses order is important, the first is considered the more mature, the last the less mature. This is used to know if a status is compatible with a latest.<status> version matcher.
|
Attributes
| Attribute | Description | Required |
|---|---|---|
default |
the name of the status to use when none is declared in an Ivy file |
No, defaults to the last status declared |
Child elements
| Element | Description | Cardinality |
|---|---|---|
defines a new status |
0..n |
Examples
<statuses default="bronze">
<status name="gold" integration="false"/>
<status name="silver" integration="false"/>
<status name="bronze" integration="true"/>
</statuses>Defines 3 statuses, gold, silver and bronze. The default status used when none is declared in an Ivy file will be bronze.
It is also considered an integration status, and thus doesn’t trigger any recursive delivery.
status
Tag: status
Define one available module status.
See statuses page for details about how statuses are defined.
Attributes
| Attribute | Description | Required |
|---|---|---|
name |
name of status defined |
Yes |
integration |
true if this is an integration status, false otherwise |
No, defaults to false |
triggers
Tag: triggers
[since 1.4]
Defines a list of triggers to activate on some Ivy events.
A trigger is an action which is performed whenever a particular event occurs. Ivy supports 3 type of triggers out of the box:
-
ant-call
calls a target in the same build as the original one whenever a particular event occurs. -
ant-build
calls an Ant build which may be in another Ant build script. -
log
echo a message, usually in a file
If you want to use a different trigger, you can implement your own.
The following events are available in Ivy:
| Name | Attributes | Description |
|---|---|---|
pre-resolve |
* organisation * module * revision * conf |
Fired at the beginning of the resolve process, before module dependencies and transitive dependencies are resolved. |
pre-resolve-dependency |
* organisation * module * req-revision * req-revision-default * req-revision-dynamic * revision * resolver |
Fired before each dependency is resolved. In this case resolved means resolving the actual revision if the requested revision is a version constraint and not a static version, and downloading all necessary metadata information. |
post-resolve-dependency |
* organisation * module * req-revision * req-revision-default * req-revision-dynamic * revision * resolved * duration * resolver * any extra attribute |
Fired after each dependency is resolved |
post-resolve |
* organisation * module * revision * conf * resolve-id * nb-dependencies * nb-artifacts * resolve-duration * download-duration * download-size |
Fired at the end of the resolve process, when all module dependencies have been resolved |
pre-download-artifact |
* organisation * module * revision * artifact * type * ext * metadata * resolver * origin * local |
Fired before an artifact is downloaded from a repository to the cache |
post-download-artifact |
* organisation * module * revision * artifact * type * ext * metadata * resolver * origin * local * size * duration * file |
Fired after an artifact has been downloaded from a repository to the cache |
pre-retrieve (since 2.0) |
* organisation * module * revision * conf * symlink * sync |
Fired at the beginning of the retrieve process. |
post-retrieve (since 2.0) |
* organisation * module * revision * conf * symlink * sync * duration * size * nbCopied * nbUptodate |
Fired at the end of the retrieve process. |
pre-retrieve-artifact (since 2.1) |
* organisation * module * revision * artifact * type * ext * metadata * size * from * to |
Fired before an artifact is retrieved from the cache to a local location |
post-retrieve-artifact (since 2.1) |
* organisation * module * revision * artifact * type * ext * metadata * size * from * to |
Fired after an artifact is retrieved from the cache to a local location |
pre-publish-artifact (since 2.0) |
* organisation * module * revision * artifact * type * ext * resolver * file * overwrite |
Fired before an artifact is published into a repository |
post-publish-artifact (since 2.0) |
* organisation * module * revision * artifact * type * ext * resolver * file * overwrite * status |
Fired after an artifact is published into a repository. Note that this event is fired whether or not the publication succeeded. The "status" property can be checked to verify success. |
The child tag used for the dependency resolver must be equal to a name of a trigger type (either built-in or added with the typedef tag).
Child elements
| Element | Description | Cardinality |
|---|---|---|
any trigger |
adds a trigger to the list of registered triggers |
1..n |
Built-in Triggers
Ivy comes with 3 built-in triggers:
| Name | Description |
|---|---|
ant-build |
Triggers an Ant build. Note that by default the Ant build is triggered only once per build file, the property onlyonce can be set to false to change this. |
ant-call |
Calls a target in the current Ant build. |
log |
Logs a message on the console or in a log file. |
Common attributes
All triggers share some common attributes detailed here.
Among these attributes, you will find how to select when the trigger should be performed. You have to provide an event name, which is simple, but you can also use a filter expression. The syntax for this expression is very simple and limited:
-
you can use the = operator to compare an attribute (left operand) with a value (right operand).
-
you can use AND OR NOT as boolean operators
-
you cannot use parenthesis to change the precedence
| Attribute | Description | Required |
|---|---|---|
name |
the name of the trigger for identification purpose only |
Yes |
event |
the name of the event on which the trigger should be performed |
Yes |
filter |
a filter expression used to restrict when the trigger should be performed |
No, defaults to no filter |
Examples
<triggers>
<ant-build antfile="${ivy.settings.dir}/[module]/build.xml" target="publish"
event="pre-resolve-dependency" filter="revision=latest.integration"/>
</triggers>Triggers an Ant build of the Ant file ${ivy.settings.dir}/[module]/build.xml (where [module] is replaced by the name of the dependency resolved) with the target "publish", just before resolving a dependency with a latest.integration revision.
Note that by default the Ant build is triggered only once per build file. See below to see how to trigger the build more than once.
<triggers>
<ant-build antfile="${ivy.settings.dir}/[module]/build.xml" target="publish"
event="pre-resolve-dependency" filter="revision=latest.integration"
onlyonce="false"/>
</triggers>Same as before, but this time the builds will be triggered as many time as the dependency is resolved, instead of only once.
<triggers>
<ant-call target="unzip" prefix="dep"
event="post-download-artifact" filter="type=zip AND status=successful"/>
</triggers>Triggers an Ant call of the target unzip just after downloading a zip artifact, prefixing all parameters to the target with dep.
Here is how the target can look like:
<target name="unzip">
<echo>
unzipping artifact:
organisation=${dep.organisation}
module=${dep.module}
revision=${dep.revision}
artifact=${dep.artifact}
type=${dep.type}
ext=${dep.ext}
origin=${dep.origin}
local=${dep.local}
size=${dep.size}
file=${dep.file}
</echo>
<mkdir dir="${basedir}/out"/>
<unzip src="${dep.file}" dest="${basedir}/out"/>
</target><triggers>
<log file="ivy.log"
message='downloaded "${origin}" to "${file}" (${duration}ms - ${size}B)'
event="post-download-artifact" filter="status=successful"/>
</triggers>Logs any successful artifact download, with information on the source and destination, and details on download size and duration.
The file attribute is optional, the log trigger will output messages to console if it isn’t provided.
version-matchers
Tag: version-matchers
[since 1.4]
Defines a list of version matchers.
The child tag used for the version matcher must be equal to a name of a report outputter type (added with the typedef tag).
A version matcher is used to evaluate if a dependency version constraint matches a dependency version.
Attributes
| Attribute | Description | Required |
|---|---|---|
usedefaults |
when set to true, includes the built-in version matchers (Latest, Sub Revision, and Version Ranger Matcher). Exact Revision Matcher is always included |
No, defaults to false |
Child elements
| Element | Description | Cardinality |
|---|---|---|
any version matcher |
adds a version matcher to the list of available ones |
0..n |
Built-in Version Matchers
Exact Revision Matcher
A matcher that matches a dependency revision id to the module revision id using simple string equality.
Sub Revision Matcher
A matcher that matches all revisions starting with a specific prefix. The syntax is: [prefix]+
| Revision | Matches |
|---|---|
1.0.+ |
all revisions starting with '1.0.', like 1.0.1, 1.0.5, 1.0.a |
1.1+ |
all revisions starting with '1.1', like 1.1, 1.1.5, but also 1.10, 1.11 |
Latest (Status) Matcher
A matcher that matches versions based on their status. The predefined statuses in Ivy are release, milestone and integration. It’s possible to define your own statuses, see statuses for more details.
| Revision | Matches |
|---|---|
latest.integration |
all versions |
latest.milestone |
all modules having at least 'milestone' as status |
latest.release |
all modules having at least 'release' as status |
latest.[any status] |
all modules having at least the specified status |
Version Range Matcher
Range types are exhaustively listed by example in the table below.
| Revision | Matches |
|---|---|
[1.0,2.0] |
all versions greater or equal to 1.0 and lower or equal to 2.0 |
[1.0,2.0[ |
all versions greater or equal to 1.0 and lower than 2.0 |
]1.0,2.0] |
all versions greater than 1.0 and lower or equal to 2.0 |
]1.0,2.0[ |
all versions greater than 1.0 and lower than 2.0 |
[1.0,) |
all versions greater or equal to 1.0 |
]1.0,) |
all versions greater than 1.0 |
(,2.0] |
all versions lower or equal to 2.0 |
(,2.0[ |
all versions lower than 2.0 |
Version Pattern Matcher
The version pattern matcher allows for more flexibility in pattern matching at the cost of adding a matcher declaration in Ivy settings. A simple example is given below.
Settings.xml
<pattern-vm>
<match revision="foo" pattern="${major}\.${minor}\.\d+" args="major, minor" matcher="regexp"/>
</pattern-vm>Ivy.xml
<dependency org="acme" name="tool" rev="foo(1, 3)"/>The version pattern matcher may contain more than one match element. The matcher will attempt to match a dependency revision against each match in sequence, checking the revision tag (e.g. foo(..)) and then the pattern. Matcher types may be one of "regexp", "exact", "glob", or "exactOrRegexp". Glob pattern matching requires Apache ORO 2.0.8 or higher to be on the classpath.
Maven timestamped snapshot version matcher
[since 2.5]
Maven has the notion of timestamped snapshots, which essentially are snapshot versions of a particular Maven artifact, but have a specific timestamp associated with them so that the snapshot revision (which by nature are changing over time), can be traced back to the exact artifacts. Maven allows other artifacts to depend on such timestamped snapshots.
Ivy too allows such timestamped dependencies to be part of the module’s dependencies. For such dependencies to be properly parsed and resolved, a maven-tsnap-vm version matcher needs to be configured in the Ivy settings and ibiblio resolver must be one of the resolvers that are used for dependency resolution.
|
Note
|
Maven has a specific syntax for timestamped snapshot versions and only such versions are understood by Ivy. |
Configuring the maven-tsnap-vm can be done as follows in the Ivy settings file:
<ivysettings>
<version-matchers ...>
<maven-tsnap-vm/>
</version-matchers>
...An example timestamped snapshot dependency in an Ivy module would look like:
<ivy-module version="2.4">
<info organisation="org.apache.ivy"
module="maven-snapshot-deps-test"
revision="1.2.3"/>
<dependencies>
<dependency org="org.apache.ivy.maven-snapshot-test" name="foo-bar" rev="5.6.7-20170911.130943-1"/>
</dependencies>
</ivy-module>Notice the 5.6.7-20170911.130943-1 revision on the foo-bar dependency - that represents a timestamped snapshot. For this Ivy module to be resolved correctly, the Ivy settings file should be both backed by the maven-tsnap-vm version matcher and a m2compatible ibiblio resolver, so the settings file would typically look like:
<ivysettings>
<settings defaultResolver="m2"/>
<caches defaultCacheDir="${user.home}/.ivy/cache/"/>
<version-matchers usedefaults="true">
<maven-tsnap-vm/>
</version-matchers>
<resolvers>
<ibiblio name="m2" m2compatible="true" useMavenMetadata="true" root="file://${user.home}/.m2"/>
</resolvers>
</ivysettings>timeout-constraints
[since 2.5]
Ivy, internally, communicates with various remote systems for dealing with module descriptors and artifacts. This is done through various dependency resolvers that are configured in the Ivy settings. This communication typically involves opening a connection to the target system and reading content from those systems. As with all remote communication, certain systems can sometimes be slow or even unavailable on some occasions. timeout-constraints in Ivy settings allows you to configure timeouts that can then be used by Ivy while communicating with remote systems.
|
Note
|
Although, timeouts are most likely to be used by dependency resolvers, the setting up of timeouts through the use of timeout-constraints doesn’t really bother about where those timeouts are used. As such, it’s not an error to have timeout-constraints within a Ivy settings file which may never be referred to by any resolver.
|
Child elements
| Element | Description | Cardinality |
|---|---|---|
defines a new timeout-constraint |
0..n |
Examples
<timeout-constraints>
<timeout-constraint name="test-timeout-1" connectionTimeout="100" readTimeout="500"/>
<timeout-constraint name="test-timeout-2" readTimeout="20"/>
<timeout-constraint name="test-timeout-3" connectionTimeout="400"/>
<timeout-constraint name="test-timeout-4"/>
</timeout-constraints>Defines 4 timeout-constraint, each with a name and values for connectionTimeout and readTimeout. More details about the timeout-constraint element is explained in its documentation.
timeout-constraint
Tag: timeout-constraint
Defines a named timeout constraint that can then be referenced from other places of the Ivy settings file, like the resolvers.
Attributes
| Attribute | Description | Required |
|---|---|---|
name |
name of timeout constraint |
Yes |
connectionTimeout |
An integer value, in milliseconds, that will be used as the timeout while establishing a connection. |
No, defaults to |
readTimeout |
An integer value, in milliseconds, that will be used as the timeout while reading content from a resource to which an connection has been established. |
No, defaults to |
Examples
<timeout-constraints>
<timeout-constraint name="test-timeout-1" connectionTimeout="100" readTimeout="500"/>
<timeout-constraint name="test-timeout-2" readTimeout="20"/>
<timeout-constraint name="test-timeout-3" connectionTimeout="400"/>
<timeout-constraint name="test-timeout-4"/>
</timeout-constraints>Here we see 4 timeout constraints defined:
-
test-timeout-1uses a connection timeout of 200 milliseconds and read timeout of 500 milliseconds. -
test-timeout-2uses a read timeout of 20 milliseconds and lets the connection timeout default to -1. -
test-timeout-3uses a connection timeout of 400 milliseconds and lets the read timeout default to -1. -
test-timeout-4lets both the connection timeout and read timeout default to -1.
Ivy Files
Ivy use is entirely based on module descriptors known as "Ivy files". Ivy files are XML files, usually called ivy.xml, containing the description of the dependencies of a module, its published artifacts and its configurations.
Here is the simplest Ivy file you can write:
<ivy-module version="2.0">
<info organisation="myorg"
module="mymodule"/>
</ivy-module>If you want to see a sample module descriptor using almost all possibilities of Ivy files, check this one, with or without XSLT.
Before beginning the reference itself, it is required to have in mind the terminology defined in the main page of this reference documentation.
For those familiar with XML schema, the schema used to validate Ivy files can be found here. For those using XSD aware IDE, you can declare the XSD in your Ivy files to benefit from code completion / validation:
<?xml version="1.0" encoding="UTF-8"?>
<ivy-module version="2.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation=
"http://ant.apache.org/ivy/schemas/ivy.xsd">
<info organisation="myorg"
module="mymodule"/>
</ivy-module>Dynamic and resolved Ivy files
A module descriptor (Ivy file) is needed both before and after the publication of each revision of the module. Depending on the case, a module descriptor can be either dynamic or resolved.
Dynamic descriptor for module development
During the module development time, between publications, the descriptor helps in managing all the possibly changing dependencies of the module. For that purpose, development time Ivy files can declare dynamic dependencies to allow for a greater flexibility of use. Dynamic revision references like latest.integration or 1.0.+ are possible and may resolve to different artifacts at different times. Variables can be used for even more flexibility. Development time Ivy files are hence called dynamic, because they can produce different results over time. The dynamic Ivy files are normally considered source files and kept with them (under SCM control).
Resolved descriptors for publishing
At each publication, another kind of a module descriptor is needed to document the dependencies of the particular published revision of the module. For that purpose, the descriptor usually needs to be fixed as its dependencies should no longer change. In doing so, the published module revision gets fixed, explicitly resolved dependencies. No variables are allowed either. Such publication-friendly, static Ivy files are called resolved, because they should always produce the same results. The resolved Ivy files are comparable to published artifacts and are kept with them in a repository.
Resolved Ivy files are generated from their original dynamic Ivy files via the deliver task.
Note that although it is technically possible to publish module revisions with dynamic Ivy files, it is not a generally recommended practice.
Hierarchical Index
ivy-module
Tag: ivy-module
The root tag of any Ivy file (module descriptor).
Attributes
| Attribute | Description | Required |
|---|---|---|
version |
the version of the Ivy file specification - should be '2.0' with current version of Ivy |
Yes |
Child elements
| Element | Description | Cardinality |
|---|---|---|
contains information about the described module |
1 |
|
container for configuration elements |
0..1 |
|
container for published artifact elements |
0..1 |
|
container for dependency elements |
0..1 |
|
section to configure the conflict managers to use |
0..1 |
info
Tag: info Parent: ivy-module
Gives identification and basic information about the module this Ivy file describes.
(since 1.4) This tag supports extra attributes.
Attributes
| Attribute | Description | Required |
|---|---|---|
organisation |
the name of the organisation that is the owner of this module. |
Yes |
module |
the name of the module described by this Ivy file. |
Yes |
branch |
the branch of this module. (since 1.4) |
No, defaults to the default branch setting, or nothing if no default branch is configured |
revision |
the revision of this module. |
Yes in repository Ivy files, no in Ivy files to resolve |
status |
the status of this module. See terminology section for details |
No, default to |
publication |
the date of publication of this module. It should be given in this format: |
No, but it’s a good practice to set it with delivered Ivy files |
Child elements
| Element | Description | Cardinality |
|---|---|---|
identifies a parent Ivy file from which this descriptor inherits content |
0..n |
|
contains information about the licenses of the described module |
0..n |
|
describes who has contributed to write the Ivy file |
0..n |
|
describes in which public repositories this module can be found |
0..n |
|
describes how to use the module |
0..1 |
After the description, you can also place your own tags in your own namespace. This allow to provide some custom information about the module.
extends
Tag: extends Parent: info
[since 2.2]
Identifies an optional parent descriptor for this module. For complicated projects composed of many modules that have common configurations or dependencies, inheritance allows modules to share this information. Which parts of the parent descriptor are inherited can be controlled with the extendType attribute.
Supported extendType values are:
| Value | Description |
|---|---|
info |
Attributes of the info element are inherited from the parent. When an attribute appears in both child and parent, the child value is used. |
description |
The content of the info/description element is inherited from the parent. |
configurations |
Configurations defined in the parent descriptor are added to any configurations defined in the child descriptor. |
dependencies |
Dependencies defined in the parent descriptor are added to any dependencies defined in the child descriptor. |
licenses |
Licenses defined in the parent descriptor are added to any licenses defined in the child descriptor. |
all |
info, description, configurations, licenses and dependencies from the parent descriptor are merged into the child descriptor. |
Attributes
| Attribute | Description | Required |
|---|---|---|
organisation |
the organisation of the parent module |
Yes |
module |
the name of the parent module |
Yes |
revision |
the revision of the parent module. Can be fixed, a dynamic value, or range of revisions; see dependency for information on specifying revisions. |
Yes |
extendType |
which part(s) of the parent descriptor are inherited. Valid values are |
No, default is |
location |
A local filesystem path that should be searched for the parent descriptor. If the parent descriptor cannot be found at this location, it will be located using dependency resolvers like any normal dependency. This attribute is intended for development use. For example, child module descriptors appear in a source control directory with the parent module descriptor at a higher level. |
No, as long as the parent descriptor exists in an Ivy resolver |
license
Tag: license Parent: info
Gives information about a license of the described module.
Attributes
| Attribute | Description | Required |
|---|---|---|
name |
the name of the license. Try to respect spelling when using a classical license. |
Yes |
url |
an URL pointing to the license text. |
No, but it’s a good practice to indicate it |
ivyauthor
Tag: ivyauthor Parent: info
Gives information about who has contributed to write this Ivy file. It does NOT indicate who is the author of the module itself.
Attributes
| Attribute | Description | Required |
|---|---|---|
name |
the name of the author, as a person or a company. |
Yes |
url |
an URL pointing to where the author can be reached. |
No, but it’s a good practice to indicate it |
repository
Tag: repository Parent: info
Gives information about a public repository where the module can be found. This information is given as an indication, repositories being able to be down over time.
Attributes
| Attribute | Description | Required |
|---|---|---|
name |
the name of the repository. Try to respect spelling for common repositories (ibiblio, ivyrep, …) |
Yes |
url |
an URL pointing to the repository. |
Yes |
pattern |
an Ivy pattern to find modules on this repository |
No, but it’s recommended to indicate it. |
ivys |
|
No, defaults to |
artifacts |
|
No, defaults to |
description
Tag: description Parent: info
Describes the current module. This tag is the only one which can contain free text, including HTML. It is used to describe the module itself, usually in a single short phrase (it is not meant to replace the module description on the corresponding web site), and then gives all information necessary to use the module, especially information about public configurations, how and when to use them.
Attributes
| Attribute | Description | Required |
|---|---|---|
homepage |
the URL of the homepage of the module |
No, but it’s recommended to indicate it. |
configurations
Tag: configurations Parent: ivy-module
A container for configuration elements. If this container is not present, it is assumed that the module has one public configuration called default.
(since 2.2) You can define the default conf on this container by specifying the defaultconf attribute. This attribute defines the conf mapping to use when no conf mapping is specified for a dependency in this Ivy file.
(since 1.3) You can define a default conf mapping on this container by specifying the defaultconfmapping attribute.
This attribute modifies the way Ivy interprets conf mapping with no mapped conf. In this case, Ivy will look in the default conf mapping and use the conf mapping defined in the default conf mapping for the conf for which there is no mapped conf.
In order to maintain backwards compatibility with Ivy 2.1.0 and earlier, the defaultconfmapping also provides one additional function. If no defaultconf is specified (on either the configurations tag or the dependencies tag), the defaultconfmapping becomes the default configuration for dependencies in this Ivy file when no configuration is specified. In other words, in addition to altering the interpretation of individual configurations with no mapping, defaultconfmapping also performs exactly like defaultconf in the absence of a definition for defaultconf.
If several defaultconfmapping or defaultconf attributes are defined (in the configurations tag, one or several in an included configurations file, and/or in the dependencies tag, then it’s only the last definition of each property which is taken into account. The others will have no effect at all.
See examples below to clarify the behavior of these two attributes together.
(since 1.4) You can activate a confmappingoverride mode for all configurations, in which case the extending configurations will override the mappings of the configurations they extend from.
Attributes
| Attribute | Description | Required |
|---|---|---|
defaultconf |
the default conf to use in this Ivy file (since 2.2) |
No, defaults to no default conf |
defaultconfmapping |
the default conf mapping to use in this Ivy file (since 1.3) |
No, defaults to no default conf mapping |
confmappingoverride |
|
No, defaults to |
Child elements
Configuration mappings details
When Ivy parses your Ivy file, it will create (internally) modify the configuration mapping of your dependencies.
For instance, say you have:
<configurations defaultconfmapping="conf1->other1;conf2->other2">
<conf name="conf1"/>
<conf name="conf2" extends="conf1"/>
</configurations>
<dependencies>
<dependency name="other-module" conf="conf1"/>
</dependencies>When Ivy parses this file, it will construct the following dependency (in-memory only):
<dependency name="other-module" conf="conf1->other1"/>So, if you now resolve the conf2 configuration, you will only get the other1 dependencies of your other-module.
But when you set confmappingoverride to true, Ivy will construct the following dependency in memory:
<dependency name="other-module" conf="conf1->other1;conf2->other2"/>As you can see, the defaultmappings of the extending configurations are also added (although you didn’t explicitly defined them)
When you now resolve the conf2 configuration, you’ll get the other2 dependencies of your other-module.
Examples involving defaultconf and defaultconfmapping
The table below indicates how Ivy interprets the conf attribute according to how defaultconfmapping and defaultconf are set:
| defaultconf | defaultconfmapping | conf | Ivy interpretation |
|---|---|---|---|
|
|||
|
|
||
|
|
||
|
|
||
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
conf
Tag: conf Parent: configurations
Declares a configuration of this module. As described in the reference page, a configuration is a way to use or construct a module. Some modules may be used in different ways (think about hibernate which can be used inside or outside an application server), and this way may alter the artifacts you need (in the case of hibernate, jta.jar is needed only if it is used outside an application server). Moreover, a module may need some other modules and artifacts only at build time, and some others at runtime. All those different ways to use or build a module are called module configurations in Ivy.
The conf element in the configurations section declares one configuration. This declaration gives the name of the configuration declared, its visibility and the other configurations of the module it extends.
visibility is used to indicate whether or not a configuration can be used from other modules depending on this one. Thus a private configuration is only used for internal purpose (maybe at build time), and other modules cannot declare to depend on it.
A configuration can also extend one or several other ones of the same module. When a configuration extends another one, then all artifacts required in the extended configuration will also be required in the configuration that extends the other one. For instance, if configuration B extends configuration A, and if artifacts art1 and art2 are required in configuration A, then they will be automatically required in configuration B. On the other hand, artifacts required in configuration B are not necessarily required in configuration A.
This notion is very helpful to define configurations which are similar with some differences.
[since 1.4]
The extends attribute can use the following wildcards:
|
all other configurations |
|
all other public configurations |
|
all other private configurations |
A whole configuration can be declared as non transitive, so that all dependencies resolved in this configuration will be resolved with transitivity disabled. Note that the transitivity is disabled for all the configuration dependencies (including those obtained because this conf extends other ones), and only for this configuration (which means that a conf extending this one with transitivity enabled will get transitive dependencies even for dependencies being part of the non transitive configuration). This is very useful to build a compile configuration, for instance, forcing the dependency declaration on each direct dependency, with no risk to forget some because of transitivity.
This tag supports extra attributes.
Attributes
| Attribute | Description | Required |
|---|---|---|
name |
the name of the declared configuration |
Yes |
description |
a description for the declared configuration |
No |
visibility |
the visibility of the declared configuration.
|
No, defaults to |
extends |
a comma separated list of configurations of this module that the current configuration extends |
No, defaults to none |
transitive |
a boolean to indicate if this conf is transitive or not (since 1.4) |
No, defaults to |
deprecated |
indicates that this conf has been deprecated by giving the date of the deprecation. It should be given in this format: |
No, by default the conf is not deprecated |
Examples
<conf name="core" visibility="private"/>
<conf name="compile" extends="core" transitive="false" visibility="private"/>
<conf name="runtime" extends="compile" description="everything needed to run this module"/>Declares three configurations, core, compile and runtime, with only the runtime one accessible from other modules, and with the compile one being non transitive.
Therefore the core configuration will only be composed of dependencies declared in the core configuration itself, the compile configuration will be composed of all dependencies required in either core or compile configuration, but without transitivity (neither for core nor compile dependencies), and runtime will be composed of all dependencies, all transitively, including the dependencies declared only in compile.
include
Tag: include Parent: configurations
[since 1.3]
Include configurations specified in another file.
The included file should have a configurations tag as root tag, which follow the same specification as the configurations tag of the Ivy file.
This means that it can contain conf declarations, other file inclusions, and have attributes controlling conf mapping.
When delivering an Ivy file with such an inclusion, the included descriptor file is inlined, i.e. Ivy removes the dependency on the external file.
[since 2.5] Attributes inherited through included file are set on dependencies element due to the way module descriptor updater works currently.
Attributes
| Attribute | Description | Required |
|---|---|---|
file |
the file to include |
Yes |
Examples
<ivy-module version="1.0">
<info organisation="myorg"
module="mymodule"/>
<configurations>
<include file="path/to/included-configurations.xml"/>
<conf name="conf3"/>
</configurations>
<dependencies>
<dependency name="mymodule1" rev="1.0"/>
<dependency name="mymodule2" rev="2.0" conf="conf2,conf3->*"/>
</dependencies>
</ivy-module>with included-configurations.xml like this:
<configurations defaultconfmapping="*->@">
<conf name="conf1" visibility="public"/>
<conf name="conf2" visibility="private"/>
</configurations>Defines 3 configurations, conf1, conf2 and conf3. mymodule1 is required in each configuration, with for each the same configuration (conf1 is needed in conf1, conf2 in conf2, and conf3 in conf3) due to the defaultconfmapping defined in the included file.
publications
Tag: publications Parent: ivy-module
Container for artifact elements, used to describe the artifacts published by this module.
If this container is not present, it is assumed that the module has one artifact, with the same name as the module, and published in all module configurations.
Thus if you have a module which publishes no artifacts (a sort of virtual module, made only to integrate several other modules as a whole), you have to include a publications element with no artifact sub element.
Attributes
| Attribute | Description | Required |
|---|---|---|
defaultconf |
comma separated list of public configurations in which artifacts are published by default (when no specific configurations are set on the artifact element).
|
No, defaults to |
Child elements
| Element | Description | Cardinality |
|---|---|---|
declares a published artifact for this module |
0..n |
artifact
Tag: artifact Parent: publications
Declares an artifact published by this module. This is especially useful for other modules depending on this one. They thus get all published artifacts belonging to the configurations asked. Indeed, each published artifact declares in which public configuration it is published. Thus a module depending on this module only get artifacts marked with the asked configurations, taking into account configurations extension (see configuration declaration).
The configurations in which an artifact is published can be configured in two ways:
-
confattribute on anartifactelement -
confsubelement
The two are equivalent, it is only a matter of preference. However, do not mix both for one artifact.
[since 1.4]
The artifact element has default values for all its attributes, so if you want to declare a default artifact you can just declare it like that:
<artifact/>If this is the only artifact declared, then it’s equivalent to having no publication section at all.
It is possible to give an url at which artifacts can be found. This is not mandatory, and even not recommended. This is only a convenient way to deal with an existing repository with a bad layout, but should not be avoided in an enterprise repository.
This tag supports extra attributes.
(since 2.4) This tag supports the 'packaging' attributes; complete documentation can be found in the concept page.
Attributes
| Attribute | Description | Required |
|---|---|---|
name |
the name of the published artifact. This name must not include revision. |
No, defaults to the name of the module |
type |
the type of the published artifact. It’s usually its extension, but not necessarily. For instance, Ivy files are of type |
No, defaults to |
ext |
the extension of the published artifact |
No, defaults to the value of |
conf |
comma separated list of public configurations in which this artifact is published.
|
No, defaults to |
url |
an URL at which this artifact can be found if it isn’t located at the standard location in the repository (since 1.4) |
No, defaults to no URL |
packaging |
a comma separated list of packaging types (since 2.4) |
No, defaults to no packaging |
Child elements
| Element | Description | Cardinality |
|---|---|---|
indicates a public configuration in which this artifact is published |
0..n |
Examples
<artifact/>Declares an artifact with the name of the module as name, type and ext jar, and published in all configurations.
<artifact name="foo-src" type="source" ext="zip" conf="src"/>Declares an artifact foo-src, of type source with extension zip, and published in the src configuration.
<artifact name="foo" url="http://www.acme.com/repository/barbaz/foo-1.2-bar.jar"/>Declares an artifact foo, of type and extension jar' located at the URL http://www.acme.com/repository/barbaz/foo-1.2-bar.jar. This URL will only be used if the artifact cannot be found at its standard location.
conf
Tag: conf Parent: artifact
Indicates a public configuration in which enclosing artifact is published.
Attributes
| Attribute | Description | Required |
|---|---|---|
name |
the name of the module public configuration in which this artifact is published.
|
Yes |
dependencies
Tag: dependencies Parent: ivy-module
Container for dependency elements, used to describe the dependencies of this module. If this container is not present, it is assumed that the module has no dependencies at all.
This container provides two similar behaviors described below. (See configurations doc page for more details about these behaviors).
(since 1.1) defaultconf defines the conf attribute to use when no conf is defined for a dependency in this Ivy file. It is only used when no conf mapping is defined, and has no influence in other cases.
(since 1.3) defaultconfmapping influences the way that a conf mapping with no mapped conf is interpreted.
(since 2.2) Attributes defaultconf and defaultconfmapping can be used together. In earlier versions, if both defaultconf and defaultconfmapping are defined, it’s the defaultconfmapping that is used.
(since 1.4) You can activate a confmappingoverride mode for all configurations, in which case the extending configurations will override the mappings of the configurations they extend from.
Attributes
| Attribute | Description | Required |
|---|---|---|
defaultconf |
the default configuration to use when none is specified in a dependency. (since 1.1) |
No, defaults to |
defaultconfmapping |
the default configuration mapping to use in this Ivy file. (since 1.3) |
No, defaults to no default conf mapping |
confmappingoverride |
|
No, defaults to |
Child elements
Note: as specified by the ivy.xsd, the children elements are ordered; first must come the dependency elements, then the exclude elements, then the override elements, and then the conflict elements.
| Element | Description | Cardinality |
|---|---|---|
declares a dependency for this module |
0..n |
|
excludes artifacts, modules or whole organizations from the set of dependencies of this module (since 2.0) |
0..n |
|
specifies an override mediation rule, overriding the revision and/or branch requested for a transitive dependency (since 2.0) |
0..n |
|
specifies a conflict manager for one or several dependencies (since 2.0) |
0..n |
dependency
Tag: dependency Parent: dependencies
Declares a dependency for this module. A dependency is described by the module on which the current module depends (identified by its name, organisation and revision), and a mapping of configurations.
Fixed and dynamic revisions
The revision can be given as a fixed one (1.5.2, for instance) or as a latest (or dynamic) one. Several possibilities for dynamic revisions are implemented in Ivy:
-
latest.integration
selects the latest revision of the dependency module. -
latest.[any status](since 1.4)
selects the latest revision of the dependency module with at least the specified status.
For instance,latest.milestonewill select the latest version being either amilestoneor arelease, andlatest.releasewill only select the latestrelease. Note that in order to find the latest revision with the appropriate status Ivy has to parse all the Ivy files in your repository from the last one until it finds such a revision. Hence don’t be surprised if the resolution slow down. See also statuses to see how to configure module statuses. -
end the revision with a
+
selects the latest sub-revision of the dependency module. For instance, if the dependency module exists in revision 1.0.3, 1.0.7 and 1.1.2, "1.0.+" will select 1.0.7. -
version ranges (since 1.4)
mathematical notation for ranges can be used to match a range of version.
Examples:
[1.0,2.0]matches all versions greater or equal to 1.0 and lower or equal to 2.0
[1.0,2.0[matches all versions greater or equal to 1.0 and lower than 2.0
]1.0,2.0]matches all versions greater than 1.0 and lower or equal to 2.0
]1.0,2.0[matches all versions greater than 1.0 and lower than 2.0
[1.0,)matches all versions greater or equal to 1.0
]1.0,)matches all versions greater than 1.0
(,2.0]matches all versions lower or equal to 2.0
(,2.0[matches all versions lower than 2.0
(since 1.4) If you don’t find a way to expression your dependency version constraint among these, you can plug your own. The way to determine which revision is the "latest" between two is configurable through the use of pluggable LatestStrategy. See Ivy main concepts for details about this.
Revision constraint
[since 2.0]
The dependency tag supports two revision attributes: rev, corresponding to the default required dependency revision, and revConstraint, corresponding to a dynamic revision constraint applied on this dependency.
Depending on the resolve mode used, the actual revision used during dependency resolution may vary. These revisions usually differ only for modules published in a repository. When deliver is used, dynamic version constraints are replaced by a static version constraint, to help build reproducibility. However, the information of the original version constraint is not lost, but rather put in the revConstraint attribute. This ensures better metadata in the repository while still allowing easier build reproducibility.
Configurations mapping
This mapping indicates which configurations of the dependency are required in which configurations of the current module, also called master configurations.
There are several ways to declare this mapping of configurations, choose depending more on preference than on possibilities. Try to avoid mixing usage in a single dependency element: do not use both nested and inline mapping declaration.
The first way to declare this mapping is called the inline mapping. It is maybe the less natural at first, but it’s powerful and concise. Inline mapping can take several forms.
Specify one configuration name
This means that in this master configuration the same dependency configuration is needed (except if a defaultconfmapping has been specified in this Ivy file, see configurations for details, or table below for examples).
For instance, if the current module has defined a configuration named ‘runtime’, and the dependency too, then having an inline mapping configuration set to ‘runtime’ means that in the runtime master configuration the runtime dependency configuration is required.
The examples on the dependency on the configurations page explain how Ivy interprets the conf attribute according to how defaultconfmapping and defaultconf is set.
Specify a configuration mapping using the -> operator
It is separating a comma separated list of master configurations (left operand) of a comma separated list of dependency configurations (right operand).
A good way to remember which side is for the master configuration (i.e. the configuration of the module defining the dependency) and which side is for the dependency configuration is to read the -> as "depends on".
In this case, all specified dependency configurations are required in all specified master configurations.
For instance, A, B, C -> E, F means that dependency configurations E and F are required in master configurations A, B and C.
Note that you can use the wildcard * as a configuration name, meaning that all configurations (either master or dependency public ones depending on the side) are wanted. For instance, * -> B, C means that B & C dependency configurations are required in all master configurations.
(since 1.4) you can use * wildcard followed by negated configurations to mean all but xxx. For instance, *, !A, !B -> X means that X dependency configuration is required in all master configurations except A and B.
(since 1.2) @ also has a special meaning as a right operand of the dependency mapping, it means map to self. This is particularly useful with *, *->@ meaning that all configurations of the module maps to their equivalent (same name) in the dependency.
(since 1.4) # can be used as right side operand to mean this configuration, and thus refers to the configuration being resolved. It is slightly similar to @, except that it takes into account the configuration being actually resolved in case of a configuration extending another one.
Example: Let’s foo be a module with two configurations, A and B, B extending A. Then a dependency declaring conf A-># will get A dep conf in its confs A (when resolving A, Ivy will find interpret the symbol as A) and B dep conf in its conf B (when resolving B, Ivy will interpret the symbol as B, even if this dependency is only required because of the A dependency).
If you don’t understand really how this works, do not use it :-)
(since 1.4) % can be used as left side operand to mean "all the other configurations". This can be useful when you only have a specific mapping for some configurations and a default mapping for all the others. For instance, test->runtime;%->default means that the test configuration is mapped to the runtime configuration, but all the other configurations are mapped to the default configuration.
(since 1.3) a fallback mechanism can be used when you are not sure that the dependency will have the required conf. You can indicate to Ivy that you want one configuration, but if it isn’t present, use another one. The syntax for specifying this adds the fallback conf between parenthesis right after the required conf.
For instance, test->runtime(default) means that in the test configuration of the module the runtime conf of the dependency is required, but if doesn’t exist, it will use the default conf instead. If default conf doesn’t exist then it will be considered as an error. Note that the * wildcard can be used as fallback conf.
[since 2.1]
It is also possible to define dependencies on configuration intersections. A configuration intersection is defined using a + sign to separate the configuration (eg A+B means the intersection of configuration A and B). In that case only artifacts and dependencies defined in both configurations in the dependency will be part of the master configuration defining the dependency on the configuration intersection.
Configuration intersections can also be used when specifying the confs to resolve.
Moreover, the mapping *->@ is handled as a specific case with configuration intersections: it maps also the intersections. So if one resolve conf A+B in a module which defines a dependency with mapping *->@, the mapping *->@ is interpreted as A+B->A+B so the intersection of A and B will be resolved in the dependency.
You can refer to a group of configurations sharing the same value for an attribute as left side part of the dependency mapping. The syntax is *[att=value] where att is the name of the attribute shared by the configurations of the group, and value is the value for this attribute that configurations must have to be part of the group. This is especially useful with extra attributes.
For instance, if you have:
<configurations>
<conf name="red" e:axis="color"/>
<conf name="blue" e:axis="color"/>
<conf name="windows" e:axis="platform"/>
<conf name="linux" e:axis="platform"/>
</configurations>Then you can do:
<dependency org="acme" name="foo" rev="2.0" conf="*[axis=platform]->default"/>To map the windows and linux configurations (the one which have the attribute axis equal to platform) to the default configuration of foo.
(since 1.4) You can add simple conditions in the right side of the dependency mapping. This is done by adding a condition between [ and ]. If the condition evaluates to true, the mapping is performed. If the condition evaluates to false, the mapping will be ignored. For instance, test->[org=A]runtime,[org=B]default means that the test configuration will be mapped to the runtime conf for the dependencies of organisation A and to the default conf for dependencies of organisation B.
Specify a semi-column separated list of any of the previous specs.
In this case, it is the union of the mapping which is kept. For instance, A -> B; * -> C means that B conf is needed in A conf and C conf is need in all master conf… so both B & C dep conf are required in A master conf
If you prefer more verbose mapping declaration, everything is also possible with sub elements mapping declaration.
Artifact restriction
Moreover, the dependency element also supports an artifact restriction feature (since 0.6). See dependency artifact for details.
Forcing revision
Finally, the dependency element also supports an a force attribute (since 0.8), which gives an indication to conflict manager to force the revision of a dependency to the one given here. See conflict manager for details.
(since 1.4) This tag supports extra attributes
Attributes
| Attribute | Description | Required |
|---|---|---|
org |
the name of the organisation of the dependency. |
No, defaults to the master module organisation |
name |
the module name of the dependency |
Yes |
branch |
the branch of the dependency. (since 1.4) |
No, defaults to the default branch setting for the dependency. |
rev |
the revision of the dependency. See above for details. |
Yes |
revConstraint |
the dynamic revision constraint originally used for this dependency. See above for details. |
No, defaults to the value of |
force |
a boolean to give an indication to conflict manager that this dependency should be forced to this revision (see conflict manager) |
No, defaults to |
conf |
an inline mapping configuration spec (see above for details) |
No, defaults to |
transitive |
|
No, defaults to |
changing |
|
No, defaults to |
Child elements
| Element | Description | Cardinality |
|---|---|---|
defines configuration mapping has sub element |
0..n |
|
defines artifacts inclusion - use only if you do not control dependency Ivy file |
0..n |
|
defines artifacts exclusion - use only if you do not control dependency Ivy file |
0..n |
Examples
<dependency org="jayasoft" name="swtbinding" revision="0.2"/>Declares a dependency on the module swtbinding from jayasoft in its revision 0.2. All the configuration of this dependency will be included in all configurations of the module in which the dependency is declared.
<dependency org="jayasoft" name="swtbinding" branch="fix-103" revision="latest.integration"/>Same as above except that it will take the latest revision on the branch 'fix-103' instead of revision '0.2'.
<dependency name="mymodule" revision="latest.integration" conf="test->default"/>Declares a dependency on the module mymodule from the same organisation as the module in which the dependency is declared. The latest available revision of this dependency will be used. This dependency will only be included in the test configuration of the module, and it’s only the default configuration of the dependency which will be included.
<dependency org="apache" name="commons-lang" revision="2.0" force="true" conf="default"/>Declares a dependency on the module commons-lang from apache, in revision 2.0. The revision 2.0 will be used even if another dependency declares itself a dependency on another version of commons-lang. Moreover, if no defaultconfmapping is defined, only the default conf of commons-lang will be used in the default conf of the master module. If *->runtime was declared as defaultconfmapping, then the runtime conf of commons-lang would be included in the default conf of the master module. Note that whatever the defaultconfmapping is, the dependency only be included in the default conf of the master module. The defaultconfmapping only changes the required dependency confs.
<dependency org="foo" name="bar" revision="3.0" transitive="false" conf="default->@;runtime,test->runtime"/>Declares a dependency on the module bar from foo, in revision 3.0. The dependencies of bar will themselves not be included due to the setting of transitive. The default dependency conf will be included in the default master conf, and the runtime dependency conf will be included in both the runtime and test master conf.
<dependency org="foo" name="bar" revision="3.0" changing="true" conf="compile->runtime(default)"/>Declares a dependency on the module bar from foo, in revision 3.0. This revision is considered to be able to change (changing="true"), so even if it is already in Ivy’s cache, Ivy will check if a revision is a more recent last modified date is available on the repository. The runtime conf of bar is required in the compile conf of the master module, but if bar doesn’t define a runtime conf, then the default conf will be used.
conf
Tag: conf Parent: dependency
Describes a configuration mapping for a dependency. See also the inline configuration mapping in dependency element.
Attributes
| Attribute | Description | Required |
|---|---|---|
name |
the name of the master configuration to map.
|
Yes |
mapped |
a comma separated list of dependency configurations to which this master configuration should be mapped |
No, default to the same configuration as master one, unless nested mapped elements are specified |
Child elements
| Element | Description | Cardinality |
|---|---|---|
map dependency configurations for this master configuration |
0..n |
mapped
Tag: mapped Parent: conf
Describes a mapped dependency configuration for a master configuration.
Attributes
| Attribute | Description | Required |
|---|---|---|
name |
the name of the dependency configuration mapped.
|
Yes |
artifact
Tag: artifact Parent: dependency
This feature gives you more control on a dependency for which you do not control its Ivy file. It enables to specify the artifacts required, if the dependency has no Ivy file.
Indeed, when a module has no Ivy file, it is assumed that it publishes exactly one artifact having the same name as the module itself. But when this module publishes more artifacts, or simply does not respect the name rule, and if you cannot deliver an Ivy file for it (because you do not control the repository, for instance - think about Maven ibiblio repository, to give no name), then this feature lets you specify the artifact names you want to get.
Each artifact specification can be given in the context of particular master configurations. By default, if no configuration is specified, artifacts specification apply to all master configurations. But you can specify that a specification applies only to one or several master configurations, using either inline or nested conf specification. In this case, do not forget that if you do not specify any specification for a particular configuration, then no specification will apply for this configuration and it will be resolved not taking into account any specification.
For instance, imagine you have A, B & C master configurations. If you specify art1 in A & B and art2 in A, then C will not be specified at all, and will thus assume the default artifact. To prevent this, you have to specify a configuration mapping for the dependency, mapping only A & B to some or all dependency configurations.
Example:
<dependency org="yourorg" name="yourmodule9" rev="9.1" conf="A,B->default">
<artifact name="art1" type="jar" conf="A,B"/>
<artifact name="art2" type="jar" conf="A"/>
</dependency>(since 1.4) It’s possible to indicate the URL at which the artifact can be found. This is not mandatory, and even not recommended with an enterprise repository. Note that Ivy will always look at the location where the artifact should be and only use the URL if it cannot be found at the standard location in the repository.
(since 1.4) This tag supports extra attributes.
(since 2.0) This feature can also be used for modules having their own module descriptor, but which doesn’t declare an artifact you know that is published. Note that in this case artifacts declared to be published by the dependency will be ignored, so do not forget to include all artifacts you want.
Attributes
| Attribute | Description | Required |
|---|---|---|
name |
the name of an artifact of the dependency module |
Yes |
type |
the type of the artifact of the dependency module |
Yes |
ext |
the extension of the artifact of the dependency module |
No, defaults to type |
conf |
comma separated list of the master configurations in which this artifact should be included.
|
No, defaults to |
url |
an URL where this artifact can be found if it isn’t present at the standard location in the repository (since 1.4) |
No, defaults to no URL |
Child elements
| Element | Description | Cardinality |
|---|---|---|
configuration in which the artifact should be included |
0..n |
Examples
<dependency org="foo" name="bar" rev="1.0">
<artifact name="baz" type="jar"/>
</dependency>Declares a dependency on module bar which only publish one artifact: baz.jar.
<dependency org="foo" name="bar" rev="1.0">
<artifact name="baz" type="jar" url="http://www.acme.com/repository/bar/baz-1.0-acme.jar"/>
</dependency>Same as above, except that if the artifact is not found at its standard location, Ivy will use http://www.acme.com/repository/bar/baz-1.0-acme.jar to download it.
<dependency org="foo" name="bar" rev="1.0">
<include name="*"/>
<artifact name="baz" type="source" ext="jar"/>
</dependency>Declares a dependency on module bar for which all artifacts declared will be used (thanks to the include tag) plus an artifact baz of type source and ext jar (which is not declared in module bar module descriptor).
conf
Tag: conf Parent: artifact
Specify a configuration in which the enclosing artifact specification should be included.
Attributes
| Attribute | Description | Required |
|---|---|---|
name |
the name of the master configuration in which the enclosing artifact should be included |
Yes |
exclude
Tag: exclude Parent: dependency
This feature gives you more control on a dependency for which you do not control its Ivy file. It enables to restrict the artifacts required, by excluding artifacts being published by the dependency or any of its transitive dependencies, even if configuration does not provide a good separation of published artifacts.
The same principle concerning configuration as for include applies to this exclude feature (see the include feature).
Note that exclusion is always done AFTER inclusion has been done.
(since 1.3) This exclude feature can also be used not only to exclude artifacts but also to exclude whole modules. Indeed when you exclude artifacts, it doesn’t prevent Ivy from searching for the module itself, and resolving the dependencies of the module. But you can also exclude the entire module, which means that the module will not be downloaded at all, and so its own dependencies will not be resolved. For sure, this is usually done to exclude not a direct dependency but an indirect one. To exclude a whole module, you just have to not specify any artifact name, type and ext in your exclude rule. For instance:
<dependency name="A" rev="1.0">
<exclude module="B"/>
</dependency>(since 2.0) A module wide exclude can also be used to exclude dependencies for the whole module (and not only in the context of one dependency as it is the case here).
Attributes
| Attribute | Description | Required |
|---|---|---|
org |
the organisation of the dependency module or artifact to exclude, or a regexp matching this organisation (since 1.3) |
No, defaults to |
module |
the name of the dependency module or the artifact to exclude, or a regexp matching this module name (since 1.3) |
No, defaults to |
name |
the name of an artifact of the dependency module to add to the exclude list, or an expression matching this name (see |
No, defaults to |
type |
the type of the artifact of the dependency module to add to the exclude list, or a regexp matching this name |
No, defaults to |
ext |
the extension of the artifact of the dependency module to add to the exclude list, or an expression matching this name (see |
No, defaults to the value of |
matcher |
the matcher to use to match the modules to excludes (since 1.3) |
No, defaults to |
conf |
comma separated list of the master configurations in which this artifact should be excluded.
|
No, defaults to |
Child elements
| Element | Description | Cardinality |
|---|---|---|
configuration in which the artifact should be excluded |
0..n |
conf
Tag: conf Parent: artifact
Specify a configuration in which the enclosing artifact exclusion should be included.
Attributes
| Attribute | Description | Required |
|---|---|---|
name |
the name of the master configuration in which the enclosing artifact should be excluded |
Yes |
include
Tag: include Parent: dependency
This feature gives you more control on a dependency for which you do not control its Ivy file. It enables to restrict the artifacts required by including only the artifacts given here, even if configuration does not provide a good separation of published artifacts.
Each artifact restriction can be given in the context of particular master configurations. By default, if no configuration is specified, artifact restrictions apply to all master configurations. But you can specify that a restriction applies only to one or several master configurations, using either inline or nested conf specification. In this case, do not forget that if you do not specify any restriction for a particular configuration, then no restriction will apply for this configuration and it will be resolved not taking any restriction into account.
For instance, imagine you have A, B & C master configurations. If you restrict to art1 in A & B and art2 in A, then C will not be restricted at all, and will thus get all artifacts of all dependency configurations if you do not specify a configuration mapping. To prevent this, you have to specify a configuration mapping for the dependency, mapping only A & B to some or all dependency configurations.
Example:
<dependency org="yourorg" name="yourmodule9" rev="9.1" conf="A,B->default">
<include name="art1" type="jar" conf="A,B"/>
<include name="art2" type="jar" conf="A"/>
</dependency>Attributes
| Attribute | Description | Required |
|---|---|---|
name |
the name of an artifact of the dependency module to add to the include list, or an expression matching this name (see |
No, defaults to |
type |
the type of the artifact of the dependency module to add to the include list, or an expression matching this name (see |
No, defaults to |
ext |
the extension of the artifact of the dependency module to add to the include list, or an expression matching this name (see |
No, defaults to the value of |
matcher |
the matcher to use to match the modules to include (since 2.0) |
No, defaults to |
conf |
comma separated list of the master configurations in which this artifact should be included.
|
No, defaults to |
Child elements
| Element | Description | Cardinality |
|---|---|---|
configuration in which the artifact should be included |
0..n |
conf
Tag: conf Parent: include
Specify a configuration in which the enclosing artifact inclusion should be included.
Attributes
| Attribute | Description | Required |
|---|---|---|
name |
the name of the master configuration in which the enclosing artifact should be included |
Yes |
exclude
Tag: exclude Parent: dependencies
[since 2.0]
This feature gives you more control on a dependency for which you do not control its Ivy file. It allows to exclude artifacts, modules or organizations from the list of dependencies for the whole module.
It is very similar to the dependency exclude element, except that it applies to a whole module, which can be very useful when a lot of dependencies transitively bring a module you don’t want.
Attributes
| Attribute | Description | Required |
|---|---|---|
org |
the organization of the dependency module or artifact to exclude, or a regexp matching this organization |
No, defaults to |
module |
the name of the dependency module or the artifact to exclude, or a regexp matching this module name |
No, defaults to |
artifact |
the name of an artifact of the dependency module to add to the exclude list, or an expression matching this name (see |
No, defaults to |
type |
the type of the artifact of the dependency module to add to the exclude list, or a regexp matching this name |
No, defaults to |
ext |
the extension of the artifact of the dependency module to add to the exclude list, or an expression matching this name (see |
No, defaults to the value of |
matcher |
the matcher to use to match the modules to excludes |
No, defaults to |
conf |
comma separated list of the master configurations in which this artifact should be included.
|
No, defaults to |
override
Tag: override Parent: dependencies
[since 2.0]
Specify an override mediation rule, overriding the revision and/or branch requested for a transitive dependency.
This can be useful when a direct dependency is bringing a transitive dependency for which you want to change the revision, without actually declaring a dependency on it (because the module doesn’t actually depend on it) and without using conflict management for this purpose (maybe because there is no conflict at all, or because you want to bypass conflict management for this particular transitive dependency).
Overriding is done before any else, in a phase called dependency descriptor mediation. The transitive dependency then behaves exactly as if it were declared with the new value.
Note that even though no attribute is required, it makes no sense to set no attributes at all. It would mean that overriding is triggered for all transitive dependencies, but doesn’t override anything. Most of the time, at least org or module should be set to override only a subset of transitive dependencies, and at least branch or rev should be set to actually override something.
Attributes
| Attribute | Description | Required |
|---|---|---|
org |
the name, or an expression matching the name of organisation to which overriding should be applied (see matcher attribute below) |
No, defaults to |
module |
the name, or an expression matching the name of module to which overriding should be applied (see matcher attribute below) |
No, defaults to |
branch |
the branch to set for all the overridden dependency descriptors |
No, by default branch is not overridden |
rev |
the revision to set for all the overridden dependency descriptors |
No, by default revision is not overridden |
matcher |
the matcher to use to match the modules for which the conflict manager should be used |
No, defaults to |
conflict
Tag: conflict Parent: dependencies
[since 2.0]
Specify a a conflict manager for one or several dependencies. The way to specify a conflict manager is by giving indication to which dependencies the conflict manager applies (by giving organisation and module names or name regexp), and then specifying the conflict manager, either by giving its name or by specifying a fixed revision list, in which case a fixed conflict manager is used.
The list of built-in conflict managers available is listed on the conflict manager settings page.
Conflict managers are used during the resolve operation, i.e. when Ivy analyses the graph of dependencies and downloads corresponding Ivy files and artifacts. Managing conflicts at resolve time minimizes downloads: when a module is evicted by a conflict manager, it is not downloaded.
There are two things optimized during conflict resolution: download of artifacts and download of Ivy files. The first is always ensured by Ivy, i.e. artifacts of a module evicted will never be downloaded. The second is not as simple to handle because in order to know what the conflicts are, Ivy needs to know the dependency graph, and in order to know the dependency graph, it has to download Ivy files. But Ivy is highly optimized for this too, and it tries to evict modules as soon as possible. That’s why the order of dependencies is important for download optimization. Indeed, Ivy traverses the dependency graph in the order in which dependencies are declared in the Ivy files, and each time it encounters a dependency on a module, it first checks if there is a conflict on this module, and if this is the case, it asks the conflict manager to resolve the conflict. Then if the module is evicted, it does not download its Ivy file, and the whole branch is not traversed, which can save a lot of time.
If no specific conflict manager is defined, a default conflict manager is used for all modules. The current default conflict manager is the latest-revision conflict manager.
Attributes
| Attribute | Description | Required |
|---|---|---|
org |
the name, or an expression matching the name of organisation to which this conflict manager should apply (see |
No, defaults to |
module |
the name, or an expression matching the name of module to which this conflict manager should apply (see |
No, defaults to |
manager |
the name of the conflict manager to use |
Exactly one of two |
rev |
a comma separated list of revisions this conflict manager should select |
|
matcher |
the matcher to use to match the modules for which the conflict manager should be used |
No, defaults to |
conflicts
Tag: conflicts Parent: ivy-module
(since 2.0) The conflicts section is deprecated. Use conflict instead.
Container for conflict manager elements, used to indicate how conflicts should be resolved for this module.
The list of built-in conflict managers available is listed in the conflict manager settings page.
Conflict managers are used during the resolve operation, i.e. when Ivy analyses the graph of dependencies and downloads corresponding Ivy files and artifacts. Managing conflict at resolve time minimizes downloads: when a module is evicted by a conflict manager, it is not downloaded.
There are two things optimized during conflict resolution: download of artifacts and download of Ivy files. The first is always ensured by Ivy, i.e. artifacts of a module evicted will never be downloaded. The second is not as simple to handle because in order to know what the conflicts are Ivy needs to know the dependency graph, and in order to know the dependency graph, it has to download Ivy files. But Ivy is highly optimized for this too, and it tries to evict modules as soon as possible.
That’s why the order of dependencies is important for download optimization. Indeed Ivy traverses the dependency graph in the order in which dependencies are declared in the Ivy files, and each time it encounters a dependency on a module, it first checks if there is a conflict on this module, and if this is the case, it asks the conflict manager to resolve the conflict. Then if the module is evicted, it does not download its Ivy file, and the whole branch is not traversed, which can save a lot of time.
If this container is not present, a default conflict manager is used for all modules. The current default conflict manager is the latest-revision conflict manager.
Child elements
| Element | Description | Cardinality |
|---|---|---|
declares a conflict manager for this module |
1..n |
manager
Tag: manager Parent: conflicts
(since 2.0) the conflicts section is deprecated. Use conflict instead.
Specify a conflict manager for one or several dependencies.
The way to specify a conflict manager is by giving indication to which dependencies the conflict manager applies (by giving organisation and module names or name regexp), and then specifying the conflict manager, either by giving its name or by specifying a fixed revision list, in which case a fixed conflict manager is used.
See Conflict Manager for details on conflict managers in general.
Attributes
| Attribute | Description | Required |
|---|---|---|
org |
the name, or an expression matching the name of organisation to which this conflict manager should apply (see |
No, defaults to |
module |
the name, or an expression matching the name of module to which this conflict manager should apply (see |
No, defaults to |
name |
the name of the conflict manager to use |
Exactly one of two |
rev |
a comma separated list of revisions this conflict manager should select |
|
matcher |
the matcher to use to match the modules for which the conflict manager should be used (since 1.3) |
No, defaults to |
Ant Tasks
The main and most frequent way to use Ivy is from an Ant build file. However, Ivy can also be run as a standalone application.
If you use Ant version 1.6.0 or superior, you just have to add Ivy’s namespace to your project (xmlns:ivy="antlib:org.apache.ivy.ant" attribute of your project tag), and you can call Ivy tasks.
If you want to make your build handle ivy.jar in either Ant lib dir or a local lib dir, you can use a taskdef like this:
<path id="ivy.lib.path">
<fileset dir="path/to/dir/with/ivy/jar" includes="*.jar"/>
</path>
<taskdef resource="org/apache/ivy/ant/antlib.xml"
uri="antlib:org.apache.ivy.ant" classpathref="ivy.lib.path"/>Combined with the antlib definition in the project namespace, it will load Ivy classes either from your Ant lib or a local directory (path/to/dir/with/ivy/jar in this example).
If you use Ant 1.5.1 or superior, you have to define the tasks you use in your build file. For instance:
<taskdef name="ivy-configure" classname="org.apache.ivy.ant.IvyConfigure"/>
<taskdef name="ivy-resolve" classname="org.apache.ivy.ant.IvyResolve"/>
<taskdef name="ivy-retrieve" classname="org.apache.ivy.ant.IvyRetrieve"/>
<taskdef name="ivy-deliver" classname="org.apache.ivy.ant.IvyDeliver"/>
<taskdef name="ivy-publish" classname="org.apache.ivy.ant.IvyPublish"/>Note: the tasks listed above are non exhaustive. For a complete list of tasks with the corresponding classes, see the antlib.xml file in Git repository or the jar file you use.
Then you can use the tasks, but check their name, following samples assume you use the Ivy namespace (ivy:xxx tasks), whereas with Ant 1.5 you cannot use namespace, and should therefore use ivy-xxx tasks if you have added the taskdefs as above.
If you use an Ant version lower than 1.5.1, you can not use the Ivy tasks… you should then run Ivy as any external program.
Calling Ivy from Ant: first steps
Once your build file is ok to call Ivy tasks, the simplest way to use Ivy is to call the Ivy retrieve task with no parameters:
<ivy:retrieve/>This calls Ivy with default values, which might be ok in several projects. In fact, it is equivalent to:
<target name="resolve">
<ivy:configure/>
<ivy:resolve file="${ivy.dep.file}" conf="${ivy.configurations}"/>
<ivy:retrieve pattern="${ivy.retrieve.pattern}" conf="${ivy.configurations}"/>
</target>Those 3 tasks follow the 3 main steps of the Ivy retrieving dependencies process:
-
First the configure task tells it how it can find dependencies giving it a path to a settings XML file.
-
Then the resolve task actually resolves dependencies described by an Ivy file, and puts those dependencies in the Ivy cache (a directory configured in the settings file).
-
Finally the retrieve task copies dependencies from the cache to anywhere you want in your file system. You can then use those dependencies to make your classpath with standard Ant paths.
To understand more accurately the behaviour of Ivy tasks, one should know that a property file is loaded in Ant by Ivy at the beginning of the configure call. This property file contains the following properties:
ivy.project.dir = ${basedir}
ivy.lib.dir = ${ivy.project.dir}/lib
ivy.build.artifacts.dir = ${ivy.project.dir}/build/artifacts
ivy.distrib.dir = ${ivy.project.dir}/distrib
ivy.resolver.default.check.modified = false
ivy.default.always.check.exact.revision = true
ivy.configurations = *
ivy.resolve.default.type.filter = *
ivy.status = integration
ivy.dep.file = ivy.xml
ivy.settings.file = ivysettings.xml
ivy.retrieve.pattern = ${ivy.lib.dir}/[artifact]-[revision].[ext]
ivy.deliver.ivy.pattern = ${ivy.distrib.dir}/[type]s/[artifact]-[revision].[ext]
ivy.publish.src.artifacts.pattern = ${ivy.distrib.dir}/[type]s/[artifact]-[revision].[ext]
ivy.report.output.pattern = [organisation]-[module]-[conf].[ext]
ivy.buildlist.ivyfilepath = ivy.xml
ivy.checksums=sha1,md5For the latest version of these properties, you can check the Git version.
(since 2.0) After calling the first Ivy task, the property ivy.version will be available and contains the version of the used Ivy library.
Ivy tasks attributes : generalities
Some tasks attributes values may be set in different places. The three possible places are :
-
task attribute
-
Ivy instance
-
project property
The places are queried in this order, so anything set in task attribute will override what would have been found in Ivy instance, for example.
The Ivy instance considered here is an instance of the class Ivy, which is set up by a call to the configure task, and then reused for other tasks. Because most of the tasks need an Ivy instance, they first check if one is available (i.e. configure has been called), and if none is available, then a default configure is called and the resulting Ivy instance is used in the remaining tasks (unless another configure is called).
It isn’t generally necessary to understand this, but it can lead to some issues if you forget to call configure before another task and if the configure step was required in your environment.
Usual cycle of main tasks
Example
Here is a more complete example of build file using Ivy:
<project xmlns:ivy="antlib:org.apache.ivy.ant" name="sample" default="resolve">
<target name="resolve">
<ivy:configure file="../ivysettings.xml"/>
<ivy:resolve file="my-ivy.xml" conf="default, myconf"/>
</target>
<target name="retrieve-default" depends="resolve">
<ivy:retrieve pattern="lib/default/[artifact]-[revision].[ext]" conf="default"/>
</target>
<target name="retrieve-myconf" depends="resolve">
<ivy:retrieve pattern="lib/myconf/[artifact]-[revision].[ext]" conf="myconf"/>
</target>
<target name="retrieve-all" depends="resolve">
<ivy:retrieve pattern="lib/[conf]/[artifact]-[revision].[ext]" conf="*"/>
</target>
<target name="deliver" depends="retrieve-all">
<ivy:deliver deliverpattern="distrib/[artifact]-[revision].[ext]"
pubrevision="1.1b4" pubdate="20050115123254" status="milestone"/>
</target>
<target name="publish" depends="deliver">
<ivy:publish resolver="internal"
artifactspattern="distrib/[artifact]-[revision].[ext]"
pubrevision="1.1b4"/>
</target>
</project>All Ivy tasks are documented in the following pages.
artifactproperty
[since 1.1]
Sets an Ant property for each dependency artifact previously resolved.
(since 2.0) This is a post resolve task, with all the behaviour and attributes common to all post resolve tasks.
Please prefer the use of retrieve + standard Ant path creation, which make your build more independent from Ivy (once artifacts are properly retrieved, Ivy is not required any more).
The property name and value are generated using the classical pattern concept, all artifact tokens and Ivy variables being available.
(since 2.0) This tag will follow the Ant usual behavior for properties. If a property with the same name already exists, its value will be unchanged. This behavior can be changed using the overwrite attribute.
WARNING: Before 2.0, the behavior was to overwrite the properties. Since 2.0, the default is to not overwrite to properties
Attributes
| Attribute | Description | Required |
|---|---|---|
name |
a pattern used to generate the name of the properties to set |
Yes |
value |
a pattern used to generate the value of the properties to set |
Yes |
conf |
a comma separated list of the configurations for which properties should be set |
No. Defaults to the configurations resolved by the last resolve call, or |
haltonfailure |
|
No. Defaults to |
validate |
|
No. Defaults to default Ivy value (as configured in settings file) |
settingsRef |
A reference to Ivy settings that must be used by this task (since 2.0) |
No, |
overwrite |
Overwrite the value of the property if it already exists (since 2.0). Before 2.0, the properties were always overwritten. |
No, |
Example
Suppose we have one dependency called mydep in revision 1.0 publishing two artifacts: foo.jar and bar.jar.
Then:
<artifactproperty conf="build"
name="[module].[artifact]-[revision]"
value="${cache.dir}/[module]/[artifact]-[revision].[ext]"/>will set two properties:
mydep.foo-1.0 = my/cache/dir/mydep/foo-1.0.jar
mydep.bar-1.0 = my/cache/dir/mydep/bar-1.0.jarartifactreport
[since 1.4]
The artifactreport task generates an XML report of all artifact dependencies resolved by the last resolve task call during the same build.
(since 2.0) This is a post resolve task, with all the behaviour and attributes common to all post resolve tasks.
This report is different from the standard report which reports all modules and artifacts, while this report is much simpler and focuses only on artifacts, and gives more information on artifacts, such as the original location and the retrieve location.
It is thus easy to use to generate things like a classpath file for an IDE.
See this article by Johan Stuyts (who contributed this task) to see how he uses this task.
Here is an example of generated file:
<?xml version="1.0" encoding="UTF-8"?>
<modules>
<module organisation="hippo" name="sant-classes" rev="1.01.00b04-dev" status="integration">
<artifact name="sant-classes-src" ext="zip" type="zip">
<origin-location is-local="true">
C:/home/jstuyts/data/ivy/local/hippo/sant-classes/1.01.00b04-dev/sant-classes-src-1.01.00b04-dev.zip</origin-location>
<cache-location>
C:/home/jstuyts/data/ivy/cache/hippo/sant-classes/zips/sant-classes-src-1.01.00b04-dev.zip</cache-location>
<retrieve-location>lib/test/sant-classes-src-1.01.00b04-dev.zip</retrieve-location>
</artifact>
<artifact name="sant-classes-unoptimized" ext="jar" type="jar">
<origin-location is-local="true">
C:/home/jstuyts/data/ivy/local/hippo/sant-classes/1.01.00b04-dev/sant-classes-unoptimized-1.01.00b04-dev.jar</origin-location>
<cache-location>
C:/home/jstuyts/data/ivy/cache/hippo/sant-classes/jars/sant-classes-unoptimized-1.01.00b04-dev.jar</cache-location>
<retrieve-location>lib/test/sant-classes-unoptimized-1.01.00b04-dev.jar</retrieve-location>
</artifact>
</module>
<module organisation="testng" name="testng" rev="4.6.1-jdk15" status="release">
<artifact name="testng" ext="jar" type="jar">
<origin-location is-local="false">
http://repository.hippocms.org/maven/testng/jars/testng-4.6.1-jdk15.jar</origin-location>
<cache-location>C:/home/jstuyts/data/ivy/cache/testng/testng/jars/testng-4.6.1-jdk15.jar</cache-location>
<retrieve-location>lib/test/testng-4.6.1-jdk15.jar</retrieve-location>
</artifact>
</module>Attributes
| Attribute | Description | Required |
|---|---|---|
tofile |
the file to which the report should be written |
Yes |
pattern |
the retrieve pattern to use for adding the retrieve location information about the artifacts |
No. Defaults to |
conf |
a comma separated list of the configurations to use to generate the report |
No. Defaults to the configurations resolved by the last resolve call |
haltonfailure |
|
No. Defaults to |
settingsRef |
A reference to Ivy settings that must be used by this task (since 2.0) |
No, |
Examples
<ivy:artifactreport tofile="${basedir}/path/to/myreport.xml"/>Generates the artifact report for all configurations resolved during the last resolve call (in the same build).
<ivy:artifactreport tofile="${basedir}/path/to/myreport.xml" conf="default"/>Generates the artifact report for only the default configuration resolved during the last resolve call.
buildlist
[since 1.2]
The buildlist task enables to obtain a filelist of files (usually build.xml files) ordered according to Ivy dependency information from the least dependent to the most one, or the inverse.
This is particularly useful combined with subant, to build a set of interrelated projects being sure that a dependency will be built before any module depending on it.
When the ivy.xml of the modules that you want to order doesn’t contain revision numbers, the rev attributes declared in the dependencies are not used.
When the ivy.xml of the modules that you want to order contains revision numbers, the revision numbers are used. If the revision number doesn’t match a dependency description, a warning is logged and the modules are considered to be different modules.
(since 1.3) A root attribute can also be used to include, among all the modules found, only the ones that are dependencies (either direct or transitive) of a root module. This can also be used with the excluderoot attribute, which when set to true will exclude the root itself from the list.
(since 1.4.1) A leaf attribute can also be used to include, among all the modules found, only the ones that have dependencies (either direct or transitive) on a leaf module. This can also be used with the excludeleaf attribute, which when set to true will exclude the leaf itself from the list.
(since 1.4) The ivy.sorted.modules property is set in Ant project at the end of the task with a comma separated list of ordered modules. This can be useful for debug or information purpose.
(since 2.0) The root and leaf attributes can be a delimited list of modules to use as roots. These modules, and all their dependencies will be included in the build list.
(since 2.5) The root and leaf modules can also be specified as nested root and leaf elements. This way, not only the module name can be specified, but also the organisation, revision and branch of the root/leaf.
By default, all the modules included in a circular dependency are grouped together so that any dependency of any module in the loop will appear before the modules in the loop. This guarantees that if there is a dependency path between a module A and a module B (but no dependency path from B to A), B will always appear before A even if A is included in a loop in the provided set of modules to sort.
Note that a circular dependency can also trigger a failure depending on the value configured in the circularDependencyStrategy of your settings
When you are specifying root or leaf modules you can limit the resulting list to only direct dependencies of the root modules or to modules that directly depends on your leaf modules.
You can also specify a restartFrom modules. The difference with root or leaf is that you get a list starting at the restartFrom module followed by all the modules that would be after if the parameter would not be there (even if there is no dependency between the restartFrom and the following module).
Attributes
| Attribute | Description | Required |
|---|---|---|
reference |
the reference of the path to set |
Yes |
ivyfilepath |
the relative path from files to order to corresponding Ivy files |
No. Defaults to |
root |
(since 2.0) the names of the modules which should be considered as the root of the buildlist. (since 1.3) Was limited to only one module name before 2.0. |
No. Defaults to no root (all modules are used in the build list) |
excluderoot |
(since 1.3) |
No. Defaults to |
leaf |
(since 2.0) the names of the modules which should be considered as the leaf of the buildlist. (since 1.4.1) Was limited to only one module name before 2.0. |
No. Defaults to no leaf (all modules are used in the build list) |
onlydirectdep |
(since 2.0) This field is ignored when neither root nor leaf is filled. |
No. Defaults to no |
delimiter |
(since 2.0) delimiter to use when specifying multiple module names in the root and leaf properties. |
No. Defaults to the comma ( |
excludeleaf |
(since 1.4.1) |
No. Defaults to |
haltonerror |
|
No. Defaults to |
skipbuildwithoutivy |
Deprecated, use |
No. Defaults to |
onMissingDescriptor |
(since 2.0) Specify the action to take when no module descriptor file is found for a file of the fileset. Possible values are: |
No. Defaults to |
reverse |
|
No. Defaults to default |
restartFrom |
(since 2.0) The name of the module which should be considered as the starting point in the buildlist. This allows for the build to be started at any point in the dependency chain. |
No. Defaults to |
settingsRef |
(since 2.0) A reference to Ivy settings that must be used by this task |
No, |
Child elements
| Element | Description | Cardinality |
|---|---|---|
root |
(since 2.5) Declares a root module. This element takes the following attributes: |
0..n |
leaf |
(since 2.5) Declares a leaf module. This element takes the following attributes: |
0..n |
Parameters specified as nested elements
fileset
FileSets are used to select sets of files to order.
Examples
<ivy:buildlist reference="build-path">
<fileset dir="projects" includes="**/build.xml"/>
</ivy:buildlist>Builds a list of build.xml files sorted according to the ivy.xml files found at the same level (the default value for ivyfilepath is ivy.xml).
This list can then be used like that:
<subant target="build" buildpathref="build-path"/> <ivy:buildlist reference="build-path" ivyfilepath="ivy/ivy.xml" reverse="true">
<fileset dir="projects" includes="**/build.xml"/>
</ivy:buildlist>Builds a list of build.xml files sorted according to the ivy.xml files found in an Ivy directory relative to those build files. The list is sorted from the most dependent to the least one.
<ivy:buildlist reference="build-path" ivyfilepath="ivy/ivy.xml" root="myapp">
<fileset dir="projects" includes="**/build.xml"/>
</ivy:buildlist>Builds a list of build.xml files sorted according to the ivy.xml files found in an Ivy directory relative to those build files. Only build.xml files of modules which are dependencies of myapp (either direct or transitive) are put in the result list.
<ivy:buildlist reference="build-path" ivyfilepath="ivy/ivy.xml" leaf="mymodule">
<fileset dir="projects" includes="**/build.xml"/>
</ivy:buildlist>Builds a list of build.xml files sorted according to the ivy.xml files found in an Ivy directory relative to those build files. Only build.xml files of modules which have dependencies (direct or transitive) on mymodule are put in the result list.
<ivy:buildlist reference="build-path" ivyfilepath="ivy/ivy.xml">
<root organisation="myorg" module="myapp" />
<fileset dir="projects" includes="**/build.xml"/>
</ivy:buildlist>Builds a list of build.xml files sorted according to the ivy.xml files found in an Ivy directory relative to those build files. Only build.xml files of modules which are dependencies of myorg#myapp (either direct or transitive) are put in the result list.
<ivy:buildlist reference="build-path" ivyfilepath="ivy/ivy.xml">
<root file="/path/to/myapp-ivy.xml" />
<fileset dir="projects" includes="**/build.xml"/>
</ivy:buildlist>Builds a list of build.xml files sorted according to the ivy.xml files found in an Ivy directory relative to those build files. Only build.xml files of modules which are dependencies defined in /path/to/myapp-ivy.xml (either direct or transitive) are put in the result list.
buildnumber
[since 1.4]
The buildnumber task is similar to the Ant buildnumber task, except that it uses Ivy repository to find what is the latest version and calculate a new one for you.
When called, it sets four properties according to what has been found. These properties are:
-
ivy.revision: the last revision found in the repository -
ivy.new.revision: the new revision calculated from the last one (see below) -
ivy.build.number: the build number found in the repository -
ivy.new.build.number: the new build number calculated from the last one, usually with +1
Build numbers are always numbers (composed of digit characters only).
ivy.revision can be not set if no revision was found.
ivy.build.number can be not set if no revision was found or if no number was found in it.
ivy.new.build.number can be not set if the default new revision to use when no revision is found does not contain some number.
The new revision is calculated using a somewhat complex to explain but very easy to use algorithm, depending on which latest version you asked.
Indeed you can ask for a new revision based upon the latest found for a particular prefix (the revision asked), then the new revision will be the one immediately after with only the prefix in common. If no prefix is set the very latest version is searched.
Examples (suppose the latest version of the module is 1.3.1):
| revision asked | ivy.revision | ivy.new.revision | ivy.build.number | ivy.new.build.number |
|---|---|---|---|---|
1.3 |
1.3.1 |
1.3.2 |
1 |
2 |
1 |
1.3.1 |
1.4 |
3 |
4 |
2 |
not set |
2.0 |
not set |
0 |
1.3.1 |
1.3.2 |
1 |
2 |
Note that when asking for revision 1, you can get a revision 10.0. To avoid that you can use 1. as revision asked, but in this case Ivy won’t find revision 1 if its the latest one, and it will thus give 1.0 as new revision. The solution to this problem is to use versions with always the same number of parts (for instance, 1.0.0 instead of 1).
Attributes
| Attribute | Description | Required |
|---|---|---|
organisation |
the organisation of the module for which a new build number should be calculated |
Yes |
module |
the name of the module for which a new build number should be calculated |
Yes |
branch |
the branch of the module for which a new build number should be calculated |
No, defaults to the default branch for this module |
revision |
the revision prefix for which a new build number should be calculated |
No, defaults to no prefix (will find the latest version) |
default |
the default revision to assume when no revision prefix is asked and no revision is found |
No, defaults to 0 |
defaultBuildNumber |
the default build number to use for the first revision |
No, defaults to 0 |
revSep |
the revision separator to use when no matching revision is found, to separate the revision prefix from the build number |
No, defaults to |
prefix |
the prefix to use for the property names set (will be |
No, defaults to |
settingsRef |
A reference to Ivy settings that must be used by this task (since 2.0). |
No, |
resolver |
the name of the resolver to use for build number calculation (since 2.1) |
No, all available resolvers will be used by default. |
Examples
Here is how it can be used (suppose 1.3.1 is the latest version of Ivy in the repository):
<ivy:buildnumber organisation="apache" module="ivy"/>will set 1.3.1 as revision, 1.3.2 as new revision, 1 as build number and 2 as new build number
<ivy:buildnumber organisation="apache" module="ivy" revision="1.3"/>will set 1.3.1 as revision, 1.3.2 as new revision, 1 as build number and 2 as new build number
<ivy:buildnumber organisation="apache" module="ivy" revision="1.2"/>will set 1.2 as revision, 1.2.1 as new revision, no build number and 1 as new build number
<ivy:buildnumber organisation="apache" module="ivy" revision="1."/>will set 1.3.1 as revision, 1.4 as new revision, 3 as build number and 4 as new build number
<ivy:buildnumber organisation="apache" module="ivy" revision="3."/>will set no revision, 3.0 as new revision, no build number and 0 as new build number
<ivy:buildnumber organisation="apache" module="ivy" revision="1.4-RC" defaultBuildNumber="1" revSep=""/>If called while no release candidate is in the repository, will set ivy.revision to 1.4-RC1. Then it will increment each time, 1.4-RC2, 1.4-RC3, and so on.
buildobr
[since 2.3]
From a set of jar artifacts, this task generates an OBR (OSGi Bundle Repository) descriptor. It could be then used by the obr resolver.
The set of jars which will be described by OBR can be defined in 4 mutually exclusive ways:
-
via an Ivy resolver: every jar listed by the resolver will be taken into account
-
by defining a root directory: every jar found recursively in that folder will be taken into account
-
via the name of an Ivy cache: every artifact contained in the cache will be taken into account
-
(since 2.4) via a resolve: this task is a post resolve task (with all the behaviour and attributes common to all post resolve tasks), thus every artifact which has been resolved will be taken into account; it is especially useful for building a target platform
NB: among every listed file or artifact, only the actually OSGi bundles will be described by the OBR descriptor; the other files are ignored.
Attributes
[since 2.4]
This is a post resolve task, with all the behaviour and attributes common to all post resolve tasks.
| Attribute | Description | Required |
|---|---|---|
out |
the location of the descriptor file to generate |
Yes |
resolverName |
the name of the resolver from which the jars should be to gathered |
No |
cacheName |
the name of the cache from which the jars should be to gathered |
No |
baseDir |
the folder into which the jars should be gathered recursively |
No |
sourceType |
if used as a post resolve task, |
No. Defaults to |
encoding |
The encoding of the resulting XML file |
No. Defaults to |
indent |
Specify if the XML result file should be indented |
No. Defaults to |
quiet |
Log the rejected jars that are ill-formed as debug rather than warning |
No. Defaults to |
Examples
<ivy:buildobr baseDir="${eclipse.home}" out="${basedir}/target/repo-eclipse.xml" indent="true"/>Builds an indented OBR descriptor from an Eclipse install, with their path relative to the Eclipse install.
<ivy:configure file="ivysettings.xml"/>
<ivy:buildobr resolverName="my-file-resolver" out="${basedir}/target/repo-eclipse.xml"/>Configures Ivy settings and builds an OBR descriptor from jars resolved by the defined resolver.
<ivy:configure file="ivysettings.xml"/>
<ivy:buildobr cacheName="my-cache" out="${basedir}/target/repo-eclipse.xml"/>Configures Ivy settings and builds an OBR descriptor from jars contained in the defined cache.
<ivy:configure file="ivysettings.xml"/>
<ivy:resolve file="ivy.xml"/>
<ivy:buildobr out="${basedir}/target-platform-obr.xml"/>Launches a resolve and then builds an obr.xml describing the resolved artifacts.
cachefileset
[since 1.2]
Constructs an Ant fileset consisting of artifacts in Ivy’s cache for a configuration.
This is a post resolve task, with all the behaviour and attributes common to all post resolve tasks. Note that this task does not rely on retrieve, because the built fileset is made of artifacts directly in Ivy’s cache.
Please prefer the use of retrieve + standard Ant path creation, which make your build more independent from Ivy (once artifacts are properly retrieved, Ivy is not required any more).
Built fileset is registered in Ant project with a given id, and can thus be used like any other Ant fileset using
refid.
Limitation
A fileset, in Ant project, requires a base directory from within which the files are included/excluded. The cachefileset task, in Ivy, internally tries to determine a common base directory across all the resolved artifact files that have been downloaded in the Ivy repository cache(s). Given that Ivy can be configured to use multiple repository caches and each one can potentially be on a different filesystem root, there are times, when cachefileset cannot determine a common base directory for these resolved artifacts. The cachefileset throws an exception in such cases.
Alternative task
If cachefileset doesn’t fit the need of your use case (maybe due to the limitations noted above), the resources task could be an alternative task to use in certain cases.
Attributes
| Attribute | Description | Required |
|---|---|---|
setid |
the id to reference the built fileset |
Yes |
conf |
a comma separated list of the configurations to put in the created path |
No. Defaults to the configurations resolved by the last resolve call, or |
type |
comma separated list of artifact types to accept in the path, |
No. Defaults to |
settingsRef |
(since 2.0) A reference to Ivy settings that must be used by this task |
No, |
cachepath
Constructs an Ant path consisting of artifacts in Ivy’s cache (or origin location with depending on useOrigin setting) for a resolved module configuration.
This is a post resolve task, with all the behaviour and attributes common to all post resolve tasks.
If you want to make your build more independent from Ivy, you could consider using the retrieve task. Once the artifacts are properly retrieved, you can use standard Ant path creation which makes Ivy not necessary any more.
Built path is registered in the Ant project with a given id, and can thus be used like any other Ant path using refid.
Attributes
| Attribute | Description | Required |
|---|---|---|
pathid |
the id to reference the built path |
Yes |
conf |
a comma separated list of the configurations to put in the created path |
No. Defaults to the configurations resolved by the last resolve call, or |
type |
comma separated list of artifact types to accept in the path, |
No. Defaults to |
settingsRef |
(since 2.0) A reference to Ivy settings that must be used by this task |
No, |
Examples
<cachepath pathid="default.classpath" conf="default"/>Construct an Ant path composed of all artifacts being part of the default configuration obtained through the last resolve call.
<cachepath pathid="default.classpath" conf="default" useOrigin="true"/>Same as before but will use the original location for local artifacts, and the cache location for other artifacts.
<ivy:cachepath organisation="emma" module="emma" revision="2.0.4217" inline="true" conf="ant" pathid="emma.classpath"/>
<taskdef resource="emma_ant.properties" classpathref="emma.classpath"/>Resolves the Emma module in version 2.0.4217, constructs an Ant path with the corresponding artifacts, and then defines the Emma tasks using this path.
checkdepsupdate
Display dependency updates on the console. This task can also show transitive dependencies updates and detect missing or new dependencies if you update dependencies.
This is a post resolve task, with all the behaviour and attributes common to all post resolve tasks.
Please prefer the use of retrieve + standard Ant path creation, which make your build more independent from Ivy (once artifacts are properly retrieved, Ivy is not required any more).
Attributes
| Attribute | Description | Required |
|---|---|---|
revisionToCheck |
target revision to check |
No. Defaults to |
download |
specify if artifact should be downloaded when new updates are found |
No. Defaults to |
checkIfChanged |
When set to |
No, default to |
showTransitive |
set to |
No. Defaults to |
Example
Suppose we have two dependencies one called mydep in revision 1.0 and one called myotherdependency in revision 2.0. mydep has a transitive dependency on mytransitivedependency in revision 2.2.
Then:
<checkdepsupdate/>will display the following updates in the console:
Dependencies updates available :
mycompany#mydep 1.0 -> 2.0
mycompany#myotherdependency 2.0 -> 2.2Same example with transitive dependencies :
<checkdepsupdate showTransitive="true"/>will display the following updates in the console:
Dependencies updates available :
mycompany#mydep 1.0 -> 2.0
mycompany#myotherdependency 2.0 -> 2.2
mycompany##mytransitivedependency (transitive) 2.2 -> 2.4cleancache
[since 2.0]
Cleans the Ivy cache.
This task is roughly equivalent to:
<delete dir="${ivy.cache.dir}"/>Using the regular Ant delete task is more flexible, since it allows to specify the files to delete. But it requires Ivy settings to be loaded, and settings scoping is possible only by using a suffixed Ant property for the cache directory.
This task loads the Ivy settings as any other post settings task, and allows easy scoping with the attribute settingsRef.
Attributes
| Attribute | Description | Required |
|---|---|---|
settingsRef |
A reference to Ivy settings that must be used by this task |
No. Defaults to |
Examples
<ivy:cleancache/>Cleans the cache directory as defined in the loaded settings (by default ~/.ivy2/cache)
<ivy:cleancache settingsRef="mysettings"/>Cleans the cache directory as defined in the loaded settings identified as mysettings
configure
The configure task is used to configure Ivy with a settings XML file.
See Settings Files for details about the settings file itself.
[since 2.0]
The file loaded used to be called configuration file in versions prior to 2.0. The name settings and the use of the ivy.settings.file is new to 2.0.
It is also possible to configure Ivy with the settings declaration. The difference with this task is that when using the settings declaration, the configuration of Ivy will be done when the settings are first needed (for instance, when you do a resolve), while the configure task will perform a configuration of Ivy instantly, which makes it easier to see the problem if something goes wrong.
Attributes
| Attribute | Description | Required |
|---|---|---|
settingsId |
The settings id usable in the |
No, defaults to |
file |
path to the settings file to use |
No. If a file is provided, URL is ignored. If none are provided, then it attempts to find a file at |
url |
URL of the settings file to use |
|
override |
Specify what to do when another settings with the same id has already been loaded. |
No, defaults to |
host |
HTTP authentication host |
No, unless authentication is required |
realm |
HTTP authentication realm |
|
username |
HTTP authentication user name |
|
passwd |
HTTP authentication password |
HTTP Authentication
If any of the URLs you use in Ivy (especially in dependency resolvers) needs HTTP authentication, then you have to provide the host, realm, username and passwd attributes of the configure task. These settings will then be used in any further call to Ivy tasks.
(since 1.4) It’s also possible to configure authentication settings for multiple URLs. This can be done with the <credentials> subelements. See the examples for more details.
Examples
Simplest settings
<ivy:configure/>Use either ${ivy.settings.file} if it exists, or the default settings file
Configure with a file
<ivy:configure file="myconffile.xml"/>Configure with an URL
<ivy:configure url="http://mysite.com/myconffile.xml"/>Configure multiple URLs which require authentication
<ivy:configure file="path/to/my/ivysettings.xml">
<credentials host="myhost.com" realm="My Realm" username="myuser" passwd="mypasswd"/>
<credentials host="yourhost.com" realm="Your Realm" username="myuser" passwd="myotherpasswd"/>
</ivy:configure>Attributes
| Attribute | Description | Required |
|---|---|---|
manifest |
the location of the |
Yes |
ivyFile |
the location of the |
Yes |
Examples
<ivy:convertmanifest manifest="META-INF/MANIFEST.MF" ivyFile="ivy.xml"/>Just converts a manifest into an ivy.xml file.
Attributes
| Attribute | Description | Required |
|---|---|---|
pomFile |
the location of the |
Yes |
ivyFile |
the location of the |
Yes |
Examples
<ivy:convertpom pomFile="pom.xml" ivyFile="ivy.xml"/>Just convert a pom.xml file into an ivy.xml.
deliver
Deliver a resolved descriptor of the current module, and possibly perform a recursive delivery of dependencies.
This task does two main things:
Generate a resolved Ivy file
This task generates a resolved descriptor of the current module, based upon the last resolve done. The resolved Ivy file contains updated information about the delivered module, such as revision and status.
Moreover, all included configurations' files are included in the Ivy file, and variables are replaced by their values.
Finally, in the resolved Ivy file, dynamic revisions are replaced by the static ones that have been found during the resolve step, so the Ivy file can be used later safely to obtain the same dependencies (providing that a revision uniquely identifies a module, which should be the case for proper Ivy use).
(since 1.3) The replacement of dynamic revisions by static ones can be turned off, so that dynamic revisions are kept in the Ivy file. This is an exception to the recommended standard that published module descriptors be fully resolved, so use it with caution.
Recursive delivery
This is done only if a deliver target is given to the deliver task.
If a deliver target is set, then it is called (via an antcall) for each dependency which has not a sufficient status compared to the deliver status set for this task. This means that if you deliver an integration revision, no recursive delivery will be done.
If you deliver a milestone or a release revision, deliver target will be called with each integration dependency.
The deliver target is called with the following properties available:
-
dependency.name: the name of the dependency to recursively deliver -
dependency.published.status: the status to which the dependency should be delivered -
dependency.published.version: the revision to which the dependency should be delivered -
dependency.version: the revision of the dependency that should be delivered (the one that was retrieved during last resolve)
Both dependency.published.status and dependency.published.version can be either asked to the user through Ant input tasks (default behaviour), or be always the same for the whole recursive delivery process if the following properties are set:
-
recursive.delivery.status: set to the status to which all dependencies requiring to be delivered will be -
recursive.delivery.version: set to the version to which all dependencies requiring to be delivered will be
Usually the deliver target itself triggers an another Ant build (using the ant task) even if this is up to you to decide.
The delivered Ivy file will update its dependency revisions with those given here.
deliver and publish
The deliver task is most of the time not called explicitly, but rather called automatically by the publish task. So, when shall the deliver task be called explicitly? When you actually need to separate what is performed by the deliver task (see above), from what is performed by the publish task, i.e. upload a module to a repository.
And this can be particularly useful if you want to process the generated Ivy file before uploading it (if you want to add automatically more information like an SCM tag used, the user who performed the release, …).
It can also be useful if you want to trigger a recursive delivery and then ensure that you get the recursively delivered modules as dependencies. In this case your build order may look like this:
-
ivy:configure -
ivy:resolve -
ivy:deliverwith recursive delivery -
ivy:resolveagain with the Ivy file generated by the recursive delivery -
do your build stuff (compile, jar, whatever)
-
ivy:publish
Attributes
| Attribute | Description | Required |
|---|---|---|
deliverpattern |
the pattern to use for Ivy file delivery |
No. Defaults to |
pubrevision |
the revision to use for the publication |
No. Defaults to |
pubbranch |
the branch to use for the publication |
No. Defaults to |
pubdate |
the publication date to use for the publication. This date should be either |
No. Defaults to |
status |
the status to use for the publication |
No. Defaults to |
delivertarget |
the target to call for recursive delivery |
No. No recursive delivery is done by default |
validate |
|
No. Defaults to default Ivy value (as configured in settings) |
replacedynamicrev |
|
No. Defaults to |
replaceForcedRev |
|
No. Defaults to |
merge |
if a descriptor extends a parent, merge the inherited information directly into the delivered descriptor. The |
No. Defaults to |
settingsRef |
A reference to Ivy settings that must be used by this task (since 2.0) |
No. Defaults to |
conf |
comma-separated list of configurations to include in the delivered file. Accepts wildcards. (since 2.0) |
No. Defaults to all configurations |
generateRevConstraint |
|
No. Defaults to |
Example
Deliver an Ivy file without the private configurations:
<deliver conf="*(public)"/>dependencytree
Display a dependency tree on the console.
This is a post resolve task, with all the behaviour and attributes common to all post resolve tasks.
Please prefer the use of retrieve + standard Ant path creation, which make your build more independent from Ivy (once artifacts are properly retrieved, Ivy is not required any more).
Attributes
| Attribute | Description | Required |
|---|---|---|
showEvicted |
specify if evicted modules should be printed |
No. Defaults to |
conf |
a comma separated list of the configurations to take in consideration in the dependency tree |
No. Defaults to the configurations resolved by the last resolve call, or |
haltonfailure |
|
No. Defaults to |
validate |
true to force Ivy files validation against ivy.xsd, false to force no validation |
No. Defaults to default Ivy value (as configured in settings) |
settingsRef |
A reference to Ivy settings that must be used by this task (since 2.0) |
No, defaults to |
overwrite |
Overwrite the value of the property if it already exist (since 2.0). Before 2.0, the properties were always overwritten. |
No, |
Example
Suppose we have two dependencies one called mydep in revision 2.0 and one called myotherdependency in revision 2.2. mydep has a transitive dependency on mytransitivedependency in revision 2.2.
Then:
<dependencytree/>will display the following tree in the console:
Dependency tree for foobar
+- org#mydep;2.0
\- org#mytransitivedependency;2.2
\- org#myotherdependency;2.2");findrevision
[since 1.4]
Finds the latest revision of a module matching a given version constraint.
A version constraint is what is used when declaring a dependency on a module. If the module is not found, the property is not set.
Attributes
| Attribute | Description | Required |
|---|---|---|
organisation |
the organisation of the module to find |
Yes |
module |
the name of the module to find |
Yes |
branch |
the branch of the module to find |
No, defaults to the default branch for the given module |
revision |
the revision constraint to apply |
Yes |
property |
the property to set with the found revision |
No, defaults to |
settingsRef |
a reference to Ivy settings that must be used by this task (since 2.0) |
No, defaults to |
Examples
<ivy:findrevision organisation="apache" module="ivy" revision="latest.integration"/>finds the latest version of Ivy available in the repository and sets the property ivy.revision according to what was found.
<ivy:findrevision organisation="apache" module="ivy" revision="1.0+"/>same as above but only with 1.0 sub versions.
fixdeps
[since 2.4]
The fixdeps task serializes transitively resolved dependencies into an ivy.xml file.
The dependencies declared in an ivy.xml can be specified as range of revisions. And the transitive dependencies too. As new versions of modules can be added to the repository anytime, resolved versions of ranges can change over time. It is then safer to resolve a range once and stick with the resolved revision. This way a resolve process is highly reproducible.
It is especially useful in a very dynamic environment like the OSGi one.
In a multi project environment some dependencies still need to be maintained loose: the ones between the projects. These dependencies, as soon as they are declared in the original ivy.xml, can be kept from being fixed. In order to do so, use the inner element keep.
The recommended setup is then to:
-
have an
ivy-spec.xmlin your project which specifies the dependencies, with ranges if needed -
have an Ant target which resolves the
ivy-spec.xmland callfixdepsto generate anivy.xml. This target should then only be called afterivy-spec.xmlis modified. The generatedivy.xmlcan safely be shared in a version control repository (Git, Subversion, …). -
make the entire build workflow based on the resolve of the generated
ivy.xml
This is a post resolve task, with all the behaviour and attributes common to all post resolve tasks.
Attributes
| Attribute | Description | Required |
|---|---|---|
tofile |
The location of the Ivy file to generate |
Yes |
Child elements
| Element | Description | Cardinality |
|---|---|---|
keep |
declares a dependency to keep from being fixed, and keep its original declaration from the original ivy.xml These elements takes two attributes: |
0..n |
Examples
<ivy:fixdeps tofile="ivy-fixed.xml"/>Simple fix of some dependencies.
<ivy:fixdeps tofile="ivy-fixed.xml">
<keep org="com.acme" module="mymodule"/>
</ivy:fixdeps>Fix of the dependencies but keep the dependency on com.acme#mymodule as defined in the original ivy.xml.
info
[since 1.4]
The info task eases the access to some essential data contained in an Ivy file without performing a dependency resolution.
The information is retrieved by setting Ant properties:
| Property | Description |
|---|---|
ivy.organisation |
The organisation of the module, as found in the info tag of the Ivy file parsed. |
ivy.module |
The name of the module, as found in the info tag of the Ivy file parsed. |
ivy.branch |
The branch of the module if any, as found in the info tag of the Ivy file parsed. |
ivy.revision |
The revision of the module, as found in the info tag of the Ivy file parsed. |
ivy.status |
The status of the module, as found in the info tag of the Ivy file parsed. |
ivy.publication |
The publication time of the module, as found in the info tag of the Ivy file parsed. (since 2.2) |
ivy.extra.[any extra attribute] |
Corresponding extra attribute value, as found in the info tag of the Ivy file parsed |
ivy.configurations |
A comma separated list of configurations of the module, as declared in the configurations section |
ivy.public.configurations |
A comma separated list of public configurations of the module, as declared in the configurations section |
ivy.configuration.[config name].desc |
For each configuration with a description, a property is created containing this description. (since 2.2) |
ivy.artifact.[index].name |
For each published artifact, a property is created containing its name. (since 2.2) |
ivy.artifact.[index].type |
For each published artifact, a property is created containing its type. (since 2.2) |
ivy.artifact.[index].ext |
For each published artifact, a property is created containing its ext. (since 2.2) |
ivy.artifact.[index].conf |
For each published artifact, a property is created containing its conf. (since 2.2) |
ivy.artifact.[index].extra.[any extra attribute] |
For each extra attribute of the published artifact, a property is created containing its name. (since 2.2) |
[since 2.0]
This task has been enhanced to allow you to retrieve information about Ivy modules in a repository. Instead of specifying a local Ivy file you may specify the organisation, module, revision pattern and (optionally) the branch of the Ivy module in the repository you wish to retrieve the information for.
The revision pattern is what is used when declaring a dependency on a module, identical to how the findrevision task works. In fact, this task can now be used in place of the findrevision task.
If no matching module is found then no property values are set.
You may now also set the property attribute to change the first part of the property names that are set by this task e.g. if you set the property attribute to mymodule this task will set the Ant properties mymodule.organisation, mymodule.module, mymodule.revision etc.
(since 2.2) This task has been enhanced to also retrieve detailed information about the module’s published artifacts, as well as the publication time.
Attributes
| Attribute | Description | Required |
|---|---|---|
file |
the Ivy file to parse |
Yes, if you wish to parse an Ivy file. No, if you are retrieving information about a module from an Ivy repository. |
organisation |
the organisation of the module to find (since 2.0) |
No, if you wish to parse an Ivy file. Yes, if you are retrieving information about a module from an Ivy repository. |
module |
the the name of the module to find (since 2.0) |
No, if you wish to parse an Ivy file. Yes, if you are retrieving information about a module from an Ivy repository. |
branch |
the branch of the module to find (since 2.0) |
No, defaults to the default branch for the given module if you are retrieving information about a module from an Ivy repository. |
revision |
the revision constraint to apply (since 2.0) |
No, if you wish to parse an Ivy file. Yes, if you are retrieving information about a module from an Ivy repository. |
property |
the name to use as the base of the property names set by this task (since 2.0) |
No, will default to |
settingsRef |
A reference to Ivy settings that must be used by this task (since 2.0) |
No, defaults to |
Examples
Given this ivy.xml file:
<ivy-module version="1.0" xmlns:e="http://ant.apache.org/ivy/extra">
<info organisation="apache"
module="info-all"
branch="trunk"
revision="1.0"
status="release"
e:myextraatt="myvalue"/>
<configurations>
<conf name="default"/>
<conf name="test"/>
<conf name="private" visibility="private"/>
</configurations>
<publications>
<artifact name="thing1" type="jar" ext="jar" conf="default" e:data="main"/>
<artifact name="thing2" type="jar" ext="jar" conf="default" e:data="client"/>
</publications>
<dependencies>
<dependency org="org1" name="mod1.2" rev="2.0"/>
</dependencies>
</ivy-module><ivy:info file="${basedir}/path/to/ivy.xml"/>Parses ${basedir}/path/to/ivy.xml and set properties as described above accordingly:
ivy.organisation=apache
ivy.module=info-all
ivy.branch=trunk
ivy.revision=1.0
ivy.status=release
ivy.extra.myextraatt=myvalue
ivy.configurations=default, test, private
ivy.public.configurations=default, test
ivy.artifact.1.name=thing1
ivy.artifact.1.type=jar
ivy.artifact.1.ext=jar
ivy.artifact.1.conf=default
ivy.artifact.1.extra.data=main
ivy.artifact.2.name=thing2
ivy.artifact.2.type=jar
ivy.artifact.2.ext=jar
ivy.artifact.2.conf=default
ivy.artifact.2.extra.data=clientGiven the same Ivy module in a repository:
<ivy:info organisation="apache" module="info-all" revision="1.0"/>will set the exact same set of properties as above. Using:
<ivy:info organisation="apache" module="info-all" revision="1.0" property="infotest"/>will set:
infotest.organisation=apache
infotest.module=info-all
infotest.branch=trunk
infotest.revision=1.0
infotest.status=release
infotest.extra.myextraatt=myvalue
infotest.configurations=default, test, private
infotest.public.configurations=default, test
infotest.artifact.1.name=thing1
infotest.artifact.1.type=jar
infotest.artifact.1.ext=jar
infotest.artifact.1.conf=default
infotest.artifact.1.extra.data=main
infotest.artifact.2.name=thing2
infotest.artifact.2.type=jar
infotest.artifact.2.ext=jar
infotest.artifact.2.conf=default
infotest.artifact.2.extra.data=clientinstall
[since 1.3]
Installs a module and all its dependencies in a resolver.
The module to install should be available in a resolver, and will be installed in another resolver which should support publish.
This is particularly useful for users who only have a private repository, and want to benefit from public repositories from time to time. In this case, when a module is missing in the private repository, a call to install lets download the module from a public repository not usually used for dependency resolution, and install it and its dependencies in the private repository.
For more details about this task and its usage see the build repository tutorial
Attributes
| Attribute | Description | Required |
|---|---|---|
from |
the name of the resolver in which the module must be found |
Yes |
to |
the name of the resolver in which the module must be installed |
Yes |
organisation |
the name of the organisation of the module to install |
Yes |
module |
the name of the module to install |
Yes |
branch |
the branch of the module to install (since 2.0) |
No, defaults to default branch with exact matcher, |
revision |
the revision of the module to install |
Yes |
type |
the type(s) of artifact(s) to install. You can give multiple values separated by commas |
No, defaults to |
conf |
the configurations to install. Only the dependencies of the specified configurations will be installed. (since 2.3) |
No, defaults to |
validate |
|
No. Defaults to default Ivy value (as configured in settings) |
overwrite |
|
No, defaults to |
transitive |
|
No, defaults to |
matcher |
the name of the matcher to use to find the modules to install |
No, defaults to |
settingsRef |
A reference to Ivy settings that must be used by this task (since 2.0) |
No, defaults to |
haltonfailure |
|
No, defaults to |
installOriginalMetadata |
|
No, defaults to |
Examples
<ivy:install organisation="apache" module="commons-lang" revision="2.0" from="ivyrep" to="myfsresolver"/>Installs the module commons-lang from apache in revision 2.0 in the resolver myfsresolver. The module is found in the resolver named ivyrep.
listmodules
[since 1.4]
Finds the list of modules in the repository matching some criteria and sets a corresponding list of properties in Ant.
The criteria is set by given patterns matching the organisation, name branch and revision of the modules to find.
To know if a module matches the criteria, Ivy will use the configured pattern matcher.
Attributes
| Attribute | Description | Required |
|---|---|---|
organisation |
the pattern matching the organisation of the modules to list |
Yes |
module |
the pattern matching the name of the modules to list |
Yes |
branch |
the pattern matching the branch of the modules to list |
No, defaults to |
revision |
the pattern matching the revision of the modules to list |
Yes |
matcher |
the name of the pattern matcher to use for matching the modules fields |
No. Defaults to |
property |
the pattern of the property to set when a module is found |
Yes |
value |
The pattern of the value to set when a module is found |
Yes |
settingsRef |
A reference to Ivy settings that must be used by this task (since 2.0) |
No, defaults to |
resolver |
The name of the resolver to use for searching the modules (since 2.2) |
No, all available resolvers will be used by default. |
Examples
<ivy:listmodules organisation="apache" module="ivy" revision="*" property="ivy.[revision]" value="found"/>will find all revisions of the module ivy in the org apache, and create one property for each revision found, the name of the property depending on the revision, the value being always found
<ivy:listmodules organisation="*" module="ivy*" revision="1.0" matcher="glob" property="modules.[module]" value="[organisation]"/>use the glob matcher to find all modules which name starts with ivy with revision 1.0, and sets for each a property with module name found and organisation for value.
Example:
modules.ivy=apache
modules.ivyde=apache
modules.ivytools=ivytoolsmakepom
[since 2.0]
The makepom task allows to convert an Ivy file to a POM file.
An example of use is to publish an Ivy managed module to a Maven 2 repository.
Note that all Ivy features are not supported by Maven POMs, so the converted POM may not resolve to the exact same dependencies as the original Ivy file.
[since 2.2]
It is possible to specify a template file defining the structure of the generated POM. The following processing is done on this template:
-
properties like
${property.name}are replaced if they are defined in Ant or by theivy:makepomtask (see below for the standard properties) -
lines containing the string
SKIP_LINEare skipped. -
the defined dependencies will be added to the first
<dependencies>element encountered in the POM template. If the template doesn’t contain a<dependencies>element, it is generated at the end of the POM.
The ivy:makepom task defines following properties that can be used in the template.
-
ivy.pom.groupId: defaults to the organisation as defined in the ivy.xml file -
ivy.pom.artifactId: defaults to the value of theartifactNameattribute of this task, or the name of the module as defined in the ivy.xml file -
ivy.pom.packaging: defaults to the value of theartifactPackagingattribute of this task, or the extension of the artifact -
ivy.pom.version: defaults to the revision as defined in the ivy.xml file -
ivy.pom.name: defaults toSKIP_LINE -
ivy.pom.description: defaults to the value of thedescriptionattribute of this task, orSKIP_LINEwhen not specified -
ivy.pom.url: defaults to the homepage as defined in the ivy.xml file -
ivy.pom.license: the content of the specifiedheaderFile, orSKIP_LINEif not specified -
ivy.pom.header: some Ivy information, orSKIP_LINEif theprintIvyInfoattribute is set tofalse.
Note that each property can be given a value manually in the Ant build file. In that case, Ivy will use the value specified in the build file instead of the default value.
The default template that ships with Ivy looks like this:
${ivy.pom.license}
${ivy.pom.header}
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>${ivy.pom.groupId}</groupId>
<artifactId>${ivy.pom.artifactId}</artifactId>
<packaging>${ivy.pom.packaging}</packaging>
<version>${ivy.pom.version}</version>
<name>${ivy.pom.name}</name>
<description>${ivy.pom.description}</description>
<url>${ivy.pom.url}</url>
</project>Attributes
| Attribute | Description | Required |
|---|---|---|
ivyfile |
the source Ivy file to convert |
Yes |
pomfile |
the destination POM file to write |
Yes |
templatefile |
the template file to use when generating the POM (since 2.2) |
No, defaults to the internal template file. |
artifactName |
The name of the artifact which is represented by the generated POM file. (since 2.2) |
No, defaults to the module name in the source Ivy file. |
artifactPackaging |
The packaging of the artifact which is represented by the generated POM file. (since 2.2) |
No, the artifact type is taken by default. Defaults to |
conf |
a comma separated list of the configurations to include in the generated POM. Wildcards are supported here. (since 2.2) |
No, defaults to all configurations. |
settingsRef |
A reference to Ivy settings that must be used by this task |
No, defaults to |
printIvyInfo |
Add some information about Ivy to the generated POM. (since 2.2) |
No, defaults to |
headerFile |
the header of the generated POM file |
No |
description |
The description that will be added to the generated POM. (since 2.2) |
No, defaults to no description or (since 2.5) to the description in the source Ivy file. |
Child elements
| Element | Description | Cardinality |
|---|---|---|
mapping |
describes the mapping from an Ivy module configuration to a Maven POM scope.
These elements takes two attributes: |
0..n |
dependency |
describes extra dependencies that should be added to the generated Maven POM file.
These elements takes the following attributes: |
0..n |
Examples
<ivy:makepom ivyfile="${basedir}/path/to/ivy.xml" pomfile="${basedir}/path/to/module.pom" conf="default,runtime">
<mapping conf="default" scope="compile"/>
<mapping conf="runtime" scope="runtime"/>
<dependency group="com.acme" artifact="acme-logging" version="1.0" optional="true"/>
</ivy:makepom>Converts ${basedir}/path/to/ivy.xml to a POM and writes the result to ${basedir}/path/to/module.pom. The configuration 'default' in the parsed Ivy file will be mapped to the scope 'compile', the configuration 'runtime' will be mapped to 'runtime', and other configurations will be excluded.
The com.acme.acme-logging artifact with version 1.0 will be added as an optional dependency.
post resolve tasks
Several tasks in Ivy are considered as post resolve tasks and share a common behaviour and settings accordingly.
These tasks are:
-
artifactproperty (since 2.0)
-
artifactreport (since 2.0)
All these tasks will trigger a resolve automatically if:
-
none has already been called in the current build with the attribute
keepset totrue(see below) -
organisation and module are not set
(since 1.4) There are two ways to run a resolve: with an Ivy file, or with the inline mode. When you call resolve with an Ivy file, the default for it is to keep the resolved data for use by the subsequent post resolve tasks. When you run an inline resolve, the default is not to keep the data. You can override this behaviour by setting the keep attribute as you like.
If you want to to reuse the resolved data obtained through a call to resolve in another build (i.e. not the current one), then you have to set the organisation and module attributes. This work only if the cache was not cleaned since your last resolve call. This does not work with inline calls, which must be performed in the same build.
The attributes listed are then mostly used only if a resolve is triggered automatically.
Attributes
| Attribute | Description | Required |
|---|---|---|
conf |
a comma separated list of the configurations to retrieve or |
No. Defaults to the configurations resolved by the last resolve call, or |
inline |
|
No. defaults |
organisation |
the organisation of the module to retrieve. This usually doesn’t need to be set since it defaults to the last resolved one, except for inline mode where it is required. |
Yes in inline mode, otherwise no, it then defaults to last resolved module name |
module |
the name of the module to retrieve. This usually doesn’t need to be set since it defaults to the last resolved one, except for inline mode where it is required. |
Yes in inline mode, otherwise no, it then defaults to last resolved module name |
revision |
the revision constraint of the module to retrieve. Used only in inline mode. (since 1.4) |
No. Defaults to latest.integration |
branch |
the name of the branch to resolve in inline mode (since 2.1) |
Defaults to no branch in inline mode, nothing in standard mode. |
changing |
indicates that the module may change when resolving in inline mode. See cache and change management for details. Ignored when resolving in standard mode (since 2.2). |
No. Defaults to |
transitive |
|
No. Defaults to |
resolveMode |
the resolve mode to use when an automatic resolve is triggered (since 2.1) |
No. defaults to using the resolve mode set in the settings |
keep |
|
No. defaults to |
haltonfailure |
|
No. Defaults to |
validate |
|
No. Defaults to default Ivy value (as configured in settings) |
refresh |
|
No. defaults to |
file |
the file to resolve if a resolve is necessary (since 2.0) |
No. Defaults to the previous resolved Ivy file or to |
settingsRef |
A reference to Ivy settings that must be used by this task (since 2.0) |
No, defaults to |
resolveId |
The id which was used for a previous resolve, or the resolveId if a new resolve is performed (since 2.0) |
No, defaults to |
log |
the log setting to use during the resolve process (since 2.0) Available options are: |
No, defaults to |
Child elements
[since 2.3]
These child elements are defining an inlined ivy.xml’s dependencies elements. Thus these child elements cannot be used together with the inline or file attributes.
There is one important difference with the ivy.xml’s dependencies: there is no master configuration to handle here. There is actually only one, the one on which the resolve will run. So every attribute in dependency, exclude, override or conflict which is about a master configuration is not supported. And every attribute about a mapping of a master configuration on a dependency configuration is now expecting only the dependency configuration.
| Element | Description | Cardinality |
|---|---|---|
declares a dependency to resolve |
0..n |
|
excludes artifacts, modules or whole organizations from the set of dependencies to resolve |
0..n |
|
specify an override mediation rule, overriding the revision and/or branch requested for a transitive dependency (since 2.0) |
0..n |
Examples
<ivy:cachepath organisation="emma" module="emma" revision="2.0.4217" inline="true" conf="ant" pathid="emma.classpath"/>
<taskdef resource="emma_ant.properties" classpathref="emma.classpath"/>Resolves the Emma module in version 2.0.4217, constructs an Ant path with the corresponding artifacts, and then defines the Emma tasks using this path.
publish
Publishes the current module’s artifacts and the resolved descriptor (delivered Ivy file).
This task is meant to publish the current module descriptor together with its declared publication artifacts to a repository.
All the artifacts must have been created before calling this task. It does not create the artifacts themselves, but expects to find them at the location indicated by the artifacts pattern.
The target repository is given through the name of a resolver declared in current Ivy settings. See Settings Files for details about resolver supporting artifact publishing.
It also publishes the delivered Ivy file (except if you don’t want), and even delivers it, if it has not been done with a previous deliver call or if forcedeliver is set to true. That’s why this task takes some parameters useful only for delivery. See the illustration below:
(since 1.4.1) The source artifact pattern can be specified either as an attribute on the task (artifactspattern) or using a list of nested artifacts element (see examples below).
Attributes
| Attribute | Description | Required |
|---|---|---|
organisation |
the name of the organisation of the module to publish |
No. Defaults to |
module |
the name of the module to publish |
No. Defaults to |
revision |
the revision of the module to publish and also the published revision unless pubrevision is set |
No. Defaults to |
artifactspattern |
the pattern to use to find artifacts to publish |
No. Defaults to |
resolver |
the name of the resolver to use for publication |
Yes |
pubrevision |
the revision to use for the publication |
No. Defaults to the |
pubbranch |
the branch to use for the publication |
No. Defaults to the |
forcedeliver |
|
No. Defaults to |
update |
|
No. Defaults to |
merge |
if this descriptor extends a parent, merge the inherited information directly into this descriptor on publish. The extends element itself will be commented out in the published descriptor. (since 2.2) |
No. Defaults to false |
validate |
|
No. Defaults to default Ivy value (as configured in settings file) |
replacedynamicrev |
|
No. Defaults to |
publishivy |
|
No. Defaults to |
conf |
A comma separated list of configurations to publish (since 1.4.1). Accepts wildcards (since 2.2). |
No. Defaults to all configurations |
overwrite |
|
No. Defaults to |
warnonmissing |
|
No. Defaults to |
haltonmissing |
|
No. Defaults to |
srcivypattern |
the pattern to use to find Ivy file to publish, and even deliver if necessary (since 1.2) |
No. Defaults to the value of |
pubdate |
the publication date to use for the delivery, if necessary. This date should be either |
No. Defaults to |
status |
the status to use for the delivery, if necessary |
No. Defaults to |
delivertarget |
the target to call for recursive delivery |
No. No recursive delivery is done by default |
settingsRef |
A reference to Ivy settings that must be used by this task (since 2.0) |
No, default to |
Child elements
| Element | Description | Cardinality |
|---|---|---|
artifact |
Describe additional artifacts to publish. These elements can have any attributes: standard artifact attributes and (since 2.2) extra attributes are supported. |
0..n |
artifacts |
Specify the pattern used to find the artifact. These elements have a |
0..n |
Examples
<ivy:publish resolver="local" pubrevision="1.0">
<artifacts pattern="build/artifacts/jars/[artifact].[ext]"/>
<artifacts pattern="build/artifacts/zips/[artifact].[ext]"/>
</ivy:publish>Publishes the last resolved module in the local resolver with revision 1.0, looking for artifacts in directories build/artifacts/jars and build/artifacts/zips.
report
Generates reports of dependency resolving. One report per configuration is generated, but all reports generated together are hyperlinked one to each other.
This task should be used only after a call to resolve, even if the call was not done during the same Ant build. In fact, this task uses XML report generated by resolve in cache. So if you call resolve on a module for a given configuration, you can call report safely on this module and this configuration as long as you do not clean your Ivy cache.
If you want to have an idea of what reports look like, check this very simple example. The task also generates a GraphML file which can be loaded with the free yEd graph editor. Then following a few simple steps you can obtain a graph like this one.
{kind=link}
(since 1.4) If a custom XSLT is specified, it’s possible to specify additional parameters to the stylesheet.
Attributes
| Attribute | Description | Required |
|---|---|---|
todir |
the directory to which reports should be generated |
No, defaults to |
outputpattern |
the generated report names pattern |
No, defaults to |
xsl |
|
No, defaults to |
xml |
|
No, defaults to |
graph |
|
No, defaults to |
dot |
|
No, defaults to |
conf |
a comma separated list of the configurations for which a report should be generated |
No. Defaults to the configurations resolved by the last resolve call (during same Ant build), or |
organisation |
the name of the organisation of the module for which report should be generated |
No, unless resolveId has not been specified and no resolve was called during the build. Defaults to last resolved module organisation. |
module |
the name of the module for which report should be generated |
No, unless resolveId has not been specified and no resolve was called during the build. Defaults to last resolved module. |
validate |
true to force Ivy files validation against ivy.xsd, false to force no validation |
No. Defaults to default Ivy value (as configured in settings) |
xslfile |
indicates which xsl file should be used to generate the report |
No, defaults to Ivy provided xsl which generates html report |
settingsRef |
A reference to Ivy settings that must be used by this task (since 2.0) |
No, defaults to |
resolveId |
The id which was used for a previous resolve (since 2.0) |
No, defaults to |
Examples
To generate a HTML and GraphML report:
<report conf="compile"/>To generate a HTML report only:
<report conf="compile" graph="false"/>To generate an XML report using a custom stylesheet:
<report conf="compile" xslfile="my-custom-stylesheet.xsl" xslext="xml"/>To generate an XML report using a custom stylesheet which needs some parameters:
<report conf="compile" xslfile="my-custom-stylesheet.xsl" xslext="xml">
<param name="param1" expression="value1"/>
<param name="param2" expression="value2"/>
</report>Using yEd to layout report graphs
yEd is a free graph editor, benefiting from all the automatic layouts of yFiles. Ivy is able to generate graphs which are readable by yEd.
The graphs generated by Ivy are not laid out (in fact, it’s why we use yEd), so you have to follow a simple sequence of steps to layout the generated graphs.
Preparation
First you have to generate a GraphML file. Simply call the report task (see Ivy use documentation) for that.
Step 1: open the GraphML file
Launch yEd editor, and open the GraphML file generated by the report task. You should obtain something like this:

Step 2: ask yEd to adjust nodes size



Step 3: ask yEd to layout nodes



That’s all, you should have obtained something like this:

Note that this is only one possibility, test the available layouts yourself, you could find one better in your case. Once you have laid out the graph, you can either save it with in the same file (but be warned that it will be overwritten at next Ivy report call), or another file, export it to JPEG, GIF, SVG, etc. (see yEd site for details).
repreport
[since 1.4]
Generates reports about dependencies among several modules in the repository (repreport stands for repository report).
This task is similar to the report task, except that instead of working on a single module you just resolved, it works with a set of modules in your repository.
Note that the set of modules for which you generate the report is determined by setting organisation module and revision and using a matcher, but also by the dependencies of these modules. No dependency is excluded.
Usually the most useful report is a graph, you can generate either a GraphML file that you can then easily layout using yEd, or a DOT file which is the format recognized by Graphviz, which is a free tool that does automatic graph layout, and can thus be used to generate automatically a GIF, PNG or SVG of the dependencies between all your modules.
Limitation: this task requires to be able to browse the repository, and is thus limited to resolvers supporting repository listing. In particular, it means it doesn’t work to report all organizations in a repository using m2compatible mode. Moreover, to be able to list organizations, this task requires an [organisation] token in the resolver(s) used.
Attributes
| Attribute | Description | Required |
|---|---|---|
organisation |
A pattern matching the organisation of the modules for which the report should be generated |
No, defaults to |
module |
A pattern matching the name of the modules for which the report should be generated |
No, defaults to |
branch |
The name of the branch of the modules for which the report should be generated |
No, defaults to no branch specified |
revision |
The revision of the modules for which the report should be generated. Only one revision per module will be used, so most of the time keeping the default ( |
No, defaults to |
todir |
the directory to which reports should be generated |
No, defaults to execution directory |
outputname |
the name to use for the generate file (without extension) |
No, defaults to |
xml |
|
No, defaults to |
xsl |
|
No, defaults to |
xslfile |
indicates which xsl file should be used to generate the report |
Yes, if you want to use XSLT |
xslext |
indicates the extension to use when generating report using XSLT |
No, defaults to |
graph |
|
No, defaults to |
dot |
|
No, defaults to |
matcher |
the name of the matcher to use for matching modules names and organisations in your repository |
No. Defaults to |
validate |
|
No. Defaults to default Ivy value (as configured in settings) |
settingsRef |
A reference to Ivy settings that must be used by this task (since 2.0) |
No, defaults to |
Examples
To generate a XML report for all the latest versions of all the modules in your repository:
<ivy:repreport/>To generate a GraphML report for all the latest versions of all the modules in your repository:
<ivy:repreport xml="false" graph="true"/>To generate a XML report for all the latest versions of the modules from the organisation foo in your repository:
<ivy:repreport organisation="foo"/>To generate a XML report for all the versions on the 1.x stream of the modules named bar* from the organisation foo in your repository:
<ivy:repreport organisation="foo" module="bar*" revision="1.+" matcher="glob"/>To generate an XML report using a custom stylesheet:
<ivy:repreport xsl="true" xslfile="my-custom-stylesheet.xsl" xslext="xml"/>To generate an XML report using a custom stylesheet which needs some parameters:
<ivy:repreport xsl="true" xslfile="my-custom-stylesheet.xsl" xslext="xml">
<param name="param1" expression="value1"/>
<param name="param2" expression="value2"/>
</report>resolve
The resolve task actually resolves dependencies described in an Ivy file, and puts the resolved dependencies in the Ivy cache. If configure has not been called before resolve is called, a default configuration will be used (equivalent to calling configure without attributes).
After the call to this task, four properties are set in Ant:
-
ivy.organisation: set to the organisation name found in the Ivy file which was used for resolve -
ivy.module: set to the module name found in the Ivy file which was used for resolve -
ivy.revision: set to the revision name found in the Ivy file which was used for resolve, or a generated revision name if no revision was specified in the file -
ivy.resolved.configurations: set to the comma separated list of configurations resolved
(since 1.2) An additional property is set to true if the resolved dependencies are changes since the last resolve, and to false otherwise: ivy.deps.changed.
(since 2.0) The property ivy.deps.changed will not be set (and not be computed) if you set the parameter checkIfChanged to false. (By default, it is true to keep backward compatibility). This allows to optimize your build when you have multi-module build with multiple configurations.
(since 2.0) In addition, if the resolveId attribute has been set, the following properties are set as well:
-
ivy.organisation.${resolveId} -
ivy.module.${resolveId} -
ivy.revision.${resolveId} -
ivy.resolved.configurations.${resolveId} -
ivy.deps.changed.${resolveId}
(since 2.4) If current module extends other modules:
-
ivy.parents.count: number of parent modules -
ivy.parent[index].organisation: set to the organisation name found in the parent Ivy file which was used for resolve -
ivy.parent[index].module: set to the module name found in the parent Ivy file which was used for resolve -
ivy.parent[index].revision: set to the revision name found in the parent Ivy file which was used for resolve -
ivy.parent[index].branch: set to the branch name found in the parent Ivy file which was used for resolve
Where index represent the index of extends module.
When Ivy has finished the resolve task, it outputs a summary of what has been resolved. This summary looks like this:
---------------------------------------------------------------------
| | modules || artifacts |
| conf | number| search|dwnlded|evicted|| number|dwnlded|
---------------------------------------------------------------------
| default | 4 | 0 | 0 | 0 || 4 | 0 |
---------------------------------------------------------------------This table gives some statistics about the dependency resolution. Each line correspond to a configuration resolved. Then the table is divided in two parts:
-
modules-
number: the total number of dependency modules resolved in this configuration, including transitive ones -
search: the number of dependency modules that required a repository access. The repository access is needed if the module is not yet in cache, or if a latest version is required, or in some other cases (depending oncheckModified, for instance) -
dwnlded: the number of dependency Ivy files downloaded from the repository. This number can be less than the total number of modules even with a clean cache, if no Ivy file is provided for some dependencies. -
evicted: the number of dependency module evicted by conflict managers.
-
-
artifacts-
number: the total number of artifacts resolved in the given configuration. -
dwnlded: the number of artifacts actually downloaded from the repository.
-
Inline mode
[since 1.4]
The inline mode allows to call a resolve without an Ivy file, by setting directly the module which should be resolved from the repository. It is particularly useful to install released software, like an Ant task for example. When `inline` is set to `true`, the organisation module and revision attributes are used to specify which module should be resolved from the repository.
Remark: if you want the standard Ivy properties to be set or to reuse the results of an inline resolve by other post-resolve tasks like retrieve, cachepath, report…, you must set the keep attribute to true!
Resolve mode
[since 2.0]
The resolve mode allows to define how Ivy should use dependency revision constraints when performing the resolution.
Two modes are available:
-
default: in this mode the default revision constraint (expressed with therevattribute in the dependency element) is used. -
dynamic: in this mode the dynamic revision constraint (expressed with therevConstraintattribute in the dependency element) is used.
Concurrency
During resolve, Ivy creates a file in the resolution cache. The creation of this file is not aimed to support concurrency, meaning that you can’t have two concurrent resolve of the same module, in the same resolution cache, with the same resolveId.
Note for developers: after the call to this task, a reference to the module descriptor resolved is put in the Ant project under the id ivy.resolved.descriptor.
Attributes
| Attribute | Description | Required |
|---|---|---|
file |
path to the Ivy file to use for resolution |
No. Defaults to |
conf |
a comma separated list of the configurations to resolve, or |
No. Defaults to |
refresh |
|
No. defaults to |
resolveMode |
the resolve mode to use for this dependency resolution process (since 2.0) |
No. defaults to using the resolve mode set in the settings |
inline |
|
No. defaults to |
keep |
|
No. defaults to |
organisation |
the organisation of the module to resolve in inline mode (since 1.4) |
Yes in inline mode, no otherwise. |
module |
the name of the module to resolve in inline mode (since 1.4) |
Yes in inline mode, no otherwise. |
revision |
the revision constraint to apply to the module to resolve in inline mode (since 1.4) |
No. Defaults to |
branch |
the name of the branch to resolve in inline mode (since 2.1) |
Defaults to no branch in inline mode, nothing in standard mode. |
changing |
indicates that the module may change when resolving in inline mode. See cache and change management for details. Ignored when resolving in standard mode. (since 1.4) |
No. Defaults to |
type |
comma separated list of accepted artifact types (since 1.2) |
No. defaults to |
haltonfailure |
|
No. Defaults to |
failureproperty |
the name of the property to set if the resolve failed (since 1.4) |
No. No property is set by default. |
transitive |
|
No. Defaults to |
showprogress |
|
No. Defaults to |
validate |
|
No. Defaults to default Ivy value (as configured in settings) |
settingsRef |
A reference to Ivy settings that must be used by this task (since 2.0) |
No, defaults to |
resolveId |
An id which can be used later to refer to the results of this resolve (since 2.0) |
No, defaults to |
log |
the log setting to use during the resolve process (since 2.0) Available options are: |
No, defaults to |
checkIfChanged |
When set to |
No, default to |
useCacheOnly |
When set to |
No, default to |
Child elements
[since 2.3]
These child elements are defining an inlined ivy.xml’s dependencies elements. Thus these child elements cannot be used together with the inline or file attributes.
There is one important difference with the ivy.xml’s dependencies: there is no master configuration to handle here. There is actually only one, the one on which the resolve will run. So every attribute in dependency, exclude, override or conflict which is about a master configuration is not supported. And every attribute about a mapping of a master configuration on a dependency configuration is now expecting only the dependency configuration.
| Element | Description | Cardinality |
|---|---|---|
declares a dependency to resolve |
0..n |
|
excludes artifacts, modules or whole organizations from the set of dependencies to resolve |
0..n |
|
specify an override mediation rule, overriding the revision and/or branch requested for a transitive dependency (since 2.0) |
0..n |
Examples
<ivy:resolve file="path/to/ivy.xml"/>Resolve all dependencies declared in path/to/ivy.xml file.
<ivy:resolve file="path/to/ivy.xml" transitive="false"/>Same as above, but with transitive dependencies disabled.
<ivy:resolve file="path/to/ivy.xml" conf="default, test"/>Resolve the dependencies declared in the configuration default and test of the path/to/ivy.xml file.
<ivy:resolve file="path/to/ivy.xml" type="jar"/>Resolve all dependencies declared in path/to/ivy.xml file, but download only jar artifacts.
<ivy:resolve organisation="apache" module="commons-lang" revision="2+" inline="true"/>Resolve the commons-lang module revision 2+ from the repository, with its dependencies.
<ivy:resolve>
<dependency org="apache" name="commons-lang" rev="2+"/>
<dependency org="apache" name="commons-logging" rev="1.1"/>
<exclude org="apache" module="log4j"/>
</ivy:resolve>Resolve of both commons-lang and commons-logging, with their dependencies but not log4j.
<ivy:resolve>
<dependency org="org.slf4j" module="slf4j" rev="1.6" conf="api,log4j"/>
</ivy:resolve>Resolve the configurations api and log4j of slf4j.
resources
[since 2.3] (Ant 1.7 required)
ivy:resources is an Ant resource collection, containing files found by an Ivy resolve, which then can be used with any task working with resources like copy or import.
This datatype shares the same attributes, child elements and behaviour of a post resolve task. It is not expected to be used as an Ant task though, only as a resource collection.
Examples
<ivy:resources file="path/to/ivy.xml"/>Build a resource collection of every artifacts of all dependencies declared in path/to/ivy.xml file.
<ivy:resources file="path/to/ivy.xml" transitive="false"/>Same as above, but with transitive dependencies disabled.
<ivy:resources file="path/to/ivy.xml" conf="default, test"/>Build a resource collection of every artifacts of the dependencies declared in the configuration default and test of the path/to/ivy.xml file.
<ivy:resources file="path/to/ivy.xml" type="jar"/>Build a resource collection of every jar artifact of all dependencies declared in path/to/ivy.xml file.
<ivy:resources organisation="apache" module="commons-lang" revision="2+" inline="true"/>Build a resource collection of every artifacts of commons-lang module revision 2+ from the repository, with its dependencies.
<ivy:resources>
<dependency org="apache" module="commons-lang" rev="2+"/>
<dependency org="apache" module="commons-logging" rev="1.1"/>
<exclude org="apache" module="log4j"/>
</ivy:resources>Build a resource collection of every artifacts of both commons-lang and commons-logging, with their dependencies but not log4j.
<ivy:resources>
<dependency org="org.slf4j" module="slf4j" rev="1.6" conf="api,log4j"/>
</ivy:resources>Build a resource collection of every artifacts of the configurations api and log4j of slf4j.
retrieve
The retrieve task copies resolved dependencies anywhere you want in your file system.
This is a post resolve task, with all the behaviour and attributes common to all post resolve tasks.
(since 1.4) This task can even be used to synchronize the destination directory with what should actually be in according to the dependency resolution. This means that by setting sync="true", Ivy will not only copy the necessary files, but it will also remove the files which do not need to be there.
The synchronisation actually consists in deleting all filles and directories in the root destination directory which are not required by the retrieve.
The root destination directory is the the directory denoted by the first level up the first token in the destination pattern.
For instance, for the pattern lib/[conf]/[artifact].[ext], the root will be lib.
(since 2.3) A nested mapper element can be used to specify more complex filename transformations of the retrieved files. See the examples below.
Attributes
| Attribute | Description | Required |
|---|---|---|
pattern |
the pattern to use to copy the dependencies |
No. Defaults to |
ivypattern |
the pattern to use to copy the Ivy files of dependencies (since 1.3) |
No. Dependency Ivy files are not retrieved by default. |
conf |
a comma separated list of the configurations to retrieve |
No. Defaults to the configurations resolved by the last resolve call, or |
sync |
|
No. Defaults to |
type |
comma separated list of accepted artifact types (since 1.4) |
No. All artifact types are accepted by default. |
overwriteMode |
option to configure when the destination file should be overwritten if it exists (since 2.2). Possible values are: |
No. Defaults to |
symlink |
|
No. Defaults to |
symlinkmass |
Deprecated since 2.5 This option is no longer supported or relevant. |
No. Defaults to |
settingsRef |
A reference to Ivy settings that must be used by this task (since 2.0) |
No, defaults ot |
log |
the log setting to use during the resolve and retrieve process. (since 2.0) Available options are the same as for resolve when used to trigger resolve automatically (see postresolvetask), or the following for the retrieve process only: |
No, defaults to |
pathId |
the id of the path to create containing the retrieved artifacts. (since 2.3) |
No. No path is created by default. |
setId |
the id of the fileset to create containing the retrieved artifacts. (since 2.3) |
No. No fileset is created by default. |
Examples
<ivy:retrieve/>Retrieves dependencies using default parameters. This usually retrieves all the dependencies of the last resolve call to a lib directory.
<ivy:retrieve pattern="${lib.dir}/[conf]/[artifact].[ext]"/>Retrieves all dependencies of the last resolve call to a lib directory, dependencies being separated in directories named by configuration, each conf directory containing corresponding artifacts without the revision. For instance, if the Ivy file declares two configurations default and test, the resulting lib dir could look like this:
lib
default
commons-lang.jar
commons-logging.jar
test
junit.jarNote that if a dependency is required in the two configurations, it will be copied in the two directories. The download of the dependency is however only made once at resolve time.
<ivy:retrieve pattern="${lib.dir}/[conf]/[artifact].[ext]" sync="true"/>Same as before, but with synchronisation enabled.
For instance, if the Ivy file declares two configurations default and test, the resulting lib dir could look like this:
lib
default
commons-lang.jar
commons-logging.jar
test
junit.jarAnd now suppose commons-logging is no longer part of the dependencies of the default configuration, then a new call to retrieve will result in:
lib
default
commons-lang.jar
test
junit.jarWith no synchronisation, commons-logging would not have been removed by the call.
<ivy:retrieve pattern="${lib.dir}/[type]/[artifact]-[revision].[ext]" conf="runtime"/>Retrieves only the dependencies of the runtime. Dependencies separated in directories named by artifact type. The resulting lib dir could look like this:
lib
jar
commons-lang-1.0.jar
looks-1.1.jar
source
looks-1.1.zip<ivy:retrieve pattern="${lib.dir}/[organisation]/[artifact]-[revision].[ext]"/>Retrieves all dependencies of the last resolve call to a lib directory. The [organisation] token will get the unmodified organisation value. The resulting lib dir could look like this:
lib
org.apache
commons-lang-1.0.jar
org.junit
junit-4.1.jar
junit-4.1.zip<ivy:retrieve pattern="${lib.dir}/[orgPath]/[artifact]-[revision].[ext]"/>Retrieves all dependencies of the last resolve call to a lib directory. The [orgPath] token will get a tree structure. The resulting lib dir could look like this:
lib
org
apache
commons-lang-1.0.jar
junit
junit-4.1.jar
junit-4.1.zip<ivy:retrieve organisation="foo" module="bar" inline="true" pattern="${my.install.dir}/[artifact].[ext]"/>Resolves and retrieves the latest version of the module bar and its dependencies in the directory pointed by ${my.install.dir}.
<ivy:retrieve pattern="lib/[artifact]-[revision].[ext]">
<firstmatchmapper>
<globmapper from="lib/*-SNAPSHOT.jar" to="lib/snapshots/*-SNAPSHOT.jar"/>
<globmapper from="lib/*" to="lib/releases/*"/>
</firstmatchmapper>
</ivy:retrieve>Retrieves all dependencies of the last resolve call to a lib directory. The jar files with a version equal to SNAPSHOT are retrieved in a snapshots directory. The other ones are retrieved in a releases directory.
settings
[since 2.0]
The settings declaration is used to configure Ivy with a settings XML file. The difference with the configure task is that when using the settings declaration, the configuration of Ivy will be done when the settings are first needed (for instance, when you do a resolve), while the configure task will perform a configuration of Ivy instantly, which makes it easier to see the problem if something goes wrong.
See Settings Files for details about the settings file itself.
Multiple settings can be defined in a build script. Every task can reference its own settings.
All Ivy variables set during the settings are available in the Ant project as long as they were not set in Ant before (Ant properties are immutable).
Moreover, the variables are exposed under two names: the variable name, and the variable name suffixed by dot + the settings id.
For instance, if you load a settings with the id myid, and define a variable my.variable=my.value in the Ivy settings, both my.variable and my.variable.myid will now be available as properties in Ant and equal to my.value. If you later load another settings with the id yourid, and in this settings assign the variable my.variable the value your.value, in the Ant project you will have:
my.variable=my.value
my.variable.myid=my.value
my.variable.yourid=your.valueAttributes
| Attribute | Description | Required |
|---|---|---|
id |
The settings id usable in the |
No, defaults to |
file |
path to the settings file to use |
No. If a file is provided, URL is ignored. If none are provided, then it attempts to find a file at |
url |
URL of the settings file to use |
|
host |
HTTP authentication host |
No, unless authentication is required |
realm |
HTTP authentication realm |
|
username |
HTTP authentication user name |
|
passwd |
HTTP authentication password |
HTTP Authentication
Note: HTTP authentication can be used only if HttpComponents HttpClient library (minimum of 4.5.3 version) and its dependencies are in your classpath.
If any of the URLs you use in Ivy (especially in dependency resolvers) needs HTTP authentication, then you have to provide the host, realm, username and passwd attributes of the configure task. These settings will then be used in any further call to Ivy tasks.
Multiple classloader
A special attention should be applied when you have a multi-project build with subant call, using Ivy task loaded by a typedef. Indeed in this situation, it is possible to pass settings reference to a subbuild. When you do that, you should take care of the classloader. The Ivy task of your subant should not be defined in a different classloader than the parent one. This can be achieved by using the loader parameter of the antlib declaration, or avoid to reload the Ivy antlib in the subbuild (place the taskdef in a target only executed when the antlib is not yet loaded).
Examples
Simplest settings
<ivy:settings/>Use either ${ivy.settings.file} if it exists, or the default settings file
This simplest setting is implicit.
Configure with a file
<ivy:settings file="mysettings.xml"/>Configure with an URL
<ivy:settings url="http://mysite.com/mysettings.xml"/>Configure multiple realms which require authentication
<ivy:settings file="path/to/my/ivysettings.xml">
<credentials host="myhost.com" realm="My Realm" username="myuser" passwd="mypasswd"/>
<credentials host="yourhost.com" realm="Your Realm" username="myuser" passwd="myotherpasswd"/>
</ivy:settings>Configure 2 different settings
You can use multiple Ivy settings during a build. Then every Ivy task should specify the settings it uses using the settingsRef attribute.
<ivy:settings id="ivy.normal.settings" file="normal_settings.xml"/>
<ivy:settings id="ivy.release.settings" file="release_settings.xml"/>
<ivy:resolve settingsRef="ivy.normal.settings"/>
<ivy:resolve settingsRef="ivy.release.settings"/>var
Sets a variable (by name and value), or set of variables (from file or URL) in Ivy.
Variables are case sensitive.
Contrary to Ant properties, Ivy variables are mutable. But a problem with this is that you do not control when variables are substituted, and usually it is done as soon as possible. So changing the value of a variable will have no effect if it has already been substituted. Consequently, using this task is NOT recommended.
See reference page for details about Ivy variables.
Attributes
| Attribute | Description | Required |
|---|---|---|
name |
the name of the variable to set |
No |
value |
the value of the variable to set |
Yes when using the name attribute |
file |
the filename of the property file to load as Ivy variables |
One of these, when not using the name attribute |
url |
the URL from which to read Ivy variables |
|
prefix |
Prefix to apply to variables. A dot ( |
No |
settingsRef |
A reference to Ivy settings that must be used by this task (since 2.0) |
No, defaults to |
Using standalone
Ivy can be used as a standalone program very easily. All you need is a Java 7+ runtime environment (JRE)!
Then here is how to call it:
java -jar ivy.jar -?It will display usage text as follows:
usage: ivy
==== settings options
-settings <settingsfile> use given file for settings
-properties <propertiesfile> use given file for properties not specified in set
tings
-cache <cachedir> use given directory for cache
-novalidate do not validate ivy files against xsd
-m2compatible use Maven 2 compatibility
==== resolve options
-ivy <ivyfile> use given file as ivy file
-refresh refresh dynamic resolved revisions
-dependency <organisation> <module> <revision>
use this instead of ivy file to do the rest of the
work with this as a dependency.
-confs <configurations> resolve given configurations
-types <types> accepted artifact types
-mode <resolvemode> the resolve mode to use
-notransitive do not resolve dependencies transitively
==== retrieve options
-retrieve <retrievepattern> use given pattern as retrieve pattern
-ivypattern <pattern> use given pattern to copy the ivy files
-sync use sync mode for retrieve
-symlink create symbolic links
-overwriteMode <overwriteMode> use given overwrite mode for retrieve
==== cache path options
-cachepath <cachepathfile> outputs a classpath consisting of all dependencies
in cache (including transitive ones) of the given
ivy file to the given cachepathfile
==== deliver options
-deliverto <ivypattern> use given pattern as resolved ivy file pattern
==== publish options
-publish <resolvername> use given resolver to publish to
-publishpattern <artpattern> use given pattern to find artifacts to publish
-revision <revision> use given revision to publish the module
-status <status> use given status to publish the module
-overwrite overwrite files in the repository if they exist
==== makepom options
-makepom <pomfilepath> create a POM file for the module
==== http auth options
-realm <realm> use given realm for HTTP AUTH
-host <host> use given host for HTTP AUTH
-username <username> use given username for HTTP AUTH
-passwd <passwd> use given password for HTTP AUTH
==== launcher options
-main <main> the FQCN of the main class to launch
-args <args> the arguments to give to the launched process
-cp <cp> extra classpath to use when launching process
==== message options
-debug set message level to debug
-verbose set message level to verbose
-warn set message level to warn
-error set message level to error
==== help options
-? display this help
-deprecated show deprecated options
-version displays version information(since 1.3) System properties are included as Ivy variables, so you can easily define an Ivy variable like this:
java -Dmyivyvar=myvalue org.apache.ivy.Main [parameters](since 2.5) Additional properties defined in a separate .properties file (rather than Ivy settings) can be loaded using -properties option like this:
java -jar ivy.jar -properties version.properties -main org.apache.tools.ant.Main|
Note
|
Prior to 2.5, Ivy -main created a classloader that used Ivy classloader as a parent. This is no longer the case; if your usage depended on Ivy classes being available, Ivy must be declared as a dependency of the component that you want to launch.
|
(since 2.5) Ivy can convert ivy.xml files to pom.xml files using -makepom option.
Examples
java -jar ivy.jarcalls Ivy with default configuration using ivy.xml in the current dir
java -jar ivy.jar -settings path/to/myivysettings.xml -ivy path/to/myivy.xmlcalls Ivy with given Ivy settings file using given Ivy file
(since 1.3)
java -jar ivy.jar -settings path/to/myivysettings.xml -dependency apache commons-lang 2.0calls Ivy with given Ivy settings file and resolve apache commons-lang 2.0.
This is equivalent to:
java -jar ivy.jar -settings path/to/myivysettings.xml -ivy ivy.xmlwith ivy.xml like this:
<ivy-module version="1.0">
<info organisation="org"
module="standalone"
revision="working"/>
<dependencies>
<dependency org="apache" name="commons-lang" rev="2.0" conf="default->*"/>
</dependencies>
</ivy-module>(since 1.3)
java -jar ivy.jar -settings path/to/myivysettings.xml -ivy path/to/myivy.xml -cachepath mycachefile.txtcalls Ivy with given Ivy settings file and resolves the dependencies found in the given Ivy file, and then outputs the classpath of resolved artifacts in cache in a file. This file can then be used to define a classpath corresponding to all the resolved dependencies for any Java program.
(since 1.4)
java -jar ivy.jar -settings path/to/myivysettings.xml -dependency bar foo 2.0 -main org.bar.foo.FooMaincalls Ivy with given Ivy settings file and resolves the dependency bar foo 2.0, and then runs org.foo.FooMain class with the resolved artifacts as classpath.
OSGi
Since Apache Ivy™ 2.3, some support for OSGi™ dependency management has been introduced.
|
Warning
|
Note that this feature is considered as experimental. It should work with simple configuration but may not in complex ones. If you have any issue with that feature, you are welcomed to come discuss your use case on the ivy-user mailing list, or discuss about implementation issues or improvement you may have found, on ant-dev. |
So with a standard ivy.xml, you can express some dependency on some OSGi bundle and every of their transitive dependencies will be resolved. You can also declare in your ivy.xml some OSGi dependency, like a Require-Bundle, an Import-Package or an Import-Service, miming an OSGi MANIFEST.MF.
Note on the implementation
With OSGi we can declare different kind of capabilities of a bundle which can match different kind of requirements of some other bundles (Require-Bundle/Bundle-SymbolicName, Import-Package/Export-Package, Import-Service/Export-Service). In Ivy we only have one kind of requirement and one kind of capability: the symbolic name of the bundle. Due to that restriction Ivy may not resolve exactly how we would expect with OSGi. The runtime of Ivy won’t be as smart as a pure OSGi dependency manager. But we think that the mapping is working for most of the use cases involving OSGi dependencies management.
Details on the mapping of the OSGi dependency model into Ivy’s one can be found in this page.
Repository descriptor based resolvers
Since the nature of the OSGi dependencies, resolving against a repository cannot be started before acquiring the metadata of every bundle of the repository. To resolve an Import-Package, Ivy has to find every bundle which has the proper Export-Package. So unlike the usual Ivy resolvers, the OSGi capable ones have to get the descriptor before starting a resolve.
The descriptor probably being not instantly downloaded, the descriptor is put in cache. (FIXME not implemented)
Use cases
Here are different use case of using the OSGi capabilities of Ivy:
OSGi mapping
This page is a description of how OSGi™ dependencies are mapped into Apache Ivy™ ones
Goal: the purpose of this mapping is to transform an OSGi manifest into an ivy.xml, so Ivy can understand OSGi bundles and resolve them. We don’t want to do the reverse here.
Bundle Symbolic name / Ivy organisation and module
In OSGi a bundle is identified by its symbolic name. In Ivy there is a notion of organisation and module name.
The chosen mapping is:
-
The organisation is "bundle" (transitive dependencies like packages or services have their own organisations, "package" and "service")
-
The module name is the symbolic name
OSGi |
Ivy |
|
|
Version and version range
The OSGi specification defines a version as a composition of 3 numbers and an arbitrary qualifier. This fits well into the lazy definition of Ivy. We will just have to use a special latest strategy in Ivy.
When it comes to version ranges, Ivy will correctly understand fully defined range as [1.2.3,1.4.9) or (1.2.3,1.4.9]. But for OSGi version range defined as 1.2.3, it has to be transformed into [1.2.3,)
OSGi |
Ivy |
|
|
|
|
Ivy configurations
Ivy has the concept of module configurations. OSGi on the other hand, doesn’t have such a concept. However, Ivy defines the following configurations, when it comes to dependency mapping for OSGi:
-
default: it will contain every required dependency (transitively) -
optional: it will contain every optional dependency and every required dependency the the first degree dependencies. -
transitive-optional: it will contain every optional dependency (optional transitively)
Additionally, Ivy defines some more configurations while dealing with the use parameter of the Import-Package OSGi manifest header. All of these kinds of configuration have their names starting with use_.
OSGi capabilities
Generally speaking, declaring capabilities in an ivy.xml is useless (in the scope of this mapping which is to transform an OSGi manifest into an ivy.xml and not the reverse). In the resolve process we want to find the bundles which have the capability matching the expected requirement. In Ivy, if we are about to get the ivy.xml of a module, we are getting the bundle so we already have reached the requirement.
So OSGi capabilities of bundles in a repo will be gathered directly from the manifests passed directly to the Ivy resolver, no need to express them into ivy.xml, except for the Export-Package, see the next section.
Export-Package
Exported packages are declaring capabilities of the bundle in term of packages. But they also declare dependencies between the declared package via the parameter use. These dependencies have to be declared in the ivy.xml. And we will use Ivy module configurations for that.
First, each exported package will be declared in the ivy.xml as a configuration. The name of the configuration will start will use_ and will end with the name of that package.
Then each time an exported package is declared to use some other one, it will be mapped as a dependency between the Ivy configurations corresponding to those packages.
OSGi |
Ivy |
|
|
|
|
OSGi Requirements / Ivy dependencies
In OSGi there are different kinds of dependencies, which in an OSGi bundle repository documentation is called a "requirement". The problem is that Ivy understands only one kind of requirement, so we use here some extra attributes to declare those different kinds of dependencies.
Require-Bundle
The OSGi Require-Bundle is a requirement directly on a specific bundle. To map that, Ivy will just use the osgi="bundle" extra attribute.
If there is the OSGi resolution parameter specified to optional, then the dependency will be declared in the configuration optional and transitive-optional. Otherwise it will be declared in the default configuration.
OSGi |
Ivy |
|
|
|
|
Import-Package
The OSGi Import-Package is a requirement on a package of a bundle. Ivy has no notion of package. So we will use the osgi="pkg" extra attribute.
If there is the OSGi resolution parameter specified to optional, then the dependency will be declared in the configuration optional and transitive-optional. Otherwise it will be declared in the default configuration.
As it is an import package, the configuration of the dependency will be the use_XXX one. This way, the transitive dependency via the use parameter will be respected in the dependency.
OSGi |
Ivy |
|
|
|
|
Execution environment
The OSGi Bundle-RequiredExecutionEnvironment manifest attribute specifies which environment the bundle is expected to run. What that means in terms of dependency management is that some of the transitive dependencies won’t be resolved within the OSGi space but will be provided by the JRE. While mapping this, Ivy will exclude from the dependency tree every requirement that will be provided by the environment.
OSGi |
Ivy |
|
|
Bundle Fragment
Ivy doesn’t support the header Fragment-Host.
The workaround is to manually specify, as dependencies in the ivy.xml, the bundles which would fit to be the extensions of the host bundle.
Building an Eclipse plugin
|
Note
|
Note that this feature is considered as experimental. |
This page describes how to build an Eclipse™ plugin with Apache Ivy™ and its OSGi™ capabilities.
Quick setup
In a few steps, we will set up a build to compile and package an Eclipse plugin.
-
download this ivy.xml, this ivysettings.xml, this ivysettings.properties, this build.xml, and put them into your plugin folder
-
in the
ivysettings.properties, specify the location of the plugins folder of your Eclipse target -
in the
ivy.xml, change the symbolic name declared in the extends element -
(optional) by default the
build.xmlis expecting the sources to be in thesrcfolder. You may want to edit it if it is not the case -
(optional) if Ivy is not in Ant’s classpath, download the Ivy jar and edit the
build.xmlaccordingly (see the comments at the beginning of the file)
And that’s it ! Now let’s use it.
First, Ivy needs to aggregate the OSGi metadata of the target platform. To do so just launch:
ant buildobrYou need to run that command only once. Or each time your target platform get modified.
Then to resolve and build, just run:
ant buildEclipse setup
You probably have already configured your project in Eclipse via the PDE. Let’s see how to change that and use Apache IvyDE:
-
First remove from your project’s classpath the PDE dependencies container
-
then right click on the
ivy.xmlyou just added and select "Add Ivy library" -
in the configuration panel of the
IvyDEclasspath container, as the settings file put${workspace_loc:mypluginproject/ivysettings.xml} -
click finish and your Eclipse project should build now.
|
Note
|
For resolution to work correctly, Ivy relies on the aggregated metadata of your target platform. Even if you want to only build with Eclipse, you will have to run the command ant obrindex at least one time.
|
Details on the setup
The repository
When building an Eclipse plugin, we are relying on a "target platform", the Eclipse installation we want our plugin to be eventually installed into. For Ivy, this will represent the repository of artifacts.
Ivy needs an aggregation of the OSGi metadata in order to resolve a such repository. The Ant task buildobr builds a OBR (OSGi Bundle Repository) descriptor file from a set of OSGi bundles. So here we are using this Ant task to gather OSGi metadata from the Eclipse plugins in the "target platform". In the above example, the file is built in target/repo-eclipse.xml.
The plugin to be built has a ivy.xml file describing its dependencies to be used by Ivy. Since the actual dependencies are in the MANIFEST.MF file, in the ivy.xml file we specify that it extends META-INF/MANIFEST.MF. So there are few dependencies specified in the ivy.xml. But as Ivy doesn’t support the Bundle-Fragment OSGi feature, the ivy.xml can help specify the missing dependencies.
Having this setup, it is then a standard Ant+Ivy build. Ivy computes the classpath to be used by the javac tasks. Note that javac is not aware of the OSGi metadata and is then incapable of failing to compile if private packages are accessed.
Building a standard OSGi bundle
|
Note
|
Note that this feature is considered as experimental. |
TODO - WORK IN PROGRESS
This page describes how to build an OSGi™ bundle with Apache Ivy™. In this use case, we just basically want to compute a classpath to compile, optionally one for testing too, and then publish our bundle in a OSGi aware repository.
In order to produce OSGi metadata of sufficient quality and to avoid maintaining them manually, the bnd tool will be used. The approach taken is then an "Ivy file first" approach. The dependencies will be specified in the ivy.xml file, the MANIFEST.MF being generated from the computed classpath.
Quick setup
In few steps, we will setup a build to compile and publish an OSGi bundle.
-
download this ivy.xml, this ivysettings.xml, this build.xml, this bnd file, and put them into your project folder
-
in the
ivysettings.properties, specify the location of the plugins folder of your Eclipse target -
(optional) by default the
build.xmlis expecting the sources to be in thesrcfolder. You may want to edit it if it is not the case -
(optional) if Ivy is not in Ant’s classpath, download the Ivy jar and edit the
build.xmlaccordingly (see the comments at the beginning of the file)
To build the project, run:
ant buildManaging a target platform
|
Note
|
Note that this feature is considered as experimental. |
The concept of "target platform" is a concept introduced by Eclipse™ to describe the set of bundles which will run together in an OSGi™ environment. Then when developing an OSGi bundle, we expect it to run in such a "target platform".
When developing a single OSGi bundle, a single ivy.xml (together with the use of the fixdeps task) is sufficient to describe precisely the bundle requirements.
But when developing several bundles, it will be error prone to declare for each bundle its dependencies. Because once deployed in an OSGi environment, the bindings are sensitive to the available bundles. So when developing, we must ensure that the set of bundles will be the same set as the one at deploy time.
The concept of "target platform" is a perfect fit to describe the set of bundles to resolve against. Here is a recipe to handle it with just Ant+Ivy.
A Target Platform Project
First you need a project (basically a folder) in which you will manage your target platform. In this project you’ll need 3 files:
-
an ivy.xml in which you will describe the bundles you need
-
an ivysettings.xml which will describe where to download bundles from
-
and a build.xml with which you’ll manage your target platform
In the build there is a target: update-dependencies. This target will do a resolve with the ivy.xml and will generate an ivy-fixed.xml from the resolved dependencies. This ivy-fixed.xml file contains only fixed non transitive dependencies (see the fixdeps task for further info). With that ivy-fixed.xml file, subsequent dependency resolutions are then reproducible and will always generate the same set of artifacts.
Once generated, it is recommended to share that ivy-fixed.xml file into your version control system (Git, Subversion, etc…). The target update-dependencies must then be launched each time you edit the ivy.xml, when you want to change the content of your target platform.
The second target generate-target-platform will generate an obr.xml, a OSGi Bundle repository descriptor. This file will list every artifact which has been resolved by the ivy-fixed.xml. Then each of your bundles you develop will do its resolve against that obr.xml (see the obr resolver).
The generated obr.xml contains paths to the local filesystem, so it is neither recommended to share it between developers nor commit it to version control system.
If it is required to develop your plugin with the Eclipse PDE plugin, you can then use the alternative target generate-retrieved-target-platform. It has the same principle as the generate-target-platform but the artifacts are also retrieved in a single folder, just like the plugins in an Eclipse install. That way you can define your target platform within Eclipse quite easily.
Apache Felix Sigil
A different approach
Apache Felix Sigil is at its core about managing OSGi dependencies, not directly related to Ivy. Most of its core feature is about the implementation of the not yet released OBR (OSGi Bundle Repository) specification. It then provides integration layers with several tools so that developers can use the OBR API. It provides an Eclipse plugin and there are the Ant/Ivy tasks and resolvers.
On the other hand the built-in OSGi capabilities in Ivy are targeted towards users already familiar with Ivy and tools around it like Apache IvyDE™. So with a minimum amount of effort, they can get OSGi dependency management.
Resulting differences
Resolve
The built-in OSGi resolver is obviously using the Ivy engine to do the resolution of the dependencies. The OSGi capability of Ivy is mainly implemented with a module descriptor parser which understands the OSGi metadata of a MANIFEST.MF.
On the other hand, Sigil is using a separate "engine" to do the resolution, the OBR, an engine which is dedicated to understand the OSGi metadata and their semantics.
The immediate consequence of this difference is that the built-in resolver is probably less accurate than the Sigil one when it comes to understanding the OSGi dependencies semantics. As explained in this page, the OSGi model doesn’t fit well into the Ivy one.
Source of metadata
Apache Felix Sigil has its own format for specifying the OSGi dependencies. Whereas Ivy requires an ivysettings.xml and an ivy.xml, Sigil requires a sigil-repos.properties and a sigil.properties. Then if you want to use the Sigil resolver in Ivy, you will need 4 files, the 2 Ivy ones and the 2 Sigil ones, as described in the Sigil quickstart here.
To support OSGi directly in Ivy, you just need to add an extra namespace in the ivy.xml, and in the ivysettings.xml just declare the proper resolver and latest revision strategy.
Building from source
To build Ivy from source it’s really easy.
Requirements
All you need is
-
a Git client
to check out Ivy sources from Apache Git, not required if you build from sources packaged in a release -
Apache Ant 1.9.0 or greater
We recommend the latest version of Ant -
a JDK 7 or greater
Build instructions have been successfully tested with Oracle JDK 7 and 8
Procedure
Get the source
You can either get the sources from a release, or get them directly from Git:
git clone git://git.apache.org/ant-ivy.gitBuild
Go to the directory where you get the Ivy sources (you should see a file named build.xml) and run:
antCheck the result
The Ant build will compile the core classes of Ivy and use them to resolve the dependencies (used for some optional features). Then it will compile and run tests with coverage metrics.
If everything goes well, you should see the message:
BUILD SUCCESSFULThen you can check the test results in the build/doc/reports/test directory, the jars are in build/artifacts, and the test coverage report in build/doc/reports/coverage
Coding conventions
The Ivy code base is supposed to follow Java Code Conventions: http://www.oracle.com/technetwork/java/javase/documentation/codeconvtoc-136057.html
This is a work in progress though (see IVY-511), but patches helping migration to these conventions are welcome.
Developing with Eclipse
Even though you can develop Ivy with your IDE of choice, we support Eclipse development by providing ad hoc metadata.
We currently provide two options:
Eclipse alone
To develop with a simple Eclipse install all you need is Eclipse 4.2 or greater, with no particular plugin. First call the following Ant target in your Ivy workspace:
ant eclipse-defaultThis will resolve the dependencies of Ivy and produce a .classpath using the resolved jars for the build path. Then you can use the "Import→Existing project into workspace" eclipse feature to import the Ivy project in your workspace.
Eclipse + IvyDE
You can also leverage the latest IvyDE version to be able to easily resolve the Ivy dependencies from Eclipse. To do so all you need is call the following Ant target in your Ivy workspace:
ant eclipse-ivydeor if you don’t have Ant installed you can simply copy the file .classpath.ivyde and rename it to .classpath
Then you can import the project using "Import→Existing project into workspace" as long as you already have latest IvyDE installed.
To install latest IvyDE version compatible with the latest Ivy used to resolve Ivy dependencies, you will need to use a snapshot build, not endorsed by the ASF, available here: https://builds.apache.org/view/A/view/Ant/job/IvyDE/
Download the file and unzip its content in your Eclipse installation directory.
Recommended plugins
The Ivy project comes with settings for the Checkstyle plugin we recommend to use to avoid introducing a new digression to the Checkstyle rules we use. If you use this plugin, you will see many errors in Ivy. As we said, following strict Checkstyle rules is a work in progress and we used to have pretty different code conventions (like using _ as prefix for private attributes), so we still have things to fix. We usually use the filter in the problems view to filter out Checkstyle errors from this view, which helps to know what the real compilation problem are.
Besides this plugin we also recommend to use a Git plugin, EGit.
Extending Ivy
Many things are configurable in Ivy, and many things are available with Ivy core. But when you want to do something not built in Ivy core, you can still plug your own code.
Many things are pluggable in Ivy:
-
module descriptor parsers
-
dependency resolvers
-
lock strategies
-
latest strategies
-
circular dependency strategies
-
conflict managers
-
report outputters
-
version matchers
-
triggers
Before trying to implement your own, we encourage you to check if the solution to your problem can be addressed by existing features, or by contributed ones. Do not hesitate to ask for help on the mailing-lists.
If you still don’t find what you need, then you’ll have to develop your own plugin or find someone who could do that for you.
All Ivy plug-ins use the same code patterns as Ant specific tasks for parameters. This means that if you want to have a myattribute of type String, you just have to declare a method called setMyattribute(String val) on your plug-in. The same applies to child tags, you just have to follow Ant specifications.
All pluggable code in Ivy is located in the org.apache.ivy.plugins package. In each package you will find an interface that you must implement to provide a new plugin. We usually also provide an abstract class easing the implementation and making your code more independent of interface changes. We heavily recommend using these abstract classes as a base class.
To understand how your implementation can be done, we suggest looking at existing implementations we provide, it’s the best way to get started.
Making a release
Requirements
Requirements for making a release are similar to the requirements for building from source, except that Apache Ant 1.9+ is required.
Procedure
1. Check the files which needs to be updated for the release.
On the master, check that files which require update for the release are up to date.
This includes particularly:
asciidoc/release-notes.adoc
2. Check out a clean copy of the branch
Run the following git command to checkout the branch, revert any change and remove untracked and ignored files:
git checkout master
git reset --hard
git clean -d -x -f3. Add Ivy xsd file.
You need to store the current Ivy XML schema in the documentation, so that it will later be accessible on public web site. To do so, run the following command in the directory in which you checked out the release branch:
ant -f build-release.xml release-xsdAnd commit your changes in the branch:
git add asciidoc/ivy.xsd
git commit -m "release the ivy.xsd"4. Launch the release script
ant -f build-release.xml releaseThe status should be release only for final releases, and milestone for any other intermediate release. If the release script is successful, release artifacts will be waiting for you in the build/distrib directory.
5. Verify the release
Check that all zips can be opened correctly, and that running ant after unzipping the source distribution works properly.
You can also do a smoke test with the generated ivy.jar, to see if it is able to resolve properly a basic module (for instance, you can run some tutorials provided in the src/example directory in all distributions).
6. Sign the artifacts
It’s now time to sign the release artifacts and upload them to a location accessible by other Apache committers.
Here is a simple way to sign the files using gnupg:
gpg --armor --output file.zip.asc --detach-sig file.zipHere is a ruby script you can use to sign the files:
require 'find'
Find.find('build/distrib') do |f|
`gpg --armor --output #{f}.asc --detach-sig #{f}` if File.file?(f) && ['.zip', '.gz', '.jar', '.pom'].include?(File.extname(f))
endBe prepared to enter your passphrase several times if you use this script, gpg will ask for your passphrase for each file to sign.
7. Prepare the Eclipse update site
To be able to test the release within IvyDE, it can be deployed in the IvyDE update site. See that page to know how to process.
8. Publish the release candidate
All artifacts in build/distrib/dist needs to be published on the 'dist' svn of the ASF, in the dev part.
The following command lines should do the job:
|
Note
|
Make sure to use the right version number in the commit message. |
svn checkout -N https://dist.apache.org/repos/dist/dev/ant/ivy build/distrib/dist
svn add build/distrib/dist/*
svn commit build/distrib/dist -m 'Ivy 2.4.0 distribution'9. Publish the Maven artifact to Nexus
Having your GPG key ID, its password, your apache ID and the associated password, just launch Ant and enter the information as required:
ant -f build-release.xml upload-nexusOnce uploaded, log in https://repository.apache.org/ with your preferred web browser (use your Apache ID).
You should find there an open repository with the name of the form orgapacheant-XXXX. It should contain the Maven artifacts: the pom, the jar, the sources, the javadocs and the sha and asc files.
Now close the staging repository, with the description "Ivy 2.0.0-beta1". Closing means you finished the upload and some automatic checks will run. You can see them in the Activity tab of the repository.
Once the checks passed, you can find in the Summary the URL of the staging repository. It will something like: https://repository.apache.org/content/repositories/orgapacheant-XXXX/
10. Create a signed tag
As soon as you are happy with the artifacts to be released, it is time to tag the release
|
Note
|
Use the right version number for the tag. For example, if you released 2.5.0 of Ivy, then the tag name should be 2.5.0 |
git tag -s 2.0.0-beta1 -m 'Release Ivy 2.0.0-beta1'And push the changes to the ASF repo
git push --tags11. Call for a vote to approve the release
Cast a vote to approve the release on the dev@ant.apache.org mailing list.
Here is an example:
Subject: [VOTE] Ivy ${version} Release
I have built a release candidate for Ivy ${version}
The git tag of this release is: https://gitbox.apache.org/repos/asf?p=ant-ivy.git;a=tag;h=refs/tags/${version} with the sha1 ${githash-of-tag}
The artifacts has been published to: https://dist.apache.org/repos/dist/dev/ant/ivy/${version} at revision ${svn-rev-of-the-check-in}
The staging Maven repository is available there: https://repository.apache.org/content/repositories/orgapacheant-XXXX
The Eclipse updatesite has been build there: https://dist.apache.org/repos/dist/dev/ant/ivyde/updatesite/ivy-${version}/
Do you vote for the release of these binaries?
[ ] Yes
[ ] No
Regards,
${me}, Ivy ${version} release manager12. Publish the release
If the release is approved, it’s now time to make it public. The artifacts in the dev part needs to be moved into the release one:
svn mv https://dist.apache.org/repos/dist/dev/ant/ivy/$VERSION https://dist.apache.org/repos/dist/release/ant/ivy/$VERSIONIn order to keep the main dist area of a reasonable size, old releases should be removed. They will disappear from the main dist but will still be available via the archive. To do so, just use the svn rm command against the artifacts or folders to remove.
13. Promote the Maven staging repository
Go log in https://repository.apache.org/ with your preferred web browser (use your Apache ID).
Select the appropriate orgapacheant-XXXX repository and select the Release action.
14. Update the web site
It’s time to update the download image used on the home page and the download page. Use site/images/ivy-dl.xcf as a basis if you have gimp installed. Then you can update the home page to refer to this image, and add a news item announcing the new version. Update also the download page with the new image and update the links to the download location (using a search/replace on the html source is recommended for this).
The just release documentation should be added to the site. To do so, you need to:
-
edit the toc.json file in the site component of Ivy and add a piece of json with a title and an url; note that the version in the url must be the same as the tag in the git repo.
{ "title":"2.0.0-beta1", "url":"http://ant.apache.org/ivy/history/2.0.0-beta1/index.html" } -
from the distribution just released, install the doc into the site
ant install-doc -Dhistory.version=2.5.0-rc1 -Divy-dist.zip.url=https://dist.apache.org/repos/dist/release/ant/ivy/2.5.0-rc1/apache-ivy-2.5.0-rc1-bin.zip
Now let’s generate the website with the new toc:
ant /all generate-siteYou should verify that the site generated in the production directory is OK. You can open the files with your preferred web browser like it was deployed.
And once your happy with it, commit the changes in the source directory, and in the production directory to get it actually deployed via svnpubsub.
Tip: lot’s of files might need to be 'added' to svn. An handy command to add any file which is not yet under version control is the following one:
svn add --force sources15. Deploy the Eclipse updatesite
If the Eclipse update site has already been prepared to include that new Ivy release, it is now needed to be deployed. Then follow the deployment instruction on that page.
16. Announce
Announce the release on the dev@ant.apache.org, ivy-user@ant.apache.org, user@ant.apache.org and announce@apache.org mailing lists. Note that announce@apache.org only accepts emails sent with an @apache.org address.
Suggested template:
Subject: [Announce] Release of Apache Ivy ${version}
The Apache Ivy project is pleased to announce its ${version} release.
Apache Ivy is a tool for managing (recording, tracking, resolving and
reporting) project dependencies, characterized by flexibility,
configurability, and tight integration with Apache Ant.
Key features of this ${version} release are:
XXXX INCLUDE THE PARAGRAPH FROM THE RELEASE NOTES XXXX
XXXX SUGGESTED PARAGRAPH FOR RC
As a release candidate version, we strongly encourage the use of this version for
testing and validation. From now on, features are frozen until final ${version} version,
only bug fixes will be applied before ${version}. If no outstanding bugs are reported
with this release candidate, it will promoted to ${version} about three weeks after this
release candidate.
Issues should be reported to:
https://issues.apache.org/jira/browse/IVY
Download the release at:
https://ant.apache.org/ivy/download.cgi
More information can be found on the Ivy website:
https://ant.apache.org/ivy/
Regards,
${me}17. Update this doc
If you feel like anything is missing or misleading in this release doc, update it as soon as you encounter the problem.
18. Merge your modifications back to the master if necessary.
Modifications on the template files do not need to be merged, but if you had troubles during your release you may want to merge your fixes back to the trunk.
19. Prepare next release
In the master branch, update the file version.properties with the version of the next release so that anyone building from the trunk will obtain jar with the correct version number.
If the version just release is a final one (not an alpha, beta or rc), the list of changes should be emptied in doc/release-notes.html, and update there the next expected version. The announcement in the file should also be changed accordingly to the next expected version.
Release the version in jira, and create a new unreleased version for the next planned version.